All documentation links
ProActive Workflows & Scheduling (PWS)
-
PWS User Guide
(Workflows, Workload automation, Jobs, Tasks, Catalog, Resource Management, Big Data/ETL, …) PWS Modules
Job Planner
(Time-based Scheduling)Event Orchestration
(Event-based Scheduling)Service Automation
(PaaS On-Demand, Service deployment and management)
PWS Admin Guide
(Installation, Infrastructure & Nodes setup, Agents,…)
ProActive AI Orchestration (PAIO)
PAIO User Guide
(a complete Data Science and Machine Learning platform, with Studio & MLOps)
1. Overview
ProActive Scheduler is a comprehensive Open Source job scheduler and Orchestrator, also featuring Workflows and Resource Management. The user specifies the computation in terms of a series of computation steps along with their execution and data dependencies. The Scheduler executes this computation on a cluster of computation resources, each step on the best-fit resource and in parallel wherever its possible.
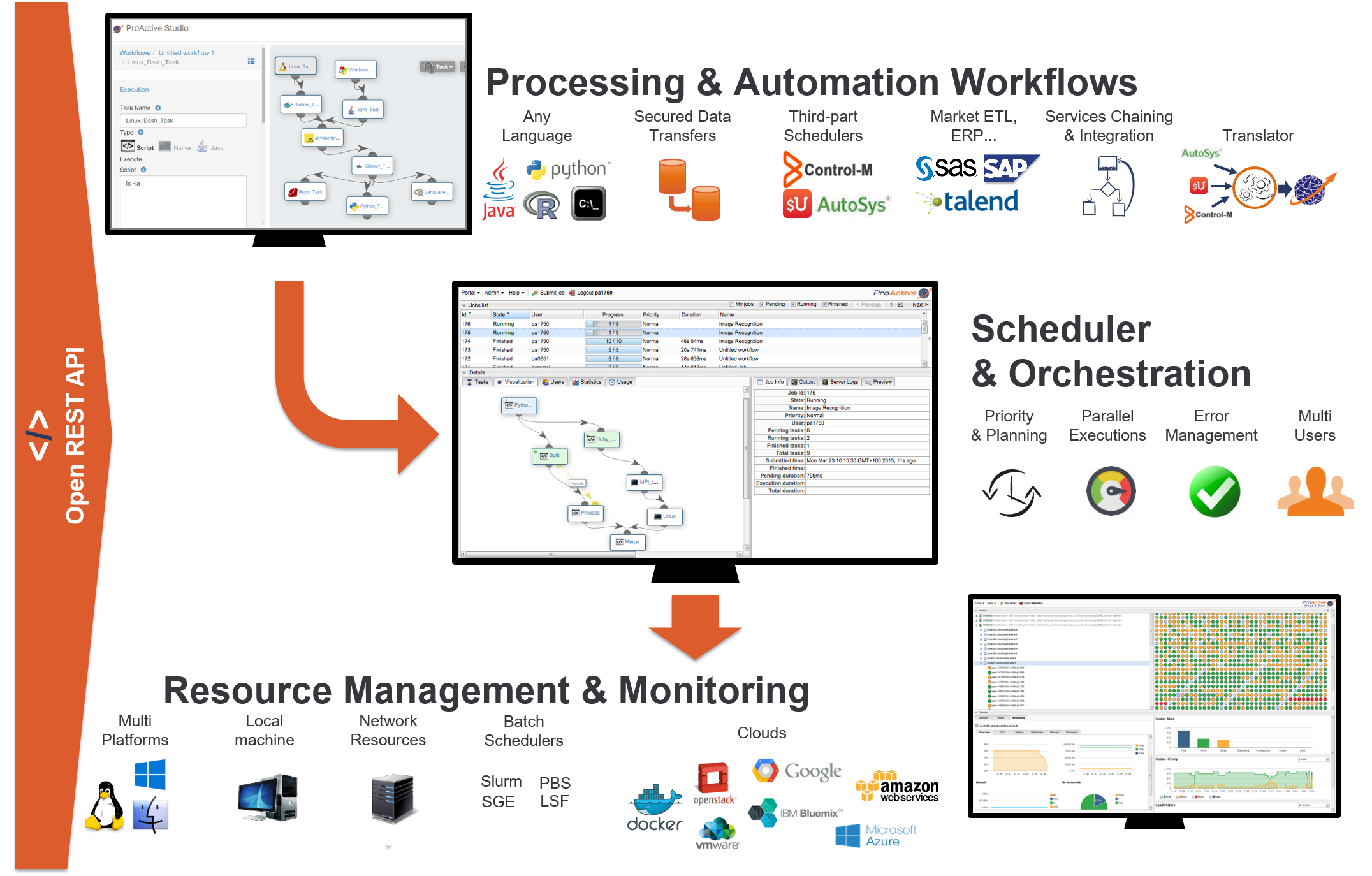
On the top left there is the Studio interface which allows you to build Workflows. It can be interactively configured to address specific domains, for instance Finance, Big Data, IoT, Artificial Intelligence (AI). See for instance the Documentation of ProActive AI Orchestration here, and try it online here. In the middle there is the Scheduler which enables an enterprise to orchestrate and automate Multi-users, Multi-application Jobs. Finally, at the bottom right is the Resource manager interface which manages and automates resource provisioning on any Public Cloud, on any virtualization software, on any container system, and on any Physical Machine of any OS. All the components you see come with fully Open and modern REST APIs.
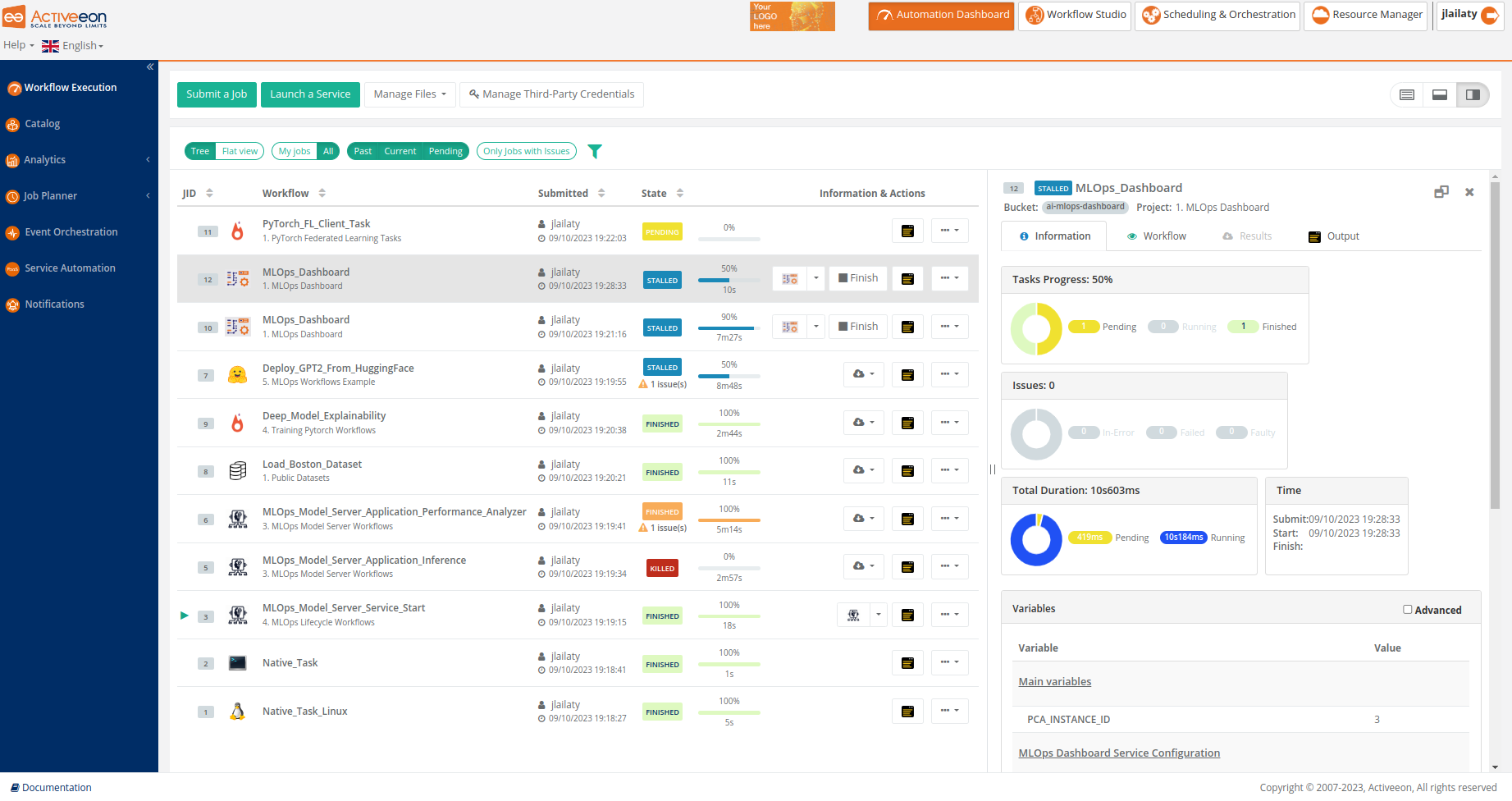
The screenshot above shows the Workflow Execution Portal, which is the main portal of ProActive Workflows & Scheduling and the entry point for end-users to submit workflows manually, monitor their executions and access job outputs, results, services endpoints, etc.
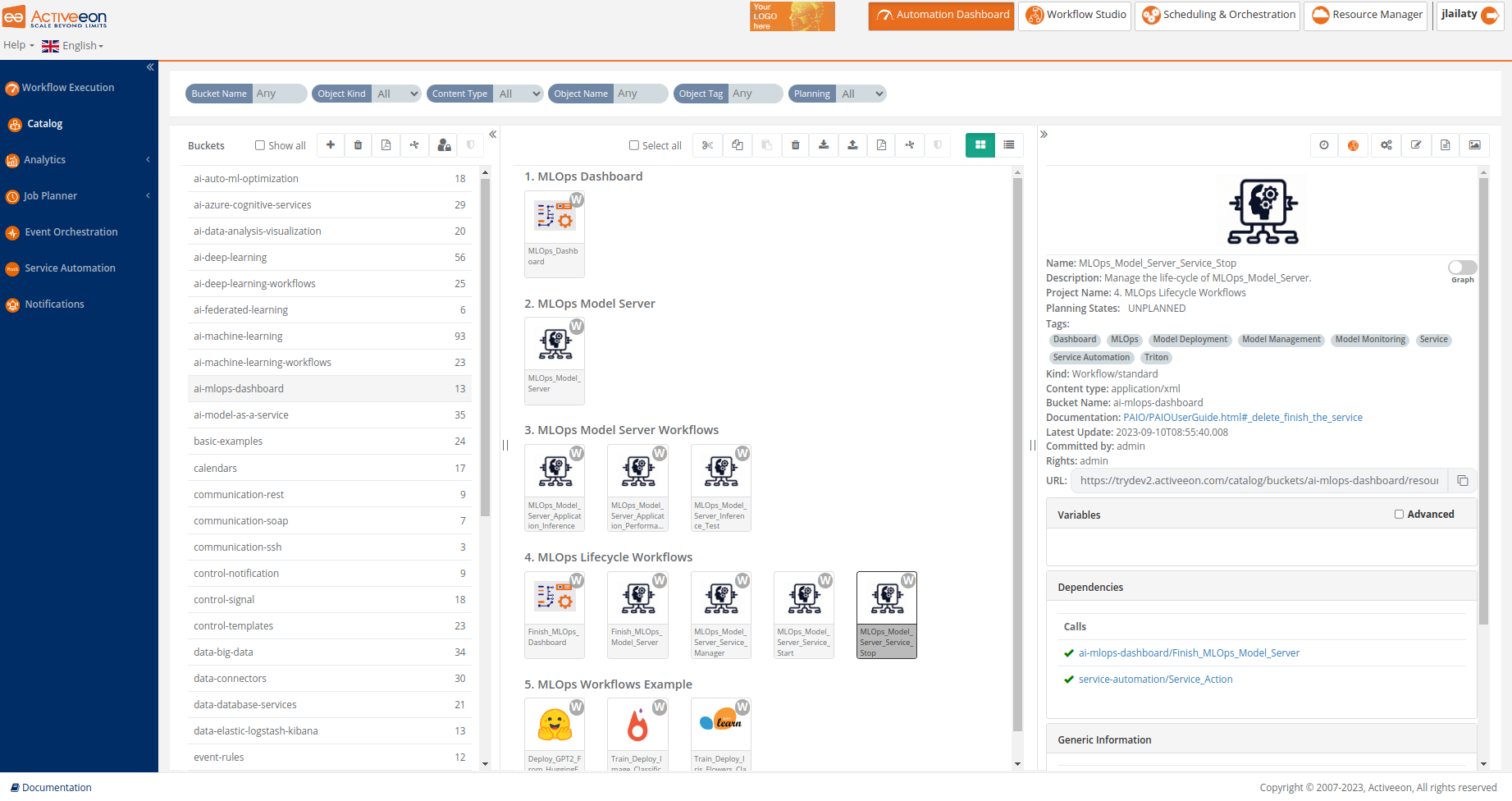
The screenshot above shows the Catalog Portal, where one can store Workflows, Calendars, Scripts, etc. Powerful versioning together with full access control (RBAC) is supported, and users can share easily Workflows and templates between teams, and various environments (Dev, Test, Staging and Prod).
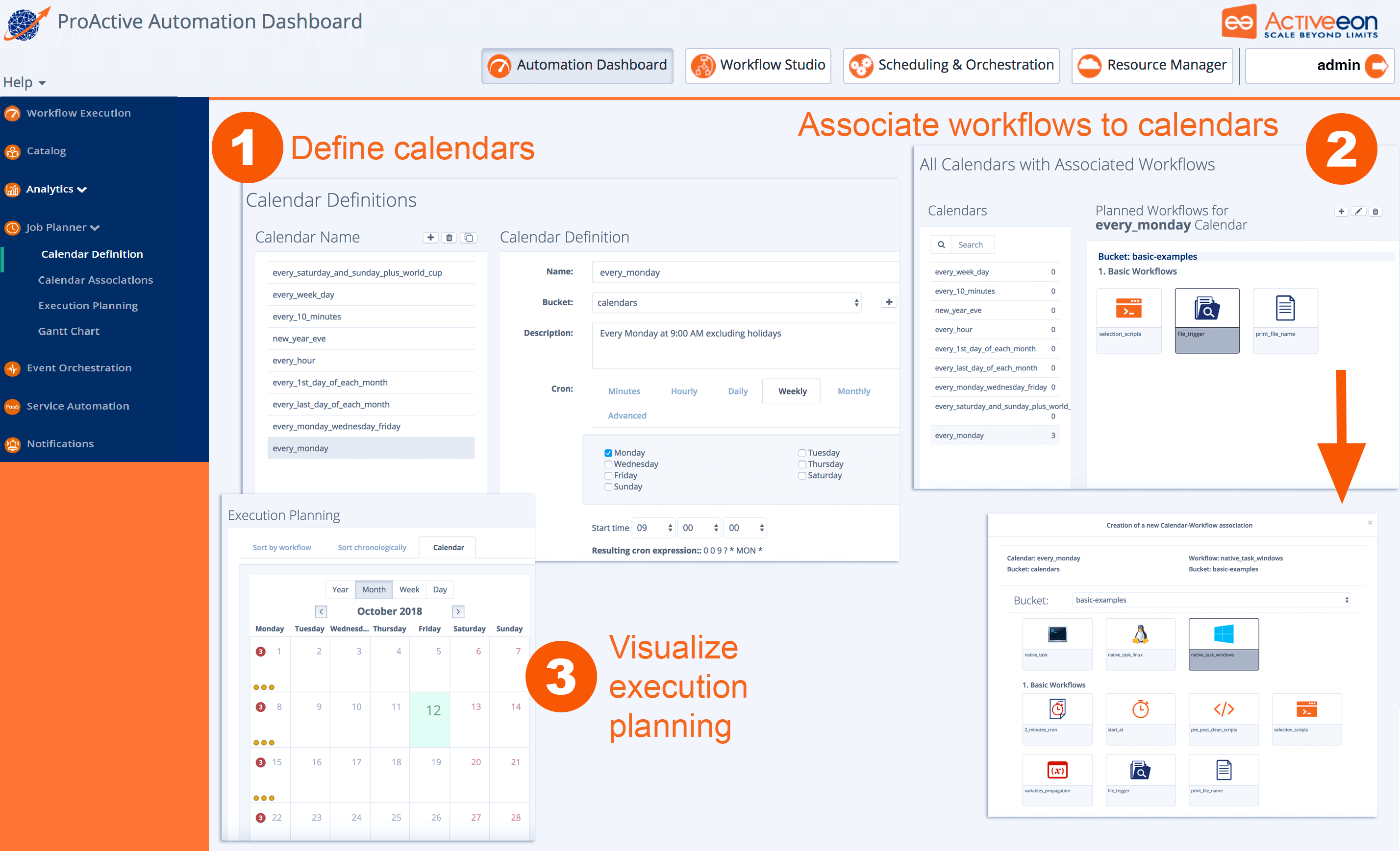
The screenshot above shows the Job Planner Portal, allowing to automate and schedule recurring Jobs. From left to right, you can define and use Calendar Definitions , associate Workflows to calendars, visualize the execution planning for the future, as well as actual executions of the past.
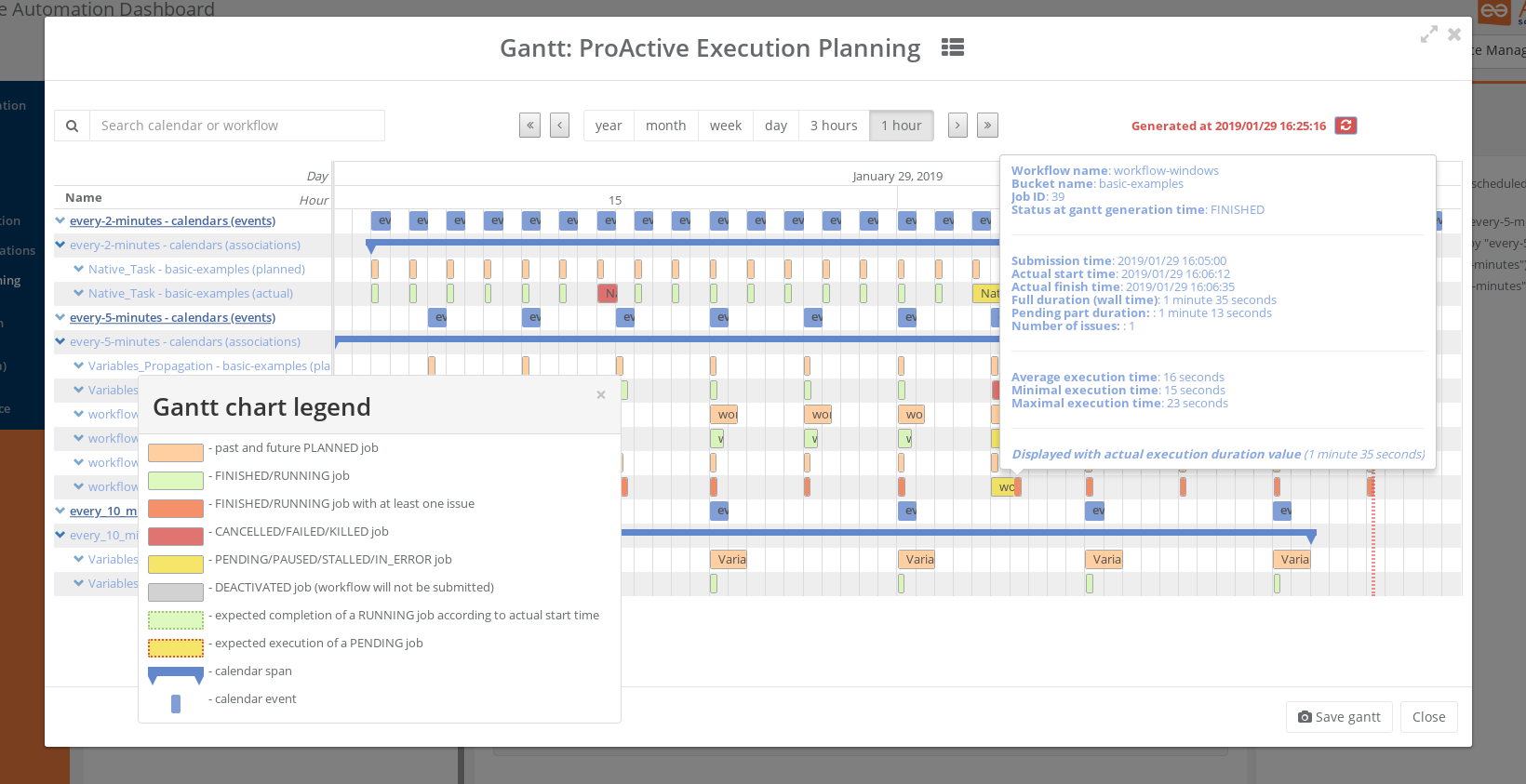
The Gantt screenshot above shows the Gantt View of Job Planner, featuring past job history, current Job being executed, and future Jobs that will be submitted, all in a comprehensive interactive view. You easily see the potential differences between Planned Submission Time and Actual Start Time of the Jobs, get estimations of the Finished Time, visualize the Job that stayed PENDING for some time (in Yellow) and the Jobs that had issues and got KILLED, CANCELLED, or FAILED (in red).
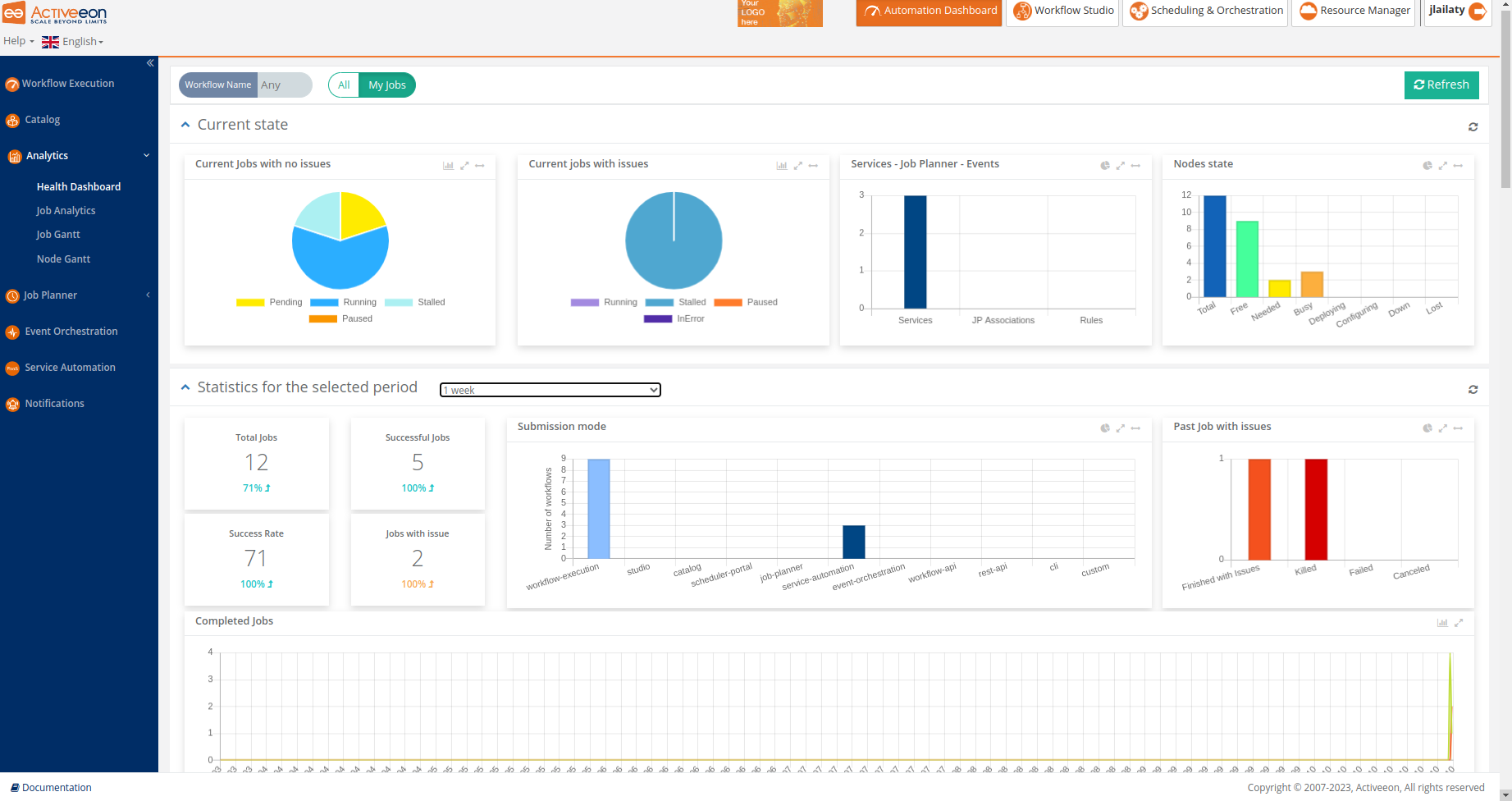
The screenshots above show the Health Dashboard Portal, which is a part of the Analytics service, that displays global statistics and current state of the ProActive server. Using this portal, users can monitor the status of critical resources, detect issues, and take proactive measures to ensure the efficient operation of workflows and services.
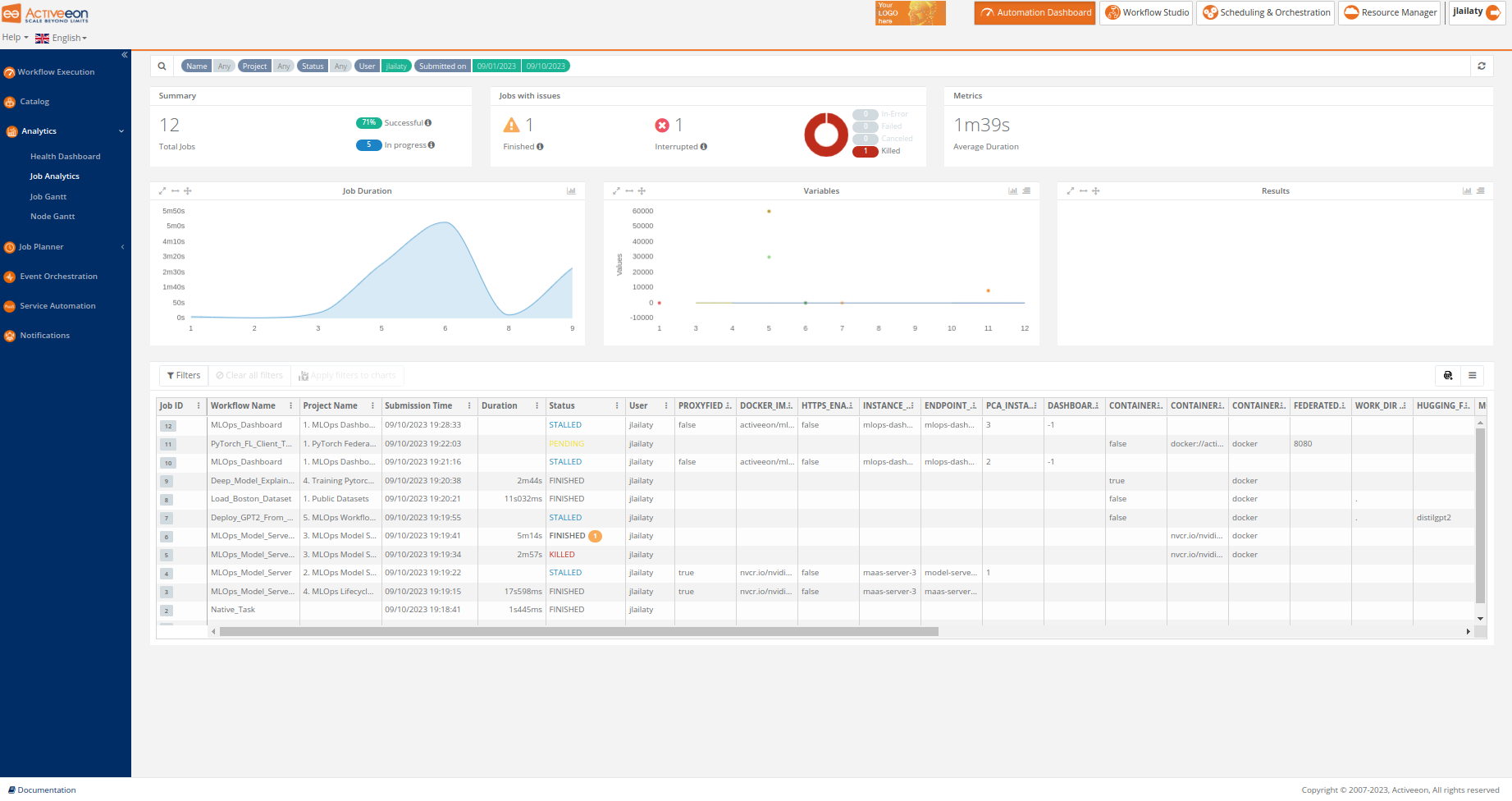
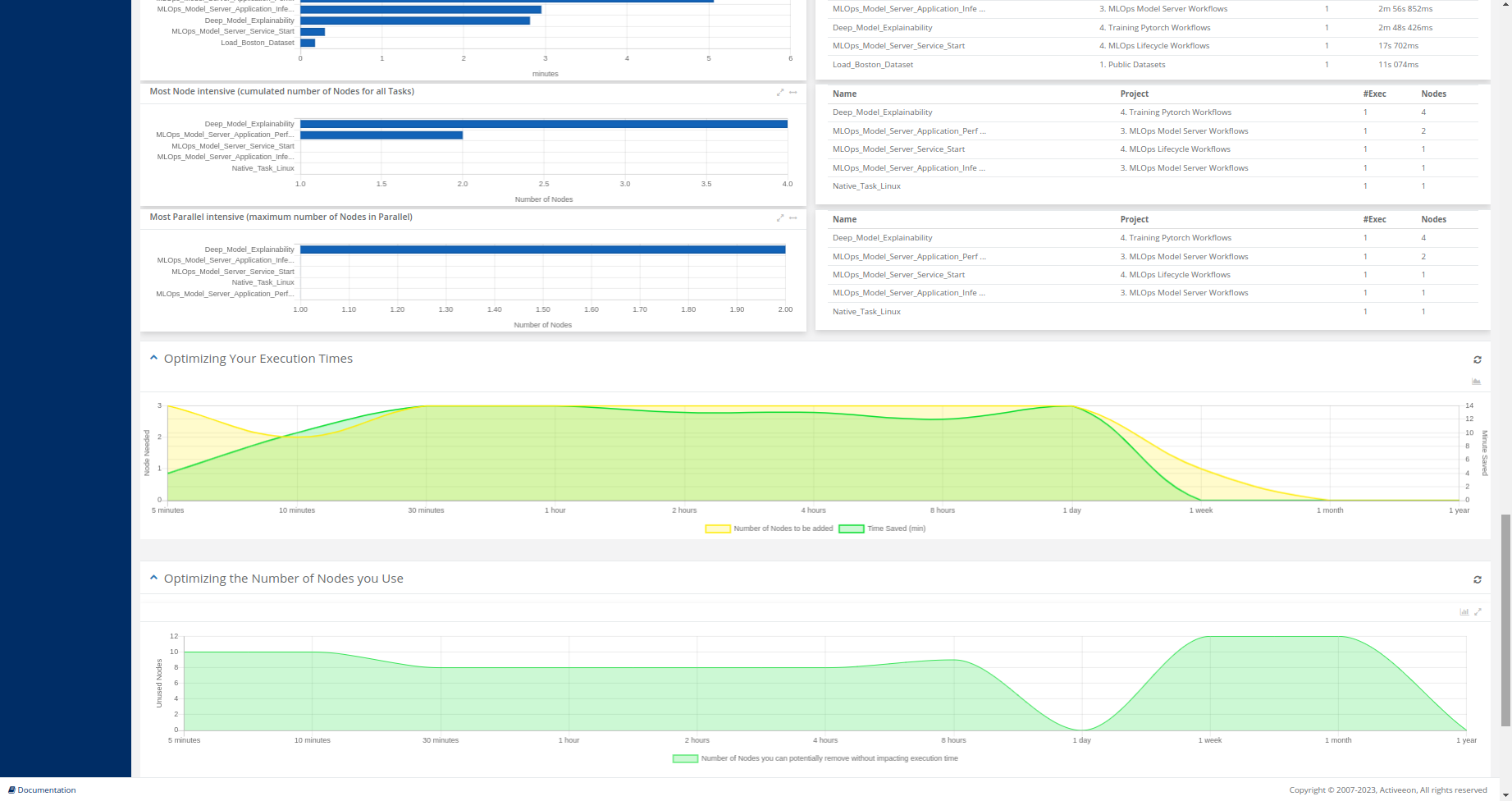
The screenshot above shows the Job Analytics Portal, which is a ProActive component, part of the Analytics service, that provides an overview of executed workflows along with their input variables and results.
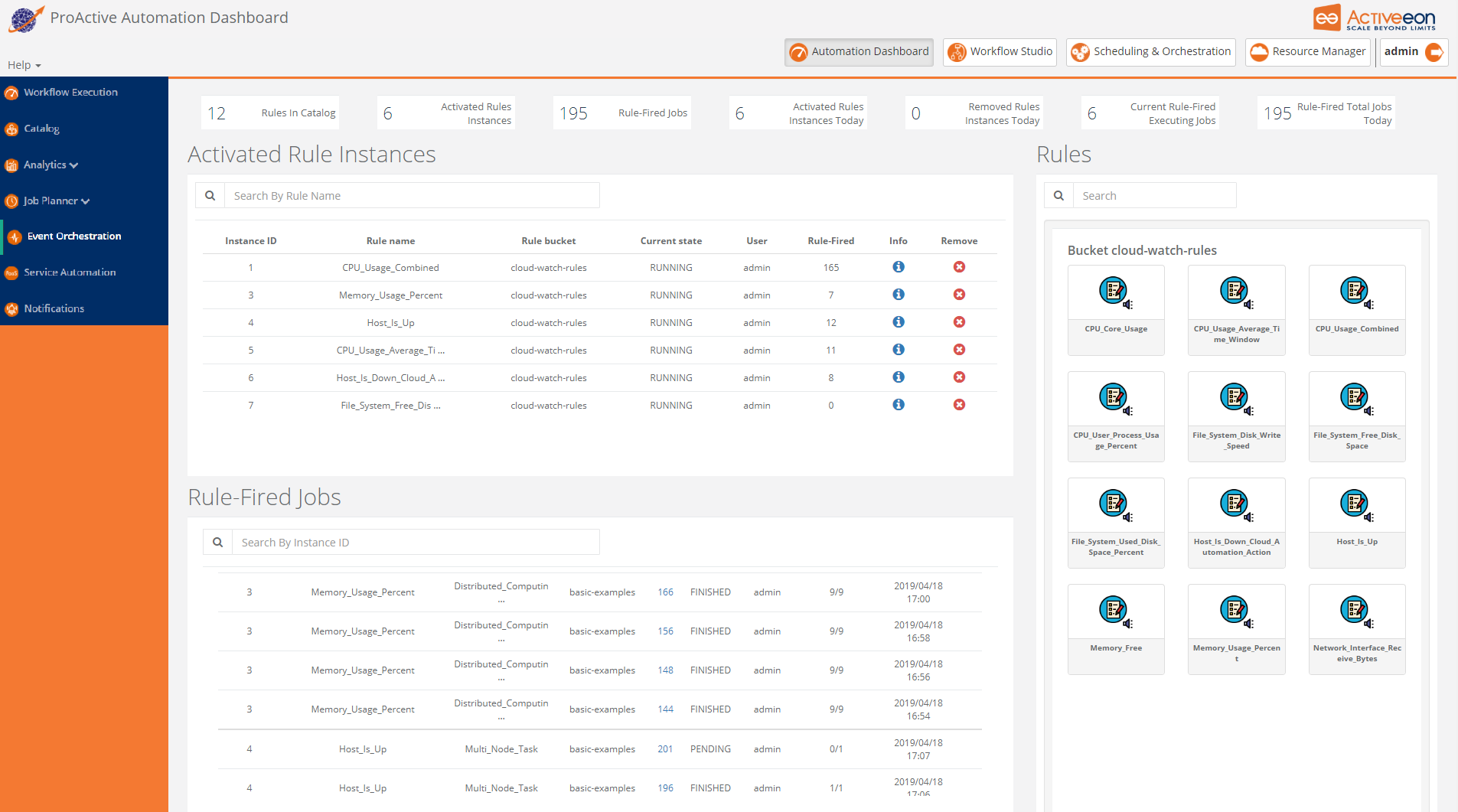
The screenshot above shows the Event Orchestration Portal, where a user can manage and benefit from Event Orchestration - smart monitoring system. This ProActive component detects complex events and then triggers user-specified actions according to predefined set of rules.
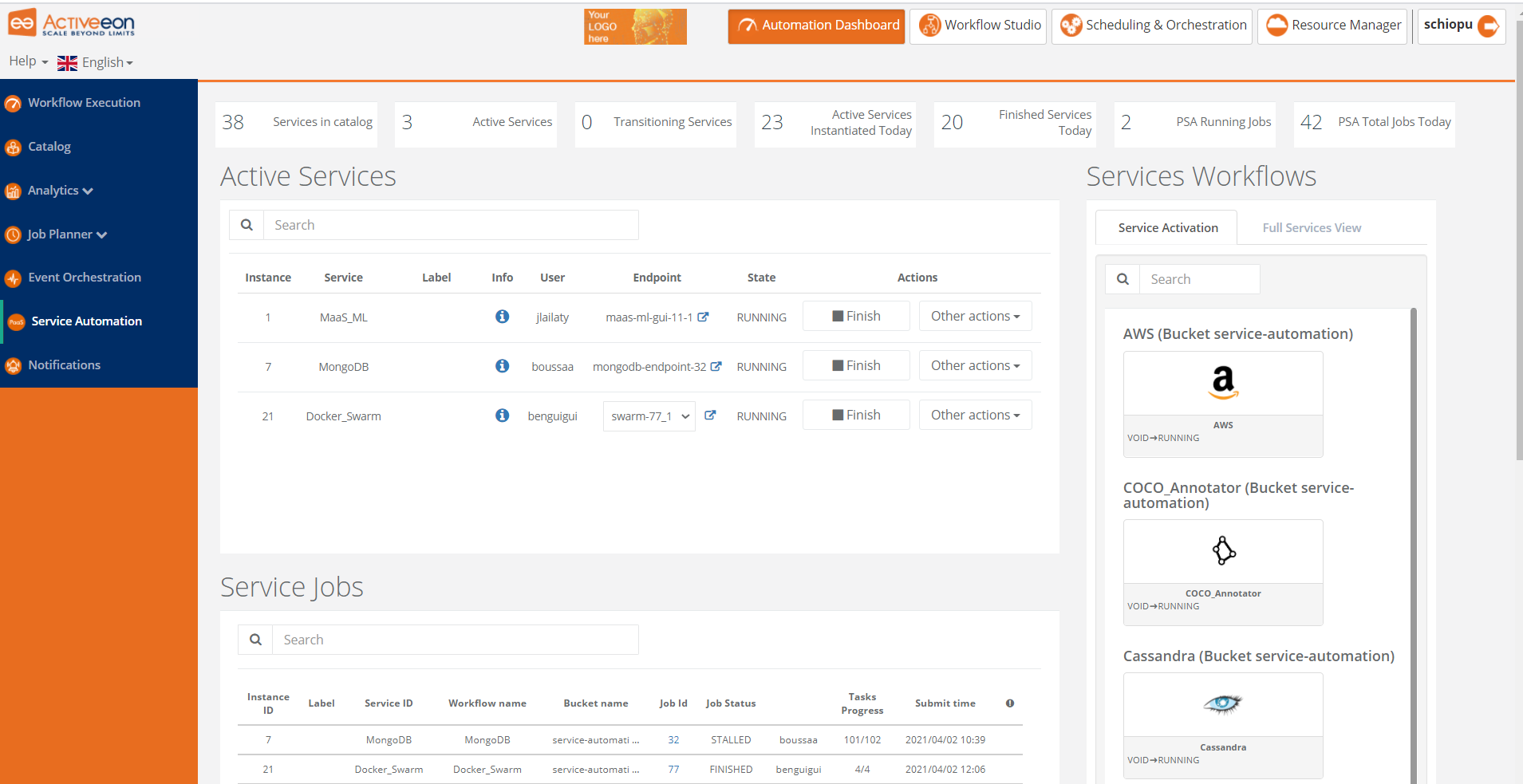
The screenshot above shows the Service Automation Portal which is actually a PaaS automation tool. It allows you to easily manage any On-Demand Services with full Life-Cycle Management (create, deploy, suspend, resume and terminate).
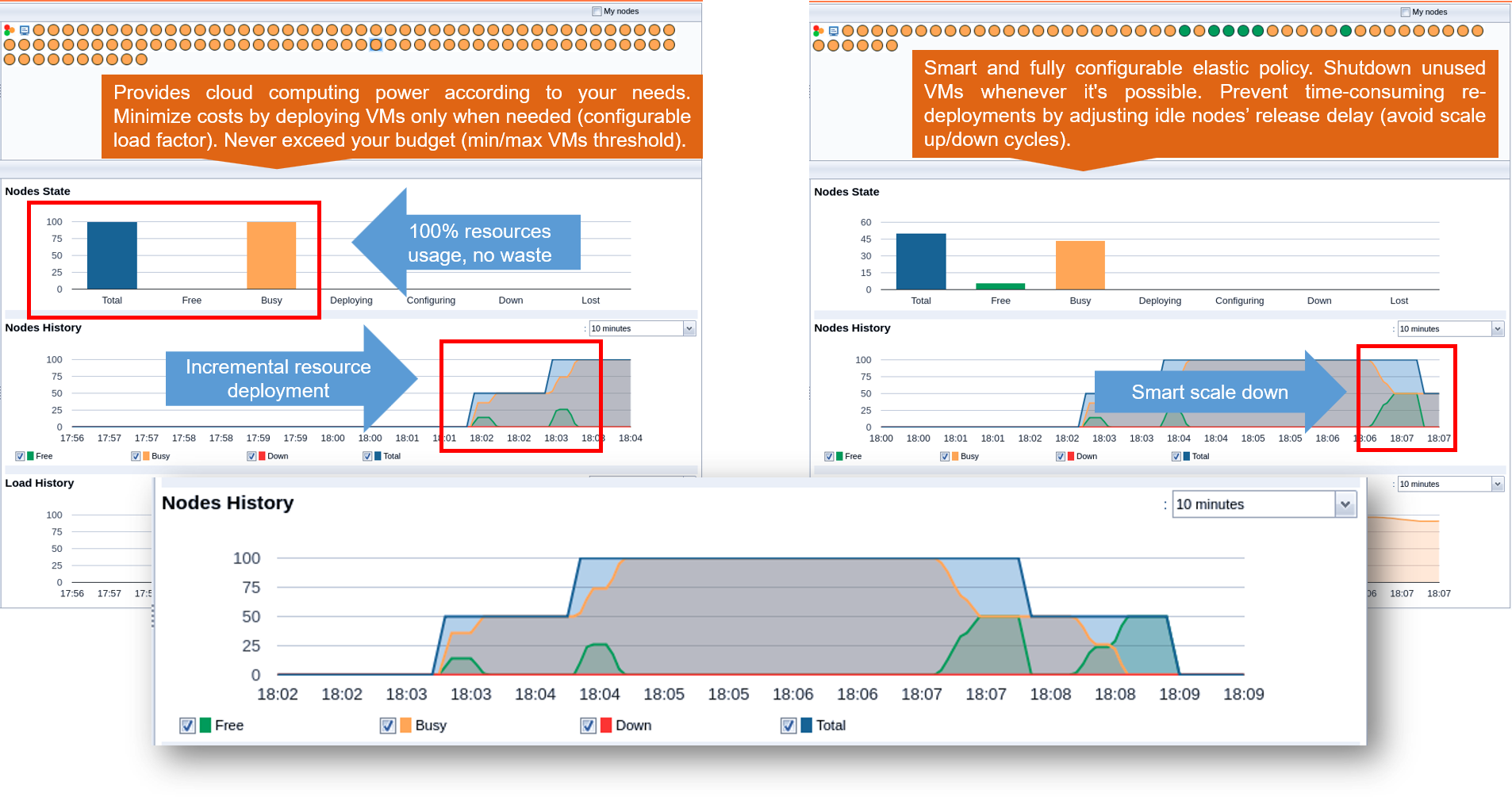
The screenshots above taken from the Resource Manager Portal shows that you can configure ProActive Scheduler to dynamically scale up and down the infrastructure being used (e.g. the number of VMs you buy on Clouds) according to the actual workload to execute.
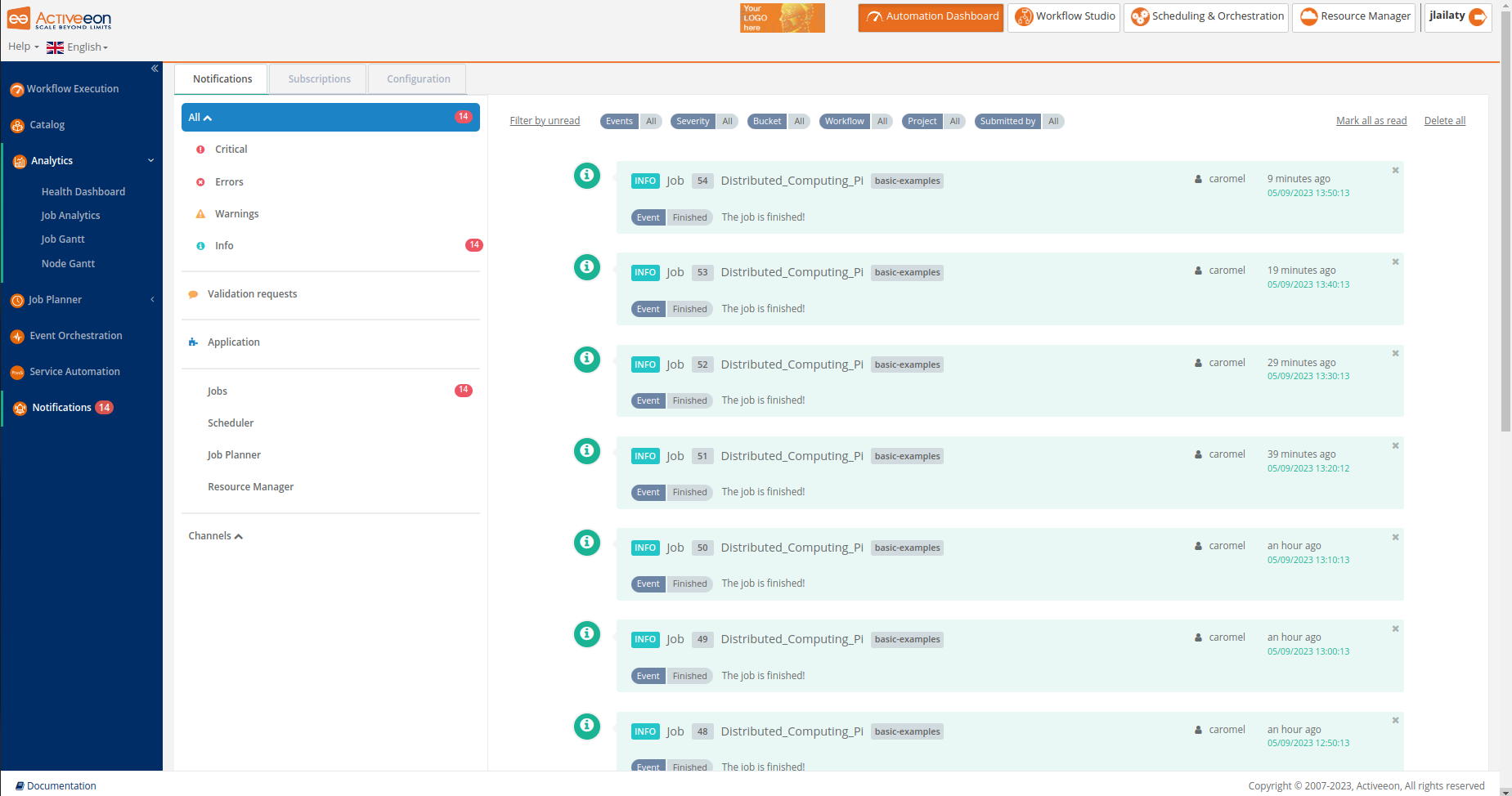
The screenshot above shows the Notifications Portal, which is a ProActive component that allows a user or a group of users to subscribe to different types of notifications (web, email, sms or a third-party notification) when certain event(s) occur (e.g., job In-Error state, job in Finished state, scheduler in Paused state, etc.).
1.1. Glossary
The following terms are used throughout the documentation:
- ProActive Workflows & Scheduling
-
The full distribution of ProActive for Workflows & Scheduling, it contains the ProActive Scheduler server, the REST & Web interfaces, the command line tools. It is the commercial product name.
- ProActive Scheduler
-
Can refer to any of the following:
-
A complete set of ProActive components.
-
An archive that contains a released version of ProActive components, for example
activeeon_enterprise-pca_server-OS-ARCH-VERSION.zip. -
A set of server-side ProActive components installed and running on a Server Host.
-
- Resource Manager
-
ProActive component that manages ProActive Nodes running on Compute Hosts.
- Scheduler
-
ProActive component that accepts Jobs from users, orders the constituent Tasks according to priority and resource availability, and eventually executes them on the resources (ProActive Nodes) provided by the Resource Manager.
| Please note the difference between Scheduler and ProActive Scheduler. |
- REST API
-
ProActive component that provides RESTful API for the Resource Manager, the Scheduler and the Catalog.
- Resource Manager Portal
-
ProActive component that provides a web interface to the Resource Manager. Also called Resource Manager portal.
- Scheduler Portal
-
ProActive component that provides a web interface to the Scheduler. Also called Scheduler portal.
- Workflow Studio
-
ProActive component that provides a web interface for designing Workflows.
- Automation Dashboard
-
Centralized interface for the following web portals: Workflow Execution, Catalog, Analytics, Job Planner, Service Automation, Event Orchestration and Notifications.
- Analytics
-
Web interface and ProActive component, responsible to gather monitoring information for ProActive Scheduler, Jobs and ProActive Nodes
- Job Analytics
-
ProActive component, part of the Analytics service, that provides an overview of executed workflows along with their input variables and results.
- Node Gantt
-
ProActive component, part of the Analytics service, that provides an overview of ProActive Nodes usage over time.
- Health Dashboard
-
Web interface, part of the Analytics service, that displays global statistics and current state of the ProActive server.
- Job Analytics portal
-
Web interface of the Analytics component.
- Notification Service
-
ProActive component that allows a user or a group of users to subscribe to different types of notifications (web, email, sms or a third-party notification) when certain event(s) occur (e.g., job In-Error state, job in Finished state, scheduler in Paused state, etc.).
- Notification portal
-
Web interface to visualize notifications generated by the Notification Service and manage subscriptions.
- Notification Subscription
-
In Notification Service, a subscription is a per-user configuration to receive notifications for a particular type of events.
- Third Party Notification
-
A Notification Method which executes a script when the notification is triggered.
- Notification Method
-
Element of a Notification Subscription which defines how a user is notified (portal, email, third-party, etc.).
- Notification Channel
-
In the Notification Service, a channel is a notification container that can be notified and displays notifications to groups of users
- Service Automation
-
ProActive component that allows a user to easily manage any On-Demand Services (PaaS, IaaS and MaaS) with full Life-Cycle Management (create, deploy, pause, resume and terminate).
- Service Automation portal
-
Web interface of the Service Automation.
- Workflow Execution portal
-
Web interface, is the main portal of ProActive Workflows & Scheduling and the entry point for end-users to submit workflows manually, monitor their executions and access job outputs, results, services endpoints, etc.
- Catalog portal
-
Web interface of the Catalog component.
- Event Orchestration
-
ProActive component that monitors a system, according to predefined set of rules, detects complex events and then triggers user-specified actions.
- Event Orchestration portal
-
Web interface of the Event Orchestration component.
- Scheduling API
-
ProActive component that offers a GraphQL endpoint for getting information about a ProActive Scheduler instance.
- Connector IaaS
-
ProActive component that enables to do CRUD operations on different infrastructures on public or private Cloud (AWS EC2, Openstack, VMWare, Kubernetes, etc).
- Job Planner
-
ProActive component providing advanced scheduling options for Workflows.
- Job Planner portal
-
Web interface to manage the Job Planner service.
- Calendar Definition portal
-
Web interface, component of the Job Planner that allows to create Calendar Definitions.
- Calendar Association portal
-
Web interface, component of the Job Planner that defines Workflows associated to Calendar Definitions.
- Execution Planning portal
-
Web interface, component of the Job Planner that allows to see future executions per calendar.
- Job Planner Gantt portal
-
Web interface, component of the Job Planner that allows to see past and future executions on a Gantt diagram.
- Bucket
-
ProActive notion used with the Catalog to refer to a specific collection of ProActive Objects and in particular ProActive Workflows.
- Server Host
-
The machine on which ProActive Scheduler is installed.
SCHEDULER_ADDRESS-
The IP address of the Server Host.
- ProActive Node
-
One ProActive Node can execute one Task at a time. This concept is often tied to the number of cores available on a Compute Host. We assume a task consumes one core (more is possible, see multi-nodes tasks), so on a 4 cores machines you might want to run 4 ProActive Nodes. One (by default) or more ProActive Nodes can be executed in a Java process on the Compute Hosts and will communicate with the ProActive Scheduler to execute tasks. We distinguish two types of ProActive Nodes:
-
Server ProActive Nodes: Nodes that are running in the same host as ProActive server;
-
Remote ProActive Nodes: Nodes that are running on machines other than ProActive Server.
-
- Compute Host
-
Any machine which is meant to provide computational resources to be managed by the ProActive Scheduler. One or more ProActive Nodes need to be running on the machine for it to be managed by the ProActive Scheduler.
|
Examples of Compute Hosts:
|
- Node Source
-
A set of ProActive Nodes deployed using the same deployment mechanism and sharing the same access policy.
- Node Source Infrastructure
-
The configuration attached to a Node Source which defines the deployment mechanism used to deploy ProActive Nodes.
- Node Source Policy
-
The configuration attached to a Node Source which defines the ProActive Nodes acquisition and access policies.
- Scheduling Policy
-
The policy used by the ProActive Scheduler to determine how Jobs and Tasks are scheduled.
PROACTIVE_HOME-
The path to the extracted archive of ProActive Scheduler release, either on the Server Host or on a Compute Host.
- Workflow
-
User-defined representation of a distributed computation. Consists of the definitions of one or more Tasks and their dependencies.
- Workflow Revision
-
ProActive concept that reflects the changes made on a Workflow during it development. Generally speaking, the term Workflow is used to refer to the latest version of a Workflow Revision.
- Generic Information
-
Are additional information which are attached to Workflows or Tasks. See generic information.
- Calendar Definition
-
Is a json object attached by adding it to the Generic Information of a Workflow.
- Job
-
An instance of a Workflow submitted to the ProActive Scheduler. Sometimes also used as a synonym for Workflow.
- Job Id
-
An integer identifier which uniquely represents a Job inside the ProActive Scheduler.
- Job Icon
-
An icon representing the Job and displayed in portals. The Job Icon is defined by the Generic Information workflow.icon.
- Task
-
A unit of computation handled by ProActive Scheduler. Both Workflows and Jobs are made of Tasks. A Task must define a ProActive Task Executable and can also define additional task scripts
- Task Id
-
An integer identifier which uniquely represents a Task inside a Job ProActive Scheduler. Task ids are only unique inside a given Job.
- Task Executable
-
The main executable definition of a ProActive Task. A Task Executable can either be a Script Task, a Java Task or a Native Task.
- Script Task
-
A Task Executable defined as a script execution.
- Java Task
-
A Task Executable defined as a Java class execution.
- Native Task
-
A Task Executable defined as a native command execution.
- Additional Task Scripts
-
A collection of scripts part of a ProActive Task definition which can be used in complement to the main Task Executable. Additional Task scripts can either be Selection Script, Fork Environment Script, Pre Script, Post Script, Control Flow Script or Cleaning Script
- Selection Script
-
A script part of a ProActive Task definition and used to select a specific ProActive Node to execute a ProActive Task.
- Fork Environment Script
-
A script part of a ProActive Task definition and run on the ProActive Node selected to execute the Task. Fork Environment script is used to configure the forked Java Virtual Machine process which executes the task.
- Pre Script
-
A script part of a ProActive Task definition and run inside the forked Java Virtual Machine, before the Task Executable.
- Post Script
-
A script part of a ProActive Task definition and run inside the forked Java Virtual Machine, after the Task Executable.
- Control Flow Script
-
A script part of a ProActive Task definition and run inside the forked Java Virtual Machine, after the Task Executable, to determine control flow actions.
- Control Flow Action
-
A dynamic workflow action performed after the execution of a ProActive Task. Possible control flow actions are Branch, Loop or Replicate.
- Branch
-
A dynamic workflow action performed after the execution of a ProActive Task similar to an IF/THEN/ELSE structure.
- Loop
-
A dynamic workflow action performed after the execution of a ProActive Task similar to a FOR structure.
- Replicate
-
A dynamic workflow action performed after the execution of a ProActive Task similar to a PARALLEL FOR structure.
- Cleaning Script
-
A script part of a ProActive Task definition and run after the Task Executable and before releasing the ProActive Node to the Resource Manager.
- Script Bindings
-
Named objects which can be used inside a Script Task or inside Additional Task Scripts and which are automatically defined by the ProActive Scheduler. The type of each script binding depends on the script language used.
- Task Icon
-
An icon representing the Task and displayed in the Studio portal. The Task Icon is defined by the Task Generic Information task.icon.
- ProActive Agent
-
A daemon installed on a Compute Host that starts and stops ProActive Nodes according to a schedule, restarts ProActive Nodes in case of failure and enforces resource limits for the Tasks.
2. Get started
To submit your first computation to ProActive Scheduler, install it in your environment (default credentials: admin/admin) or just use our demo platform try.activeeon.com.
ProActive Scheduler provides comprehensive interfaces that allow to:
-
Create workflows using ProActive Workflow Studio
-
Submit workflows, monitor their execution and retrieve the tasks results using ProActive Scheduler Portal
-
Add resources and monitor them using ProActive Resource Manager Portal
-
Version and share various objects using ProActive Catalog Portal
-
Provide an end-user workflow submission interface using Workflow Execution Portal
-
Generate metrics of multiple job executions using Job Analytics Portal
-
Plan workflow executions over time using Job Planner Portal
-
Add services using Service Automation Portal
-
Perform event based scheduling using Event Orchestration Portal
-
Control manual workflows validation steps using Notification Portal
We also provide a REST API. and command line interfaces for advanced users.
3. Create and run your computation
3.1. Jobs, workflows and tasks
In order to use Scheduler for executing various computations, one needs to write the execution definition also known as the Workflow definition. A workflow definition is an XML file that adheres to XML schema for ProActive Workflows.
It specifies a number of XML tags for specifying execution steps, their sequence and dependencies. Each execution step corresponds to a task which is the smallest unit of execution that can be performed on a computation resources (ProActive Node). There are several types of tasks which caters different use cases.
3.1.1. Task Types
ProActive Scheduler currently supports three main types of tasks:
-
Native Task, a command with eventual parameters to be executed
-
Script Task, a script written in Groovy, Ruby, Python and other languages supported by the JSR-223
-
Java Task, a task written in Java extending the Scheduler API
For instance, a Script Task can be used to execute an inline script definition or a script file as an execution step whereas a Native Task can be used to execute a native executable file.
| We recommend to use script tasks that are more flexible rather than Java tasks. You can easily integrate with any Java code from a Groovy script task. |
3.1.2. Additional Scripts
In addition to the main definition of a Task, scripts can also be used to provide additional actions. The following actions are supported:
-
one or more selection scripts to control the Task resource (ProActive Node) selection.
-
a fork environment script script to control the Task execution environment (a separate Java Virtual Machine or Docker container).
-
a pre script executed immediately before the main task definition (and inside the forked environment).
-
a post script executed immediately after the main task definition if and only if the task did not trigger any error (also run inside the forked environment).
-
a control flow script executed immediately after the post script (if present) or main task definition to control flow behavior such as branch, loop or replicate (also run inside the forked environment).
-
finally, a clean script executed after the task is finished, whether the task succeeded or not, and directly on the ProActive Node which hosted the task.
3.1.3. Task Dependencies
A workflow in ProActive Workflows & Scheduling can be seen as an oriented graph of Tasks:
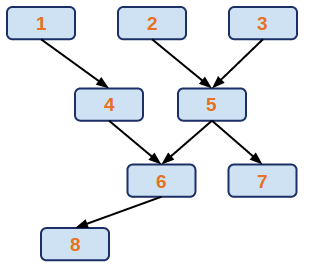
In this tasks graph, we see that task 4 is preceded by task 1, this means that the ProActive Scheduler will wait for the end of task 1 execution before launching task 4. In a more concrete way, task 1 could be the calculation of a part of the problem to solve, and task 4 takes the result provided by task 1 and compute another step of the calculation. We introduce here the concept of passing data between tasks. This relation is called a Dependency, and we say that task 4 depends on task 1.
We see that task 1, 2 and 3 are not linked, so these three tasks can be executed in parallel, because they are independent from each other.
The task graph is defined by the user at the time of workflow creation, but can also be modified dynamically during the job execution by control flow actions such as Replicate.
A finished job contains the results and logs of each task. Upon failure, a task can be restarted automatically or cancelled.
3.2. Native Tasks
A Native Task is a ProActive Workflow task which main execution is defined as a command to run.
Native tasks are the simplest type of Task, where a user provides a command with a list of parameters.
Using native tasks, one can easily reuse existing applications and embed them in a workflow.
Once the executable is wrapped as a task you can easily leverage some of the workflow constructs to run your executable commands in parallel.
You can find an example of such integration in this XML workflow or you can also build one yourself using the Workflow Studio.
Native application by nature can be tied to a given operating system so if you have heterogeneous nodes at your disposal, you might need to select a suitable node to run your native task. This can be achieved using selection script.
| Native Tasks are not the only possibility available to run executables or commands, this can also be achieved using shell language script tasks. |
3.3. Script Tasks
A Script Task is a ProActive Workflow task which main execution is defined as a script.
ProActive Workflows supports tasks in many scripting languages. The currently supported dynamic languages or backends are Groovy, Jython, Python, JRuby, Javascript, Scala, Powershell, VBScript, R, Perl, PHP, Bash, Any Unix Shell, Windows CMD, Dockerfile, Docker Compose and Kubernetes.
Dockerfile, Docker Compose and Kubernetes are not really scripting languages but rather description languages, ProActive tasks can interpret Dockerfiles, Docker Compose or Kubernetes yaml files to start containers or pods.
|
As seen in the list above, Script Tasks can be used to run native operating system commands by providing a script written in bash, ksh, windows cmd, Powershell, etc…
Simply set the language attribute to bash, shell, or cmd and type your command(s) in the workflow.
In this sense, it can replace in most cases a Native Task.
| You can easily embed small scripts in your workflow. The nice thing is that the workflow will be self-contained and will not require to compile your code before executing. However, we recommend that you keep these scripts small to keep the workflow easy to understand. |
You can find an example of a script task in this XML workflow or you can also build one yourself using the Workflow Studio. The quickstart tutorial relies on script tasks and is a nice introduction to writing workflows.
Scripts can also be used to decorate any kind of task (Script, Java or Native) with specific actions, as described in the additional scripts section.
It is thus possible to combine various scripting languages in a single Task. For example a pre script could be written in bash to transfer some files from a remote file system, while the main script will be written in python to process those files.
Finally, a Script Task may or may not return a result materialized by the result script binding.
3.3.1. Script Bindings
A Script Task or additional scripts can use automatically-defined script bindings. These bindings allow to associate the script inside its workflow context, for example, the ability to know the current workflow variables as submitted by a user, the workflow job id as run inside the ProActive Scheduler, etc.
Bindings allow as well to pass information between various scripts inside the same task or across different tasks.
A script binding can be either:
-
Defined automatically by the ProActive Scheduler before the script starts its execution. In this case, we call it also a provided or input script binding.
-
Needed to be defined by the script during its execution to provide meaningful results. In this case, we call it also a result or output script binding.
Below is an example of Script Task definition which uses both types of bindings:
jobId = variables.get("PA_JOB_ID")
result = "The Id of the current job is: " + jobIdAs we can see, the variables binding in provided automatically by the ProActive Scheduler before the script execution and it is used to compute a result binding as task output.
Bindings are stored internally inside the ProActive Scheduler as Java Objects. Accordingly, a conversion may be performed when targeting (or when reading from) other languages.
For example, Generic Information or Workflow Variables are stored as Java objects implementing the Map interface.
When creating the variables or genericInformation bindings prior to executing a Groovy, JRuby, Jython or Python script, the ProActive Scheduler will convert it to various types accepted by the target language.
In those languages, printing the type of the genericInformation binding will show:
Groovy: class com.google.common.collect.RegularImmutableBiMap JRuby: Java::ComGoogleCommonCollect::RegularImmutableBiMap Jython: <type 'com.google.common.collect.RegularImmutableBiMap'> Python: <class 'py4j.java_collections.JavaMap'>
We see here that Groovy, JRuby and Jython did not perform any conversion, whereas Python (CPython) did. This behavior is expected as CPython script execution is run as a standalone python process and a custom type conversion occurs while the formers are run directly inside the task Java Virtual Machine will full Java type compatibility.
Depending on the script type (task script, selection script, etc…), the script may need to define an output binding to return some information to the scheduler.
Below are some examples of output bindings for various kind of scripts:
-
resultandresultMetadatafor a Script Task main execution script. -
selectedfor a selection script. -
loopfor a Loop construct flow script. -
runsfor a Replicate construct flow script.
The complete list of script bindings (both input and output) is available in the Script Bindings Reference section.
Below are descriptions of some specific scripting language support, which can be used in Script Tasks main execution script or in any Task additional scripts.
3.4. Java Tasks
A workflow can execute Java classes thanks to Java Tasks. In terms of XML definition, a Java Task consists of a fully-qualified class name along with parameters:
<task name="Java_Task">
<javaExecutable class="org.ow2.proactive.scheduler.examples.WaitAndPrint">
<parameters>
<parameter name="sleepTime" value="20"/>
<parameter name="number" value="2"/>
</parameters>
</javaExecutable>
</task>The provided class must extend the JavaExecutable abstract class and implement the execute method.
Any parameter must be defined as public attributes. For example, the above WaitAndPrint class contains the following attributes definitions:
/** Sleeping time before displaying. */
public int sleepTime;
/** Parameter number. */
public int number;A parameter conversion is performed automatically by the JavaExecutable super class. If this automatic conversion is not suitable, it is possible to override the init method.
Finally, several utility methods are provided by JavaExecutable and should be used inside execute. A good example is getOut which allows writing some textual output to the workflow task or getLocalSpace which allows access to the task execution directory.
The complete code for the WaitAndPrint class is available below:
public class WaitAndPrint extends JavaExecutable {
/** Sleeping time before displaying. */
public int sleepTime;
/** Parameter number. */
public int number;
/**
* @see JavaExecutable#execute(TaskResult[])
*/
@Override
public Serializable execute(TaskResult... results) throws Throwable {
String message = null;
try {
getErr().println("Task " + number + " : Test STDERR");
getOut().println("Task " + number + " : Test STDOUT");
message = "Task " + number;
int st = 0;
while (st < sleepTime) {
Thread.sleep(1000);
try {
setProgress((st++) * 100 / sleepTime);
} catch (IllegalArgumentException iae) {
setProgress(100);
}
}
} catch (Exception e) {
message = "crashed";
e.printStackTrace(getErr());
}
getOut().println("Terminate task number " + number);
return ("No." + this.number + " hi from " + message + "\t slept for " + sleepTime + " Seconds");
}
}3.5. Run a workflow
To run a workflow, the user submits it to the ProActive Scheduler. It will be possible to choose the values of all Job Variables when submitting the workflow (see section Job Variables). A verification is performed to ensure the well-formedness of the workflow. A verification will also be performed to ensure that all variables are valid according to their model definition (see section Variable Model). Next, a job is created and inserted into the pending queue and waits until free resources become available. Once the required resources are provided by the ProActive Resource Manager, the job is started. Finally, once the job is finished, it goes to the queue of finished jobs where its result can be retrieved.
You can submit a workflow to the Scheduler using the Workflow Studio, the Scheduler Web Interface or command line tools. For advanced users we also expose REST and JAVA APIs.
| During the submission, you will be able to edit Workflow variables, so you can effectively use them to parameterize workflow execution and use workflows as templates. |
3.5.1. Job & Task status
During their execution, jobs go through different status.
| Status | Name | Description |
|---|---|---|
|
Pending |
The job is waiting to be scheduled. None of its tasks have been Running so far. |
|
Running |
The job is running. At least one of its task has been scheduled. |
|
Stalled |
The job has been launched but no task is currently running. |
|
Paused |
The job is paused waiting for user to resume it. |
|
In-Error |
The job has one or more In-Error tasks that are suspended along with their dependencies. User intervention is required to fix the causing issues and restart the In-Error tasks to resume the job. |
| Status | Name | Description |
|---|---|---|
|
Finished |
The job is finished. Tasks are finished or faulty. |
|
Cancelled |
The job has been canceled because of an exception. This status is used when an exception is thrown by the user code of a task and when the user has asked to cancel the job on exception. |
|
Failed |
The job has failed. One or more tasks have failed (due to resources failure). There is no more executionOnFailure left for a task. |
|
Killed |
The job has been killed by the user. |
Similarly to jobs, during their execution, tasks go through different status.
| Status | Name | Description |
|---|---|---|
|
Aborted |
The task has been aborted by an exception on an other task while the task is running. (job is cancelOnError=true). Can be also in this status if the job is killed while the concerned task was running. |
|
Resource down |
The task is failed (only if maximum number of execution has been reached and the node on which it was started is down). |
|
Faulty |
The task has finished execution with error code (!=0) or exception. |
|
Finished |
The task has finished execution. |
|
In-Error |
The task is suspended after first error, if the user has asked to suspend it. The task is waiting for a manual restart action. |
|
Could not restart |
The task could not be restarted. It means that the task could not be restarted after an error during the previous execution. |
|
Could not start |
The task could not be started. It means that the task could not be started due to dependencies failure. |
|
Paused |
The task is paused. |
|
Pending |
The task is in the scheduler pending queue. |
|
Running |
The task is executing. |
|
Skipped |
The task was not executed: it was the non-selected branch of an IF/ELSE control flow action. |
|
Submitted |
The task has just been submitted by the user. |
|
Faulty… |
The task is waiting for restart after an error (i.e. native code != 0 or exception, and maximum number of execution is not reached). |
|
Failed… |
The task is waiting for restart after a failure (i.e. node down). |
3.5.2. Job Priority
A job is assigned a default priority of NORMAL but the user can increase or decrease the priority once the
job has been submitted. When they are scheduled, jobs with the highest priory are executed first.
The following values are available:
-
IDLE -
LOWEST -
LOW -
NORMAL -
HIGHcan only be set by an administrator -
HIGHESTcan only be set by an administrator
3.6. Retrieve logs
It is possible to retrieve multiple logs from a job, these logs can either be:
-
The standard output/error logs associated with a job.
-
The standard output/error logs associated with a task.
-
The scheduler server logs associated with a job.
-
The scheduler server logs associated with a task.
Unless your account belongs to an administrator group, you can only see the logs of a job that you own.
3.6.1. Retrieve logs from the portal
-
Job standard output/error logs:
To view the standard output or error logs associated with a job, select a job from the job list and then on the Output tab in the bottom right panel.
Click on Streaming Output checkbox to auto-fetch logs for running tasks of the entire Job. The logs panel will be updated as soon as new log lines will be printed by this job.
You cannot select a specific Task in the streaming mode. If you activate streaming while some Tasks are already finished, you will get the logs of those Tasks as well.
Click on Finished Tasks Output button to retrieve logs for already finished tasks. For all the finished Tasks within the Job, or for the selected Task.
The command does work when Job is still in Running status, as well as when Job is Finished.
Logs are limited to 1024 lines. Should your job logs be longer, you can select the Full logs (download) option from the drop down list. -
Task standard output/error logs:
To view the standard output or error logs associated with a task, select a job from the job list and a task from the task list.
Then in the Output tab, choose Selected task from the drop down list.
Once the task is terminated, you will be able to click on the Finished Tasks Output button to see the standard output or error associated with the task.
It is not possible to view the streaming logs of single task, only the job streaming logs are available. -
Job server logs:
Whether a job is running or finished, you can access the associated server logs by selecting a job, opening the Server Logs tab in the bottom-right panel and then clicking on Fetch logs.
Server logs contains debugging information, such as the job definition, output of selection or cleaning scripts, etc. -
Task server logs:
In the Server Logs tab, you can choose Selected task to view the server logs associated with a single task.
3.6.2. Retrieve logs from the command line
The chapter command line tools explains how to use the command line interface. Once connected, you can retrieve the various logs using the following commands. Server logs cannot be accessed from the command line.
-
Job standard output/error logs: joboutput(jobid)
> joboutput(1955) [1955t0@precision;14:10:57] [2016-10-27 14:10:057 precision] HelloWorld [1955t1@precision;14:10:56] [2016-10-27 14:10:056 precision] HelloWorld [1955t2@precision;14:10:56] [2016-10-27 14:10:056 precision] HelloWorld [1955t3@precision;14:11:06] [2016-10-27 14:11:006 precision] HelloWorld [1955t4@precision;14:11:05] [2016-10-27 14:11:005 precision] HelloWorld
-
Task standard output/error logs: taskoutput(jobid, taskname)
> taskoutput(1955,'0_0') [1955t0@precision;14:10:57] [2016-10-27 14:10:057 precision] HelloWorld
-
Streaming job standard output/error logs: livelog(jobid)
> livelog(2002) Displaying live log for job 2002. Press 'q' to stop. > Displaying live log for job 2002. Press 'q' to stop. [2002t2@precision;15:57:13] [ABC, DEF]
3.7. Retrieve results
Once a job or a task is terminated, it is possible to get its result. Unless you belong to the administrator group, you can only get the result of the job that you own. Results can be retrieved using the Scheduler Web Interface or the command line tools.
| When running native application, the task result will be the exit code of the application. Results usually make more sense when using script or Java tasks. |
3.7.1. Retrieve results from the portal
In the scheduler portal, select a job, then select a task from the job’s task list. Click on Preview tab in the bottom-right panel.
In this tab, you will see two buttons:
-
Open in browser: when clicking on this button, the result will be displayed in a new browser tab. By default, the result will be displayed in text format. If your result contains binary data, it is possible to specify a different display mode using <<_assigning_metadata_to_task_result,Result Metadata>.
If the task failed, when clicking on the Open in browser button, the task error will be displayed. -
Save as file: when clicking on this button, the result will be saved on disk in binary format. By default, the file name will be generated automatically using the job and task ids, without an extension. It is possible to customize this behavior and specify in the task a file name, or a file extension using Result Metadata.
The following example gets one png image and add the metadata to help the browser display it and add a name when downloading.
file = new File(fileName)
result = file.getBytes()
resultMetadata.put("file.name", fileName)
resultMetadata.put("content.type", "image/png")
3.7.2. Retrieve results from the command line
The chapter command line tools explains how to use the command line interface. Once connected, you can retrieve the task or job results:
-
Result of a single task: taskresult(jobid, taskname)
> taskresult(2002, 'Merge')
task('Merge') result: true
-
Result of all tasks of a job: jobresult(jobid)
> jobresult(2002)
job('2002') result:
Merge : true
Process*1 : DEF
Process : ABC
Split : {0=abc, 1=def}
4. ProActive Studio
ProActive Workflow Studio is used to create and submit workflows graphically. The Studio allows to simply drag-and-drop various task constructs and draw their dependencies to form complex workflows. It also provides various flow control widgets such as conditional branch, loop, replicate etc to construct workflows with dynamic structures.
The studio usage is illustrated in the following example.
4.1. A simple example
The quickstart tutorial on try.activeeon.com shows how to build a simple workflow using script tasks.
Below is an example of a workflow created with the Studio:
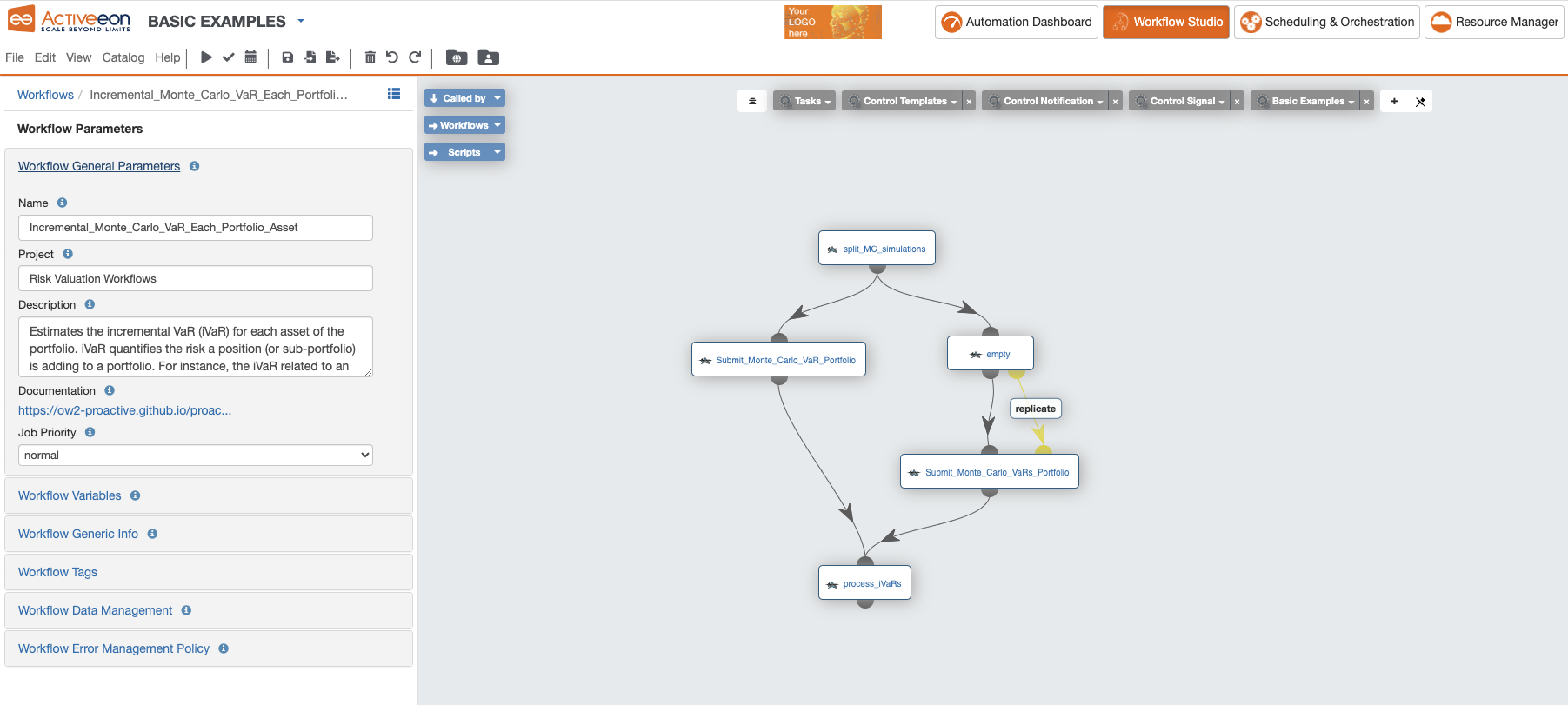
In the left part, are illustrated the General Parameters of the workflow with the following information:
-
Name: the name of the workflow. -
Project: the project name to which belongs the workflow. -
Description: the textual description of the workflow. -
Documentation: if the workflow has a Generic Information named "Documentation", then its URL value is displayed as a link. -
Job Priority: the priority assigned to the workflow. It is by default set toNORMAL, but can be increased or decreased once the job is submitted.
In the right part, we see the graph of dependent tasks composing the workflow. Each task can be selected to show the task specific attributes and defintions.
Finally, above the workflow graph, we see the various palettes which can be used to drag & drop sample task definitions or complex constructs.
The following chapters describe the three main type of tasks which can be defined inside ProActive Workflows.
4.2. Use the ProActive Catalog from the Studio
The GUI interaction with the Catalog can be done in two places: the Studio and Catalog Portal. The portals follow the concepts of the Catalog: Workflows are stored inside buckets, a workflow has some metadata and can have several revisions.
The Catalog view in the Studio or in the Catalog Portal allows to browse all the workflows in the Catalog grouped by buckets and to list all the revisions of a workflow along with their commit message.
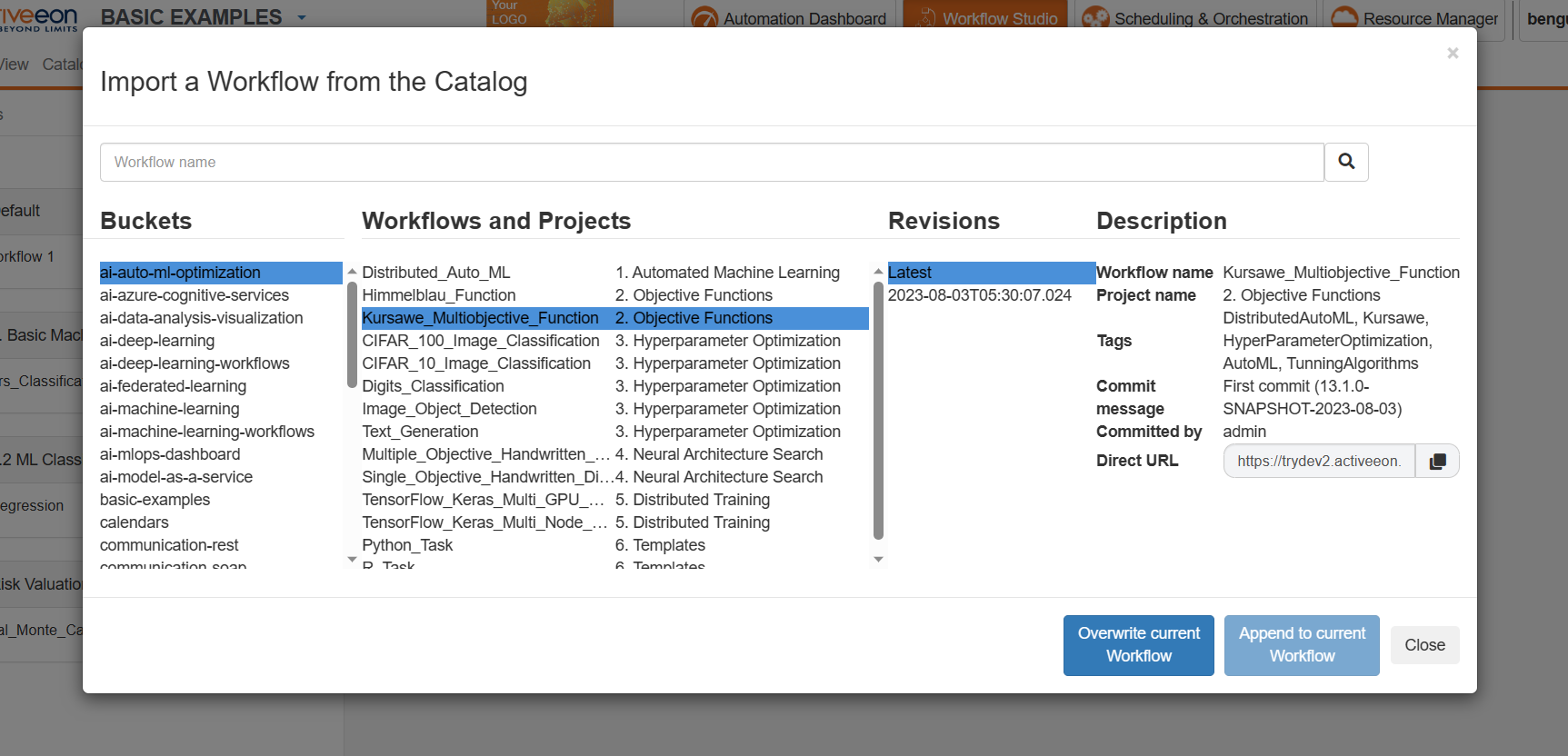
Inside the Studio, there is a Catalog menu from which a user can directly interact with the Catalog to import or publish Workflows.
Additionally, the Palette of the Studio lists the user’s favourite buckets to allow easy import of workflows from the Catalog with a simple Drag & Drop.

4.2.1. Publish current Workflow to the Catalog
Workflows created in the studio can be saved inside a bucket in the Catalog by using the Publish current Workflow to the Catalog action.
When saving a Workflow in the Catalog, users can add a specific commit message.
If a Workflow with the same name already exists in the specified bucket, a new revision of the Workflow is created.
We recommend to always specify commit messages at any commit for an easier differentiation between stored versions.
4.2.2. Get a Workflow from the Catalog
When the Workflow is selected from Catalog you have two options:
-
Open as a new Workflow: Open the Workflow from Catalog as a new Workflow in Studio. -
Append to current Workflow: Append the selected Workflow from the Catalog to the Workflow already opened inside the Studio.
4.2.3. Add Bucket Menu to the Palette
The Palette makes it easier to use workflows stored in a specific Bucket of the Catalog as templates when designing a Workflow.
To add a bucket from the Catalog as a dropdown menu in the Palette: Click on View → Add Bucket Menu to the Palette or you press the ![]() button in the palette.
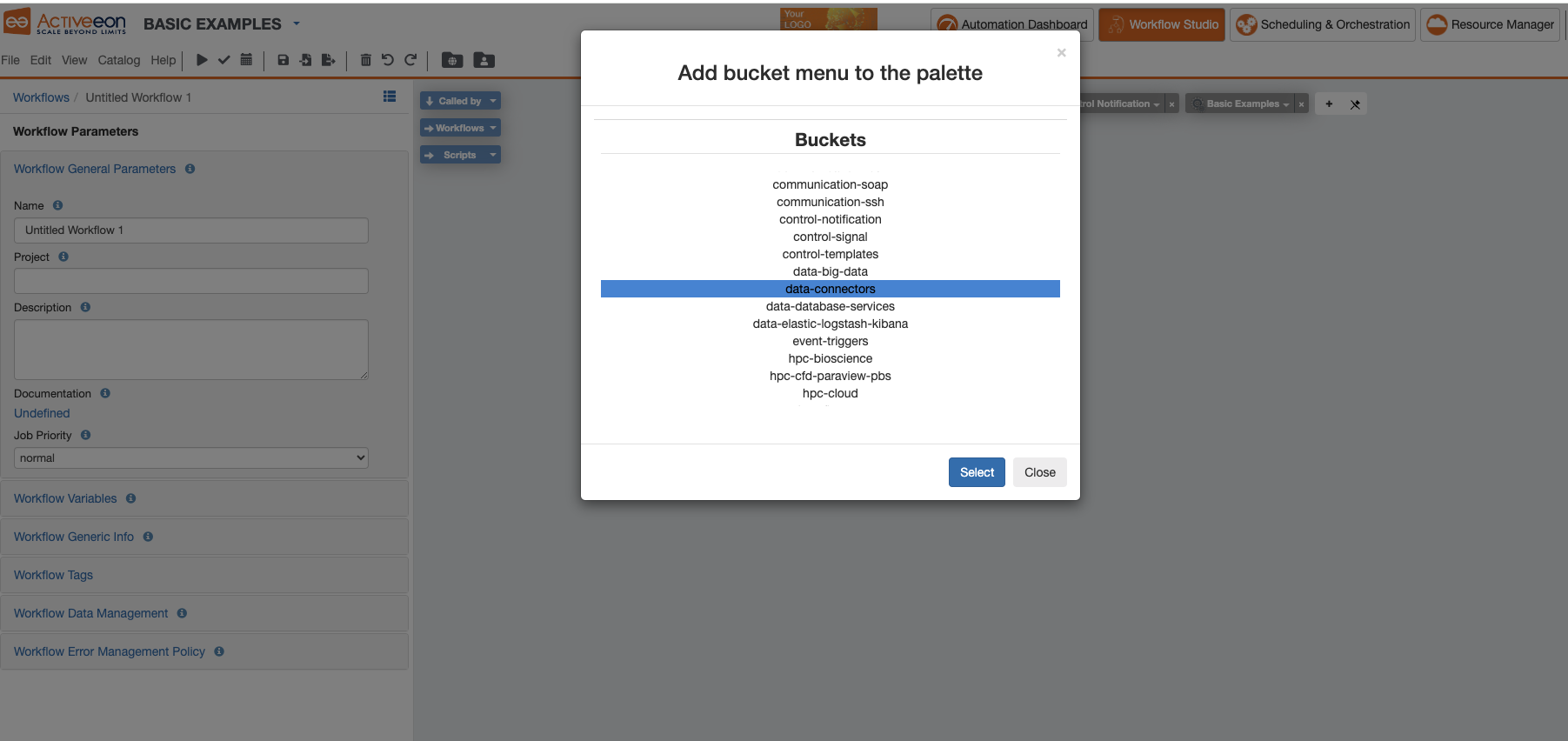
A window will show up to ask you which bucket you want to add to the Palette as in the image below.
button in the palette.
A window will show up to ask you which bucket you want to add to the Palette as in the image below.
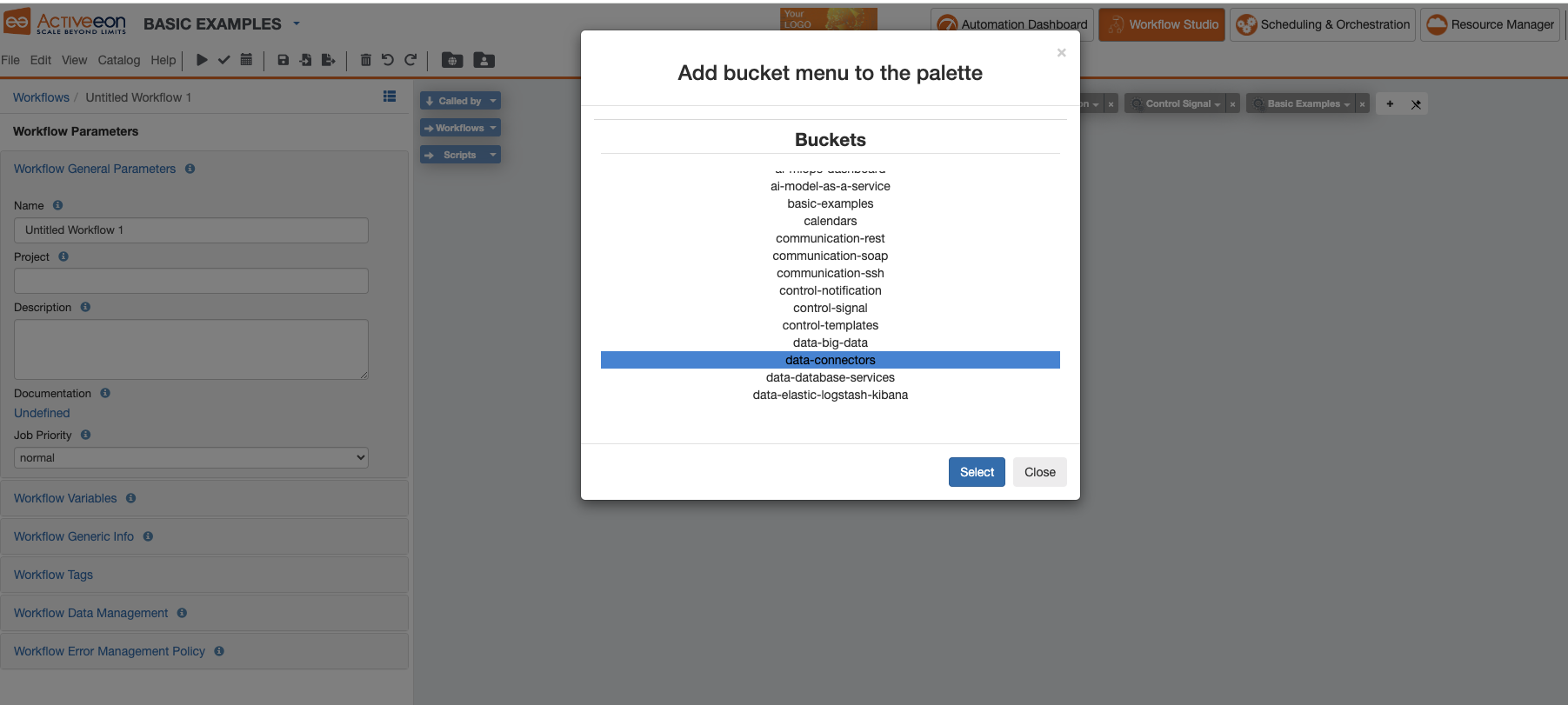
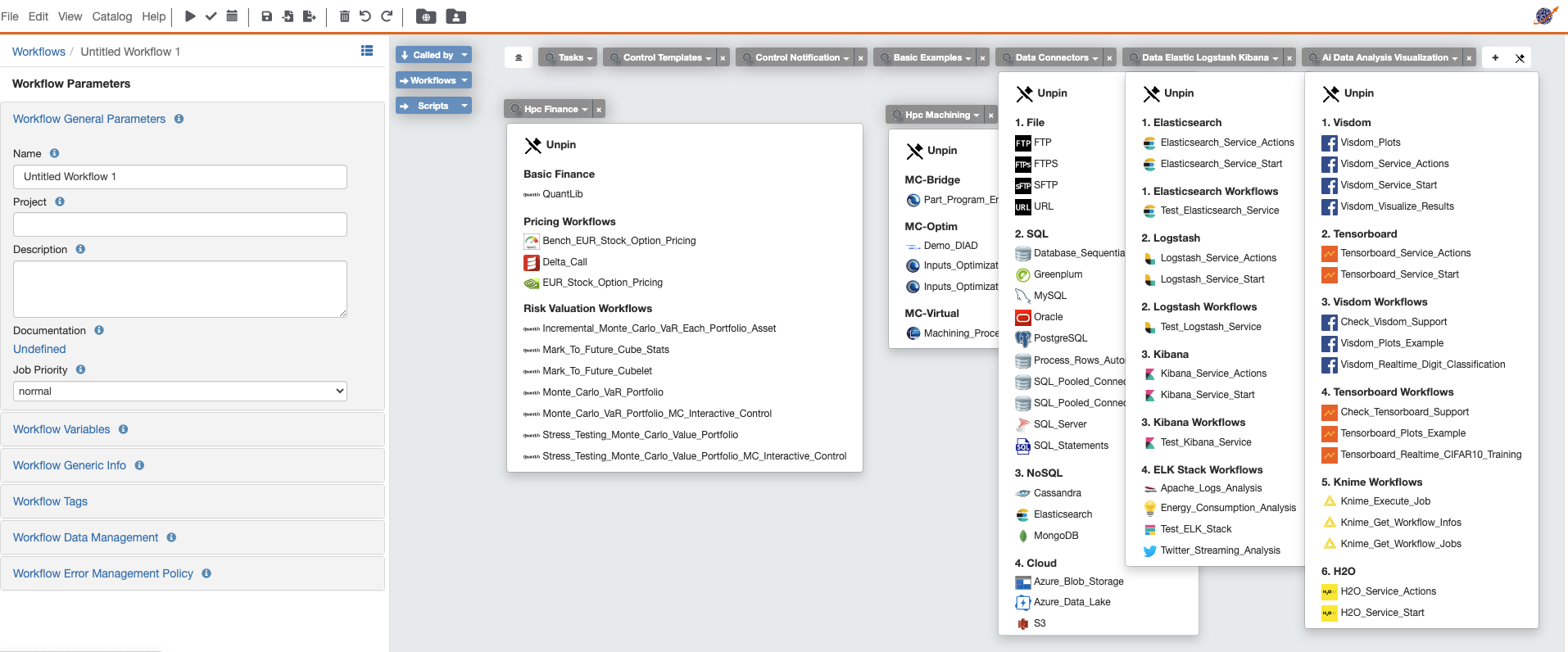
The selected Data Connectors Bucket now appears as a menu in the Studio. See the image below.
You can repeat the operation as many times as you wish in order to add other specific Menus you might need for your workflow design. See the image below.
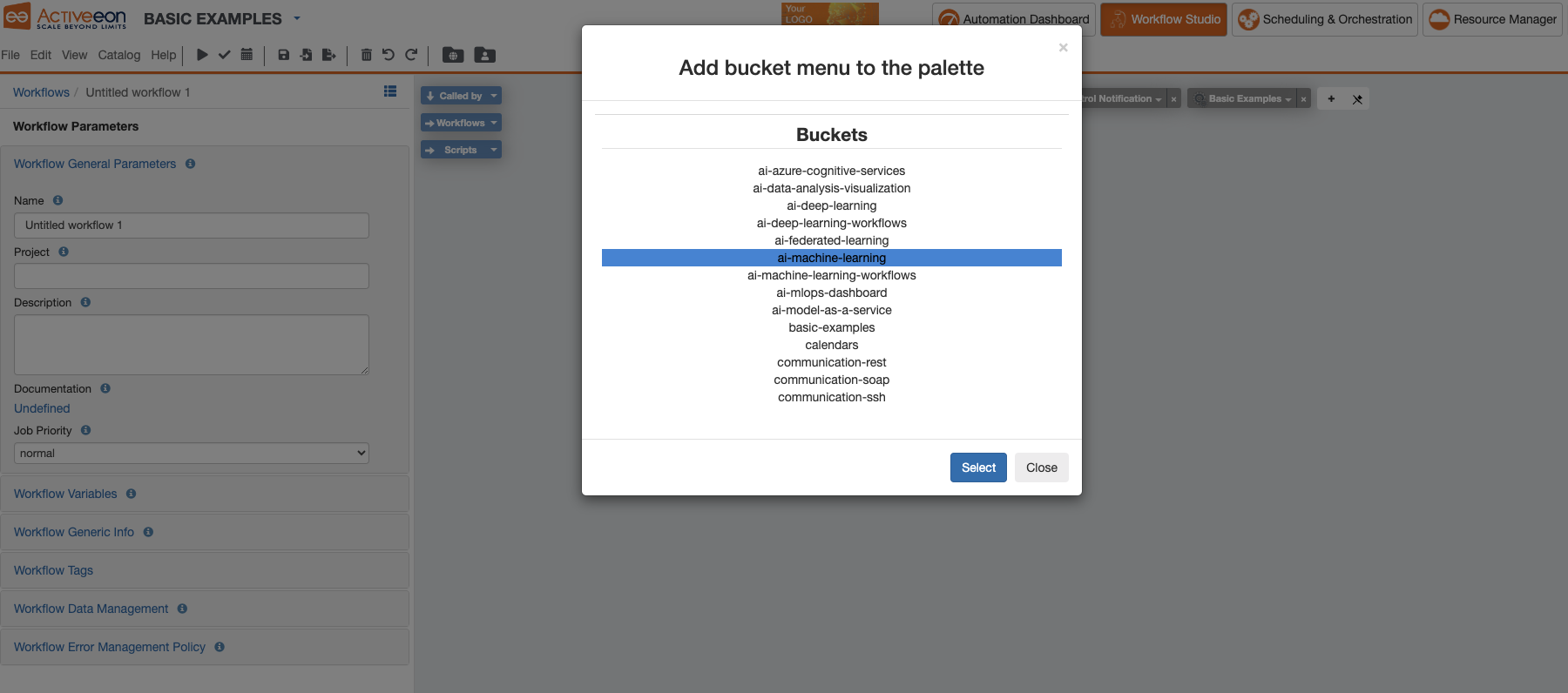
4.2.4. Change Palette Preset
The Studio offers the possibility to set a Preset for the Palette. This makes it easier to load the Palette with a predefined set of default buckets.
Presets are generally arranged by theme (Basic Examples, Machine Learning, Deep Learning, Big Data, etc.)
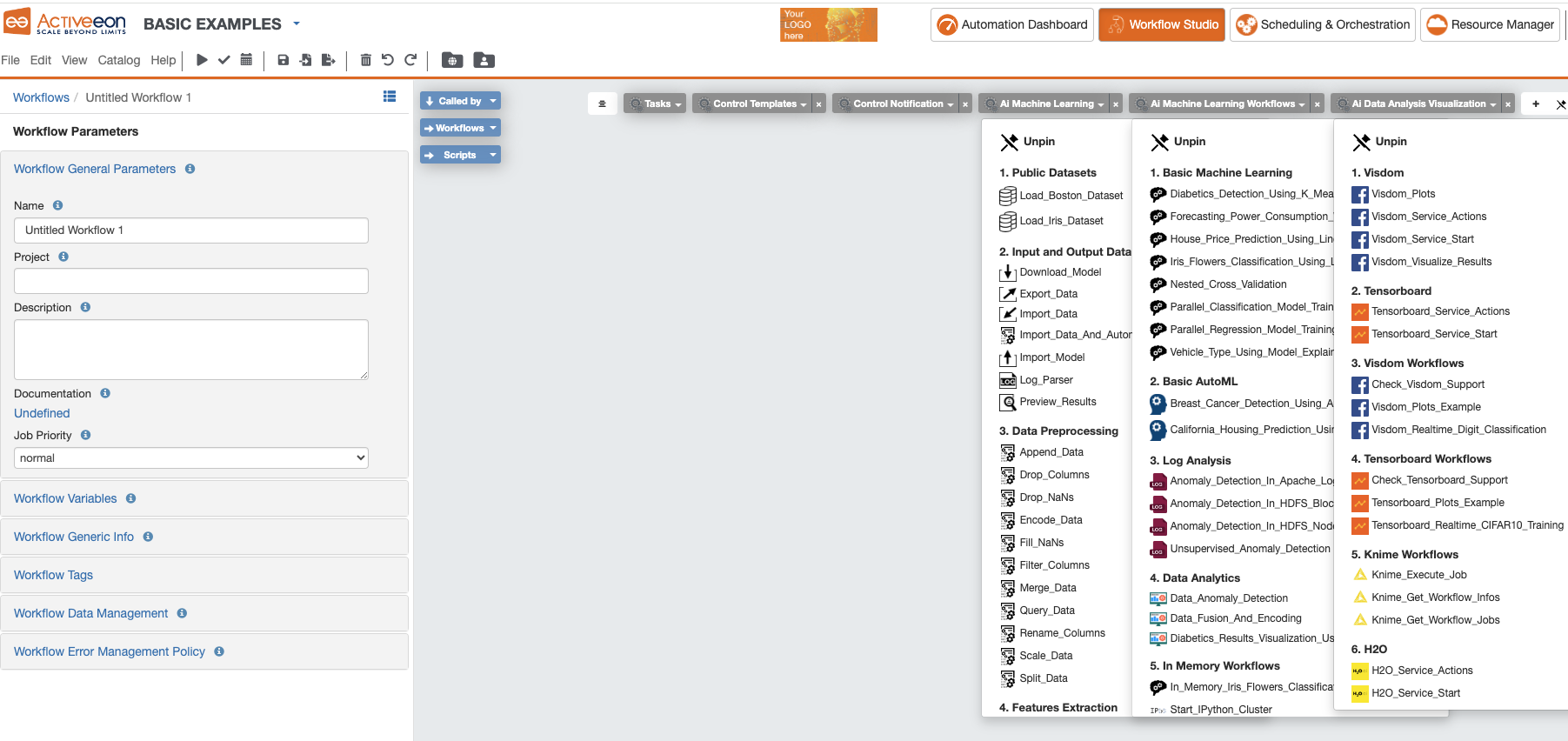
The Palette’s preset can be changed by clicking View → Change Palette Preset. This will show a window with the current list of presets as in the image below.
After changing the preset, its name appears at the top of the Studio and all its buckets are added to the Palette.
5. Workflow concepts
Workflows come with constructs that help you distribute your computation. The tutorial Advanced workflows is a nice introduction to workflows with ProActive.
The following constructs are available:
-
Dependency
-
Replicate
-
Branch
-
Loop
| Use the Workflow Studio to create complex workflows, it is much easier than writing XML! |
5.1. Dependency
Dependencies can be set between tasks in a TaskFlow job. It provides a way to execute your tasks in a specified order, but also to forward result of an ancestor task to its children as parameter. Dependency between tasks is then both a temporal dependency and a data dependency.
Dependencies between tasks can be added either in ProActive Workflow Studio or simply in workflow XML as shown below:
<taskFlow>
<task name="task1">
<scriptExecutable>
<script>
<code language="groovy">
println "Executed first"
</code>
</script>
</scriptExecutable>
</task>
<task name="task2">
<depends>
<task ref="task1"/>
</depends>
<scriptExecutable>
<script>
<code language="groovy">
println "Now it's my turn"
</code>
</script>
</scriptExecutable>
</task>
</taskFlow>5.2. Replicate
The replication allows the execution of multiple tasks in parallel when only one task is defined and the number of tasks to run could change.

-
The target is the direct child of the task initiator.
-
The initiator can have multiple children; each child is replicated.
-
If the target is a start block, the whole block is replicated.
-
The target must have the initiator as only dependency: the action is performed when the initiator task terminates. If the target has an other pending task as dependency, the behavior cannot be specified.
-
There should always be a merge task after the target of a replicate: if the target is not a start block, it should have at least one child, if the target is a start block, the corresponding end block should have at least one child.
-
The last task of a replicated task block (or the replicated task if there is no block) cannot perform a branching or replicate action.
-
The target of a replicate action cannot be tagged as end block.
-
The current replication index (from to 0 to
runs) can be accessed via thePA_TASK_REPLICATIONvariable.
| If you are familiar with programming, you can see the replication as forking tasks. |
5.3. Branch
The branch construct provides the ability to choose between two alternative task flows, with the possibility to merge back to a common flow.
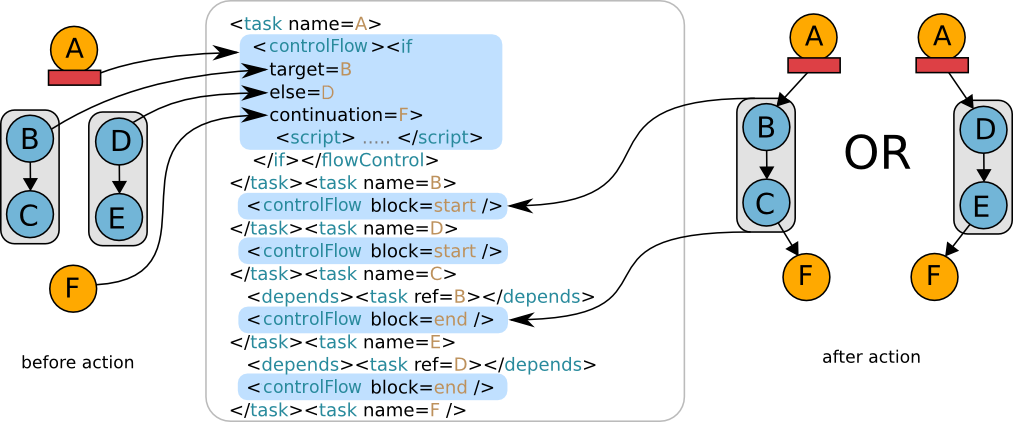
-
There is no explicit dependency between the initiator and the if/else targets. These are optional links (ie. A → B or E → F) defined in the if task.
-
The if and else flows can be merged by a continuation task referenced in the if task, playing the role of an endif construct. After the branching task, the flow will either be that of the if or the else task, but it will be continued by the continuation task.
-
If and else targets are executed exclusively. The initiator however can be the dependency of other tasks, which will be executed normally along the if or the else target.
-
A task block can be defined across if, else and continuation links, and not just plain dependencies (i.e. with A as start and F as end).
-
If using no continuation task, the if and else targets, along with their children, must be strictly distinct.
-
If using a continuation task, the if and else targets must be strictly distinct and valid task blocks.
-
if, else and continuation tasks (B, D and F) cannot have an explicit dependency.
-
if, else and continuation tasks cannot be entry points for the job, they must be triggered by the if control flow action.
-
A task can be target of only one if or else action. A continuation task can not merge two different if actions.
| If you are familiar with programming, you can see the branch as an if/then/else. |
5.4. Loop
The loop provides the ability to repeat a set of tasks.
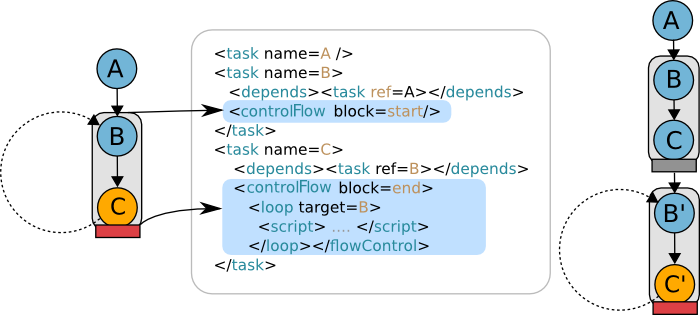
-
The target of a loop action must be a parent of the initiator following the dependency chain; this action goes back to a previously executed task.
-
Every task is executed at least once; loop operates in a do…while fashion.
-
The target of a loop should have only one explicit dependency. It will have different parameters (dependencies) depending if it is executed for the first time or not. The cardinality should stay the same.
-
The loop scope should be a task block: the target is a start block task, and the initiator its related end block task.
-
The current iteration index (from 0 to n until
loopis false) can be accessed via thePA_TASK_ITERATIONvariable.
| If you are familiar with programming, you can see the loop as a do/while. |
5.5. Task Blocks
Workflows often relies on task blocks. Task blocks are defined by pairs of start and end tags.
-
Each task of the flow can be tagged either start or end
-
Tags can be nested
-
Each start tag needs to match a distinct end tag
Task blocks are very similar to the parenthesis of most programming languages: anonymous and nested start/end tags. The only difference is that a parenthesis is a syntactical information, whereas task blocks are semantic.
The role of task blocks is to restrain the expressiveness of the system so that a workflow can be statically checked and validated. A treatment that can be looped or iterated will be isolated in a well-defined task block.
-
A loop flow action only applies on a task block: the initiator of the loop must be the end of the block, and the target must be the beginning.
-
When using a continuation task in an if flow action, the if and else branches must be task blocks.
-
If the child of a replicate task is a task block, the whole block will be replicated and not only the child of the initiator.
5.6. Variables
Variables can come at hand while developing ProActive applications. Propagate data between tasks, customize jobs, and store useful debug information are a few examples of how variables can ease development. ProActive has basically two groups of variables:
-
Workflow variables, declared on the XML job definition.
-
Dynamic Variables, system variables or variables created at task runtime.
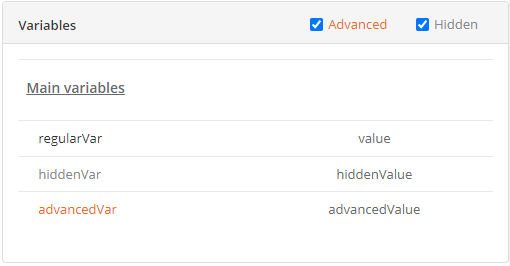
In order to immediately distinguish advanced and hidden variables, we present advanced variables in orange and hidden variables in light grey in our portals.
Here is an example with an Object’s details in the Catalog Portal
5.6.1. Workflow variables
Workflow variables are declared in the XML job definition. Within the definition we can have variables in several levels, at job level the variables are visible and shared by all tasks. At task level, variables are visible only within the task execution context.
Job variables
In a workflow, you can define job variables that are shared and visible by all tasks.
A job variable is defined using the following attributes:
-
name: the variable name.
-
value: the variable value.
-
model: the variable value type or model (optional). See section Variable Model.
-
description: the variable description (optional). The description can be written using html syntax (e.g.
This variable is <b>mandatory</b>.). -
group: the group name associated with the variable (optional). When the workflow has many variables, defining variable groups helps understanding the various parameters. Variables with no associated group are called Main Variables.
-
advanced: when a variable is advanced, it is not displayed by default in the workflow submission form. A checkbox allows the user to display or hide advanced variables.
-
hidden: a hidden variable is not displayed to the user in the workflow submission form. Hidden variables have the following usages:
-
perform hidden checks on other variables, defined by a variable model SpEL expression, see Variable Model and Spring Expression Language Model.
-
build dynamic forms where variables are displayed or hidden depending on the values of other variables, see Variable Model, Spring Expression Language Model and Dynamic form example using SpEL.
-
Variables are very useful to use workflows as templates where only a few parameters change for each execution. Upon submission you can define variable values in several ways from CLI, using the ProActive Workflow Studio, directly editing the XML job definition, or even using REST API.
The following example shows how to define a job variable in the XML:
<job ... >
<variables>
<variable name="variable" value="value" model=""/>
</variables>
...
</job>Job variables can be referenced anywhere in the workflow, including other job variables.
The syntax for referencing a variable is the pattern ${variable_name} (case-sensitive), for example:
<nativeExecutable>
<staticCommand value="${variable}" />
</nativeExecutable>Task variables
Similarly to job variables, Task variables can be defined within task scope in the job XML definition. Task variables scope is strictly limited to the task definition.
A task variable is defined using the following attributes:
-
name: the variable name.
-
value: the variable value.
-
inherited: asserts when the content of this variable is propagated from a job variable or a parent task. If true, the value defined in the task variable will only be used if no variable with the same name is propagated. Value field can be left empty however it can also work as a default value in case a previous task fails to define the variable.
-
model: the variable value type or model (optional). See section Variable Model
-
description: the variable description (optional). The description can be written using html syntax (e.g.
This variable is <b>mandatory</b>.). -
group: the group name associated with the variable (optional). When the workflow has many variables, defining variable groups helps understanding the various parameters. Variables with no associated group are called Main Variables.
-
advanced: when a variable is advanced, it is not displayed by default in the workflow submission form. A checkbox allows the user to display or hide advanced variables.
-
hidden: a hidden variable is not displayed to the user in the workflow submission form. Hidden variables have the following usages:
-
perform hidden checks on other variables, defined by a variable model SpEL expression, see Variable Model and Spring Expression Language Model.
-
build dynamic forms where variables are displayed or hidden depending on the values of other variables, see Variable Model, Spring Expression Language Model and Dynamic form example using SpEL.
-
For example:
<task ... >
<variables>
<variable name="variable" value="value" inherited="false" model=""/>
</variables>
...
</task>Task variables can be used similarly to job variables using the pattern ${variable_name} but only inside the task where the variable is defined.
Task variables override job variables, this means that if a job variable and a task variable are defined with the same name, the task variable value will be used inside the task (unless the task variable is marked as inherited), and the job variable value will be used elsewhere in the job.
Global Variables
Global variables are job variables that are configured inside ProActive server and apply to all workflows or to certain categories of workflows (e.g. workflows with a given name).
See Configure Global Variables and Generic Information section to understand how global variables can be configured on the ProActive server.
Variable Model
Job and Task variables can define a model attribute which let the workflow designer control the variable value syntax.
A workflow designer can for example decide that the variable NUMBER_OF_ENTRIES is expected to be convertible to an Integer ranged between 0 and 20.
The workflow designer will then provide a default value to the variable NUMBER_OF_ENTRIES, for example "10". This workflow is valid as "10" can be converted to an Integer and is between 0 and 20.
When submitting the workflow, it will be possible to choose a new value for the variable NUMBER_OF_ENTRIES. If the user submitting the workflow chooses for example the value -5, the validation will fail and an error message will appear.
Available Models
The following list describes the various model syntaxes available:
-
Main variable models
-
PA:INTEGER , PA:INTEGER[min,max] : variable can be converted to java.lang.Integer, and eventually is contained in the range [min, max].
Examples: PA:INTEGER will accept "-5" but not "1.4", PA:INTEGER[0,20] will accept "12" but not "25". -
PA:LONG , PA:LONG[min,max] : same as above with java.lang.Long.
-
PA:FLOAT , PA:FLOAT[min,max] : same as above with java.lang.Float.
Examples: PA:FLOAT[-0.33,5.99] will accept "3.5" but not "6". -
PA:DOUBLE , PA:DOUBLE[min,max] : same as above with java.lang.Double.
-
PA:SHORT , PA:SHORT[min,max] : same as above with java.lang.Short.
-
PA:BOOLEAN : variable is either "true", "false", "0" or "1".
-
PA:NOT_EMPTY_STRING : variable must be provided with a non-empty string value.
-
PA:HIDDEN : variable which allows the user to securely enter his/her value (i.e., each character is shown as an asterisk, so that it cannot be read.) while submitting the workflow.
-
PA:URL : variable can be converted to java.net.URL.
Examples: PA:URL will accept "http://mysite.com" but not "c:/Temp". -
PA:URI : variable can be converted to java.net.URI.
Examples: PA:URI will accept "/tmp/file" but not "c:\a^~to" due to invalid characters. -
PA:LIST(item1,item2,…) : variable must be one of the values defined in the list.
Examples: PA:LIST(a,b,c) will accept "a", "b", "c" but no other value. -
PA:JSON : variable syntax must be a valid JSON expression as defined in JSON doc.
Examples: PA:JSON will accept {"name": "John", "city":"New York"} and empty values like {} or [{},{}], but not ["test" : 123] (Unexpected character ':') and {test : 123} (Unexpected character 't'). -
PA:REGEXP(pattern) : variable syntax must match the regular expression defined in the pattern. The regular expression syntax is described in class Pattern.
Examples: PA:REGEXP([a-z]+) will accept "abc", "foo", but not "Foo".
-
-
Advanced variable models
-
PA:CATALOG_OBJECT : use this type when you want to reference and use, in the current workflow, another object from the Catalog. Various portals and tools will make it easy to manage catalog objects. For instance, at Job submission, you will be able to browse the Catalog to select the needed object.
Variable value syntax must be a valid expression that matches the following pattern:bucketName/objectName[/revision]. Note that the revision sub-pattern is a hash code number represented by 13 digit.
Examples: PA:CATALOG_OBJECT accepts "bucket-example/object-example" and "bucket-example/object-example/1539310165443" but not "bucket-example/object-example/153931016" (invalid revision number) nor "bucket-example/" (missing object name). -
PA:CATALOG_OBJECT(kind,contentType,bucketName,objectName) : one or more filters can be specified in the specified order of the PA:CATALOG_OBJECT model to limit the accepted values. For example PA:CATALOG_OBJECT(kind) can be used to filter a specific
Kind, PA:CATALOG_OBJECT(kind,contentType) to filter bothKindandContent-type, PA:CATALOG_OBJECT(,contentType) to filter only aContent-type(note the empty first parameter), etc…
In that case, the variable value must be a catalog object which matches theKind,Content type,BucketNameand/orObjectNamerequirements (For more information regarding Kind and Content type click here).
Note that Kind and Content type are case insensitive and require a "startsWith" matching, while BucketName and ObjectName are case sensitive and, by default, require a "contains" matching. That is, the Kind and the Content type of the provided catalog object must start with the filters specified in the model while BucketName and ObjectName of the catalog object should contain them. The scheduler server verifies that the object exists in the catalog and fulfills the specified requirements when the workflow is submitted.
Examples:-
PA:CATALOG_OBJECT(Workflow/standard) accepts only standard workflow objects, that means PSA workflows or scripts are not valid values.
-
PA:CATALOG_OBJECT(Script, text/x-python) accepts a catalog object which is a Python script but not a workflow object or a Groovy script.
-
PA:CATALOG_OBJECT(,,basic-example, Native_Task) accepts catalog objects that are in buckets ia-basic-example or basic-example-python and named Native_Task or Native_Task_Python but not NATIVE_TASK.
-
-
Notice that the default behaviour of BucketName or ObjectName filters can be modified by including the special character
%that matches any word. Hence, by adding%in the beginning (resp. end) of a BucketName or an ObjectName we mean that the filtered value should end (resp. start) with the specified string.
Examples:
-
-
-
-
PA:CATALOG_OBJECT(,,%basic-example) accepts catalog objects that are in buckets ia-basic-example or db-basic-example but not the ones in basic-example-python.
-
PA:CATALOG_OBJECT(,,,Native_Task%) accepts catalog objects that are named Native_Task or Native_Task_Python but not Simplified_Native_Task.
It is possible to have a PA:CATALOG_OBJECT object variable that has an optional value by using the notation PA:CATALOG_OBJECT?. See here.
-
-
-
-
PA:CREDENTIAL : variable whose value is a key of the ProActive Scheduler Third-Party Credentials (which are stored on the server side in encrypted form). The variable allows the user to access a credential from the task implementation in a secure way (e.g., for a groovy task credentials.get(variables.get("MY_CRED_KEY")) instead of a plain-text. At workflow submission, the scheduler server verifies that the key exists in the 3rd party credentials of the user. In addition, the use of this model enables the user to manage her/his credentials via a graphical interface.
-
PA:CRON : variable syntax must be a valid cron expression as defined in the cron4j manual. This model can be used for example to control the provided value to the
loopcontrol flow parameter.+ Examples: PA:CRON will accept "5 * * * *" but not "* * * *" (missing minutes sub-pattern). -
PA:DATETIME(format) , PA:DATETIME(format)[min,max] : variable can be converted to a java.util.Date using the format specified (see the format definition syntax in the SimpleDateFormat class).
A range can also be used in the PA:DATETIME model. In that case, each bound of the range must match the date format used.
This model is used for example to control an input value used to trigger the execution of a task at a specific date time.Examples:
PA:DATETIME(yyyy-MM-dd) will accept "2014-12-01" but not "2014".
PA:DATETIME(yyyy-MM-dd)[2014-01-01, 2015-01-01] will accept "2014-12-01" but not "2015-03-01".
PA:DATETIME(yyyy-MM-dd)[2014, 2015] will result in an error during the workflow definition as the range bounds [2014, 2015] are not using the format yyyy-MM-dd. -
PA:MODEL_FROM_URL(url) : variable syntax must match the model fetched from the given URL. This can be used for example when the model needs to represent a list of elements which may evolve over time and is updated inside a file. Such as a list of machines in an infrastructure, a list of users, etc.
See Variable Model using Resource Manager data for premade models based on the Resource Manager state.
Examples: PA:MODEL_FROM_URL(file:///srv/machines_list_model.txt), if the file machines_list_model.txt contains PA:LIST(host1,host2), will accept only "host1" and "host2", but may accept other values as the machines_list_model file changes. -
PA:GLOBAL_FILE : variable whose value is the relative path of a file in the Global Data Space. At workflow submission, the scheduler server verifies that the file exists in the global dataspace. In addition, this model enables the user to graphically browse the global dataspace to select a file as an input data for the workflow.
-
PA:USER_FILE : variable whose value is the relative path of a file in the User Data Space. At workflow submission, the scheduler server verifies that the file exists in the user dataspace. In addition, this model enables the user to graphically browse the user dataspace to select a file as an input data for the workflow.
-
PA:GLOBAL_FOLDER : variable whose value is the relative path of a folder in the Global Data Space. At workflow submission, the scheduler server verifies that the folder exists in the global dataspace. Note, the variable value should not end with a slash to avoid the problem of duplicate slash in its usage.
-
PA:USER_FOLDER : variable whose value is the relative path of a folder in the User Data Space. At workflow submission, the scheduler server verifies that the folder exists in the user dataspace. Note, the variable value should not end with a slash to avoid the problem of duplicate slash in its usage.
-
PA:SPEL(SpEL expression) : variable syntax will be evaluated by a SpEL expression. Refer to Spring Expression Language Model.
-
PA:SPEL2(error message,SpEL expression) : variable syntax will be evaluated by a SpEL expression. This model allows in addition to provide a user-friendly error message pPlease note that the error message must not contain any comma character). Refer to Spring Expression Language Model.
-
Variable Model (Type) using a type defined dynamically in another Variable
A Variable can use as its type a model that is defined in another variable.
To use such possibility, the workflow designer can simply use in the Model definition of another specific variable name proceeded by the character $.
When submitting the workflow, the user will have the ability to select the model dynamically by changing the value of the referenced variable. And then will be able to select the value of the first variable according to the selected type.
For example, if we have:
variable1 has as its model PA:LIST(PA:GLOBAL_FILE, PA:INTEGER)
variable2 has as its model $variable1
Then the model of variable2 is the value that the variable variable1 will have in runtime. Thus, it will be either PA:GLOBAL_FILE or PA:INTEGER.
Optional Variable
To define an optional variable, the workflow designer can simply add ? at the end of the model attribute, such as PA:INTEGER?.
When submitting the workflow, it will be allowed to not provide a value for the optional variables. The validation will only fail when the user fills in an invalid value.
For example, a variable MY_OPTIONAL_INTEGER defined as the model PA:INTEGER? will accept an empty string as the variable value, but it will refuse 1.4.
All the available model syntaxes, except PA:NOT_EMPTY_STRING support to be defined as optional.
Variable Model using Resource Manager data
ProActive Resource Manager provides a set of REST endpoints which allow to create dynamic models based on the Resource Manager state.
These models are summarized in the following table. Models returned are PA:LIST types which allow to select a value in ProActive portals through a drop-down list. The list always contain an empty value choice.
| Metric Name | Description | Model Syntax | Example query/returned data |
|---|---|---|---|
Hosts |
All machine host names or ip addresses registered in the Resource Manager |
|
PA:LIST(,try.activeeon.com,10.0.0.19) |
Hosts Filtered by Name |
All machine host names or ip addresses registered in the Resource Manager that match a given regular expression. |
Some characters of the regular expression must be encoded according to the specification. |
?name=try%5Ba-z%5D*.activeeon.com ⇒ PA:LIST(,try.activeeon.com,trydev.activeeon.com,tryqa.activeeon.com) |
Node Sources |
All node sources registered in the Resource Manager |
|
PA:LIST(,Default,LocalNodes,GPU,Kubernetes) |
Node Sources Filtered by Name |
All node sources registered in the Resource Manager that match a given regular expression. |
Some characters of the regular expression must be encoded according to the specification. |
?name=Azure.* ⇒ PA:LIST(,AzureScaleSet1,AzureScaleSet2) |
Node Sources Filtered by Infrastructure Type |
All node sources registered in the Resource Manager whose infrastructure type matches a given regular expression. See Node Source Infrastructures. |
Some characters of the regular expression must be encoded according to the specification. |
?infrastructure=Azure.* will return all node sources that have an AzureInfrastructure or AzureVMScaleSetInfrastructure types. |
Node Sources Filtered by Policy Type |
All node sources registered in the Resource Manager whose policy type matches a given regular expression. See Node Source Policies. |
Some characters of the regular expression must be encoded according to the specification. |
?policy=Dynamic.* will return all node sources that have a DynamicPolicy type. |
Tokens |
All tokens registered in the Resource Manager (across all registered ProActive Nodes). See NODE_ACCESS_TOKEN. |
|
PA:LIST(,token1,token2) |
Tokens Filtered by Name |
All tokens registered in the Resource Manager (across all registered ProActive Nodes) that match a given regular expression. See NODE_ACCESS_TOKEN. |
Some characters of the regular expression must be encoded according to the specification. |
?name=token.* ⇒ PA:LIST(,token1,token2) |
Tokens Filtered by Node Source |
All tokens registered in the given Node Source. This filter returns a list which contains tokens defined:
See NODE_ACCESS_TOKEN. |
The exact name of the target Node Source must be provided (check is case-sensitive). |
?nodeSource=LocalNodes ⇒ PA:LIST(,token1,token2) |
Spring Expression Language Model
The PA:SPEL(expr) or PA:SPEL2(message,expr) models allows defining expressions able to validate a variable value or not. Additionally, these models can be used to validate multiple variable values or to dynamically update other variables.
The PA:SPEL2 model allows in addition to provide an error message, which will be displayed to the user when the value entered does not satisfy the SpEL expression. Please note that the error message must not contain any comma character.
The syntax of the SpEL expression is defined by the Spring Expression Language reference.
For security concerns, we apply a restriction on the authorized class types. Besides the commonly used data types (Boolean, String, Long, Double, etc.), we authorize the use of ImmutableSet, ImmutableMap, ImmutableList, Math, Date types, JSONParser and ObjectMapper for JSON type and DocumentBuilderFactory for XML type.
In order to interact with variables, the expression has access to the following properties:
-
#value: this property will contain the value of the current variable defined by the user. -
variables['variable_name']: this property array contains all the variable values of the same context (for example of the same task for a task variable). -
models['variable_name']: this property array contains all the variable models of the same context (for example of the same task for a task variables). -
valid: can be set totrueorfalseto validate or invalidate a variable. -
temp: can be set to a temporary object used in the SpEL expression. -
tempMap: an empty Hash Map structure which can be populated and used in the SpEL expression.
The expression has also access to the following functions (in addition to the functions available by default in the SpEL language):
-
t(expression): evaluate the expression and returntrue. -
f(expression): evaluate the expression and returnfalse. -
s(expression): evaluate the expression and return an empty string. -
hideVar('variable name'): hides the variable given in parameter. Used to build Dynamic form example using SpEL. Returnstrueto allow chaining actions. -
showVar('variable name'): shows the variable given in parameter. Used to build Dynamic form example using SpEL. Returnstrueto allow chaining actions. -
hideGroup('group name'): hides all variables belonging to the variable group given in parameter. Used to build Dynamic form example using SpEL. Returnstrueto allow chaining actions. -
showGroup('group name'): shows all variables belonging to the variable group given in parameter. Used to build Dynamic form example using SpEL. Returnstrueto allow chaining actions.
The SpEL expression must either:
-
return a boolean value,
trueif the value is correct,falseotherwise. -
set the valid property to
trueorfalse.
Any other behavior will raise an error.
-
Example of SpEL simple validations:
PA:SPEL(#value == 'abc'): will accept the value if it’s the 'abc' string
PA:SPEL(T(Integer).parseInt(#value) > 10): will accept the value if it’s an integer greater than 10.Note that #value always contains a string and must be converted to other types if needed.
-
Example of SpEL multiple validations:
PA:SPEL(variables['var1'] + variables['var2'] == 'abcdef'): will be accepted if the string concatenation of variable var1 and var2 is 'abcdef'.
PA:SPEL(T(Integer).parseInt(variables['var1']) + T(Integer).parseInt(variables['var2']) < 100): will be accepted if the sum of variables var1 and var2 are smaller than 100. -
Example of SpEL variable inference:
PA:SPEL( variables['var2'] == '' ? t(variables['var2'] = variables['var1']) : true ): if the variable var2 is empty, it will use the value of variable var1 instead. -
Example of SpEL variable using ObjectMapper type:
PA:SPEL( t(variables['var1'] = new org.codehaus.jackson.map.ObjectMapper().readTree('{"abc": "def"}').get('abc').getTextValue()) ): will assign the value 'def' to the variable var1. -
Example of SpEL variable using DocumentBuilderFactory type:
PA:SPEL( t(variables['var'] = T(javax.xml.parsers.DocumentBuilderFactory).newInstance().newDocumentBuilder().parse(new org.xml.sax.InputSource(new java.io.StringReader('<employee id="101"><name>toto</name><title>tata</title></employee>'))).getElementsByTagName('name').item(0).getTextContent()) ): will assign the value 'toto' to the variable var1.the SpEL expression must return a boolean value, this is why in the above expressions we use the t(expression)function to perform affectations and return a booleantruevalue.
Dynamic form example using SpEL
Using SpEL expressions, it is possible to show or hide variables based on the values of other variables. Thus, it allows to create dynamic forms.
Consider the following variables definition (attributes xml escaping has been removed for clarity):
<variables>
<variable name="type" value="vegetable" model="PA:LIST(vegetable,fruit)" description="" group="" advanced="false" hidden="false"/>
<variable name="potatoes" value="0" model="PA:INTEGER" description="Amount of potatoes to order (in kilograms)" group="vegetables" advanced="false" hidden="false"/>
<variable name="leek" value="0" model="PA:INTEGER" description="Amount of leek to order (in kilograms)" group="vegetables" advanced="false" hidden="false"/>
<variable name="apples" value="0" model="PA:INTEGER" description="Amount of apples to order (in kilograms)" group="fruits" advanced="false" hidden="true"/>
<variable name="oranges" value="0" model="PA:INTEGER" description="Amount of oranges to order (in kilograms)" group="fruits" advanced="false" hidden="true"/>
<variable name="type_handler" value="" model="PA:SPEL(variables['type'] == 'vegetable' ? showGroup('vegetables') && hideGroup('fruits') : showGroup('fruits') && hideGroup('vegetables'))" description="" group="" advanced="false" hidden="true"/>
</variables>The first variable type presents a choice to the user : select fruits or vegetables.
The last variable type_handler, which is hidden to the user, analyses this choice and displays either variables belonging to the fruits group or the vegetables group.
The SpEL model associated with type_handler performs this operation:
PA:SPEL(variables['type'] == 'vegetable' ? showGroup('vegetables') && hideGroup('fruits') : showGroup('fruits') && hideGroup('vegetables'))
When type is equal to fruit, then the variables belonging to the vegetables group are hidden, and the variables belonging to the fruits group are shown. Respectively, the vegetables group is shown and the fruits group is hidden when type is equal to vegetable.
The complete workflow example can be downloaded here.
Here is how the variables are displayed when submitting the workflow:


5.6.2. Dynamic Variables
As opposed to Workflow variables, dynamic variables are created or manipulated directly when executing workflow tasks scripts,
through the use of the variables script binding map (see the Script Bindings chapter or Script Bindings Reference for more information about script bindings).
We have mainly two types of dynamic variables:
-
ProActive system variables, declared by the ProActive scheduler.
-
Script variables, created after adding values to the
variablesmap.
ProActive system variables
Some variables are implicitly defined by the Scheduler to retrieve runtime information about a job or a task.
Here is the list of ProActive system variables:
Variable name |
Description |
Type |
|
The current job ID. |
String |
|
The current job name. |
String |
|
The current task ID. |
String |
|
The current task name. |
String |
|
The current iteration index, when using looping, starts at 0. |
Integer |
|
The current iteration index, when using a replication, starts at 0. |
Integer |
|
The path to the progress file, used to set the task’s progress. You can import and use the utility class |
String |
|
The path to Scheduler home, where the Scheduler or the Node is installed. |
String |
|
The path to the hostfile when using a multi nodes task. |
String |
|
The number of acquired nodes when using a multi nodes task. |
Integer |
|
The username of the ProActive user who has submitted the job. |
String |
|
The URL of scheduler REST api. |
String |
|
The URL of scheduler REST public api if the setting pa.scheduler.rest.public.url is defined in |
String |
|
The URL of catalog REST api. |
String |
|
The URL of catalog REST public api if the setting pa.catalog.rest.public.url is defined in |
String |
|
The URL of Service Automation REST api. |
String |
|
The URL of Service Automation REST public api if the setting pa.cloud-automation.rest.public.url is defined in |
String |
|
The URL of job planner REST api. |
String |
|
The URL of job planner REST public api if the setting pa.job-planner.rest.public.url is defined in |
String |
|
The URL of notification service REST api. |
String |
|
The URL of notification service REST public api if the setting pa.notification-service.rest.public.url is defined in |
String |
They can be used inside the workflow with the pattern syntax, for example:
<task ...>
...
<forkEnvironment workingDir="/opt/${PA_JOB_ID}"></forkEnvironment>
...
</task>Script variables
In addition to the ability to declare variables directly inside job XML definition, it is also possible to
dynamically read and write new variables while executing a task script with the variables map. This map of variables is bound to
hash type depending on the script engine you are using, for instance in native
Java as Map.
In Groovy as a global map, see below:
String var = variables.get("one_variable")
variables.put("other_variable", "foo")In the Groovy example above the first line retrieve the value of variable
one_variable from the variables map. The second line create a new entry other_variable with value foo.
The variables map is propagated down the execution chain. If a task modifies a variable in the variables map,
or add a new variable, all dependent tasks will have access to this modification.
For example:
// task1
String var = variables.get("one_variable")
variables.put("one_variable", "foo")
variables.put("other_variable", "bar")// task2 depends on task1
println variables.get("one_variable") // will display "foo"
println variables.get("other_variable") // will display "bar"If a task depends on several tasks and each task modifies the same variable, the final value of the variable which is propagated down the execution chain, depends on the order of task execution. Therefore, the users need to take appropriate measures to prevent any undesired effects such as race conditions.
System variables can also be accessed from the variables map, for example:
println variables.get("PA_JOB_ID") // will display the id of the current jobIf using a Bash shell script, variables are accessible through environment variables.
#!/bin/bash
echo $variables_PA_TASK_NAME| In native tasks and Bash/CMD script engines, variables can be read but not written to. |
For Java native script you can set any Java serializable object as a variable value. They will be converted into strings using toString() method when required, for instance, to make those values available as environment variables in native tasks.
The field variable tag has an inherited field, if this field is set as true a task variable will read
its value from the variables map instead of the value field in the XML definition.
In this case, the value field becomes optional and work as a default value.
Below a XML schema that shows two tasks: first and second. Task first insert a new
variable using variables.put("inherited_var", "somevalue").
Task second declares inherited_var
but with defaultvalue, this value will be overwritten by the first task, variables.put("inherited_var", "somevalue").
Defining a default value might be useful if for some reason the first task fails before inserting the inherited_var
on variables map. In this last case the defaultvalue remains unchanged.
<task name="first" >
<scriptExecutable>
<script>
<code language="groovy">
<![CDATA[
variables.put("inherited_var", "somevalue")
]]>
</code>
</script>
</scriptExecutable>
</task>
...
<task name="second">
<variables>
<variable name="inherited_var" value="defaultvalue" inherited="true"/>
</variables>
<depends>
<task ref="before"/>
</depends>
...
</task>Dynamic replacements
We’ve seen in Job variables that we can use the ${varname} syntax to create and access variables.
Dynamic replacement is in charge to resolve variables just before the execution of task script, or
in case of job variables, just before submitting the job.
We can also combine recursive definitions of variables.
For example, one could write:
<job ...>
...
<variables>
<variable name="job_var" value="hello" model=""/>
<variable name="job_var2" value="${job_var}" model=""/>
<variable name="job_var3" value="${job_var2}" model=""/>
</variables>
...
</job>The dynamic replacement will resolve job_var3 to hello just before submitting the job to the scheduler.
| We can use job variable references in task variables but not otherwise. |
When dynamic replacing a task script variable the resolution happens just before running the task. So we can
use the variables map value. The example below will print "hello world" because hello is recursively
resolved at job level assigning hello world to inherited_var. When task_2 starts its local
variable task_var2 is dynamically replaced by hello world, i.e., the content of inherited_var that was
inserted in the variables map by the previous task.
<job ... >
<variables>
<variable name="job_var" value="hello" model=""/>
<variable name="job_var2" value="${job_var}" model=""/>
</variables>
<taskFlow>
<task name="task_1" >
<scriptExecutable>
<script>
<code language="groovy">
<![CDATA[
variables.put("inherited_var", "\${job_var2} world")
]]>
</code>
</script>
</scriptExecutable>
</task>
<task name="task_2">
<variables>
<variable name="task_var2" value="${inherited_var}" inherited="false"/>
</variables>
<depends>
<task ref="task_1"/>
</depends>
<scriptExecutable>
<script>
<code language="groovy">
<![CDATA[
println ""+variables.get("task_var2")
]]>
</code>
</script>
</scriptExecutable>
</task>
</taskFlow>
</job>Note that we can combine recursive definitions of variables.
For example, one could write:
<task ...>
...
<forkEnvironment workingDir="/opt/${DIRECTORY_${PA_TASK_REPLICATION}}"></forkEnvironment>
...
</task>In that case, the variable DIRECTORY_0 or DIRECTORY_1, etc (depending on the replication index) will be used in the working dir attribute.
Pattern variable replacements may be performed at submission time or at execution time:
-
A replacement performed at execution time means that the replacement is executed only when the task enclosing the replacement is executed.
-
A replacement performed at submission time means that the replacement is directly executed when the job is submitted to the scheduler.
Replacements directly using global job or task variables will always be performed at submission time.
In the following example, the description replacement is performed at submission time:
<job ... >
<variables>
<variable name="description" value="My ProActive workflow"/>
</variables>
...
<task ... >
<description>${description}</description>
</task>
</job>Replacements using system variables, such as the workingDir example above, will always be performed at execution time.
5.7. Generic Information
In addition to variables, another key/value structure can be accessed inside a script: Generic Information.
Generic information semantics differ from Job variables semantics in the following way:
-
Generic information can be accessed inside a script, but cannot be modified.
-
Generic information can be defined at job-level or at task-level. If the same generic information is defined both at job-level and at task-level, the latter value takes precedence inside the task scope.
-
Generic information cannot be used directly inside the workflow with the syntax ${} (See Job variables).
-
Generic information are used in general internally by the scheduler, for example to provide information to the scheduling loop on how to handle the task. An example of such generic information is the START_AT info used inside Cron Tasks.
-
Generic information can use in their definition job/task variables patterns, pattern replacements can be done at execution time when using task generic information.
-
Generic information need in most cases to be defined manually by the workflow designer, but some generic information such as PARENT_JOB_ID are defined automatically by ProActive.
Example of a generic information definition:
For example:
<task ... >
<genericInformation>
<info name="ginfo" value="${test}"/>
</genericInformation>
...
</task>Some generic information can also be configured globally on the ProActive server. These global generic information will then apply to all submitted workflows or to certain categories of workflows (e.g. workflows with a given name). Global generic information are job-level only.
See Configure Global Variables and Generic Information section to understand how global generic information can be configured on the ProActive server.
The following table describes all available generic information:
Name |
Description |
Scope |
Mode |
Example |
Resource Manager |
||||
execute task(s) on node(s) with token-based usage restriction |
job-level, task-level |
Manual |
my_token |
|
execute task(s) on node(s) belonging to the given node source. Provision nodes if needed similarly to NS or NODESOURCENAME. |
job-level, task-level |
Manual |
MyNodeSource |
|
run the task on a Native Scheduler Node Source. Provision a new node to run the task on the associated cluster. Value is the Node Source name. Deprecated, consider using NODE_SOURCE instead. |
job-level,task-level |
Manual |
SLURM |
|
extra parameters given to the native scheduler command |
job-level,task-level |
Manual |
-q queue1 -lnodes=2:ppn=2 |
|
command run before the ProActive Node is started inside the Native Scheduler infrastructure |
job-level,task-level |
Manual |
module load mpi/gcc/openmpi-1.6.4 |
|
run the task on a Node Source controlled by a Dynamic Policy (generally cloud node sources). Provision a new node to run the task on the associated node source. Value is the Node Source name. Deprecated, consider using NODE_SOURCE instead. |
job-level,task-level |
Manual |
Azure |
|
add tags to cloud instances acquired by a Node Source controlled by a Dynamic Policy (only available when the associated infrastructure is an Azure Scale Set Infrastructure). Definition must be a json key/value structure which contain tag names and values. |
job-level,task-level |
Manual |
{ "tagName1" : "tagValue1", "tagName2" : "tagValue2" } |
|
Scheduling |
||||
delay a job or task execution at a specified date/time |
job-level, task-level |
Manual |
2020-06-20T18:00:00+02:00 |
|
job deadline used in Earliest Deadline First Scheduling Policy |
job-level |
Manual |
+5:30:00 |
|
job expected execution time used in Earliest Deadline First Scheduling Policy |
job-level |
Manual |
1:00:00 |
|
comma-separated list of licenses used by this job or this task. See License Policy |
job-level, task-level |
Manual |
software_A,software_B |
|
number of Nodes that this job and all its sub-jobs are allowed to use in parallel. See Node Usage Policy |
job-level |
Manual |
10 |
|
maximum execution time of a task |
job-level, task-level |
Manual |
10:00 |
|
User Interface |
||||
contains the id of the parent job (if the current job has been submitted from another workflow) |
job-level |
Automatic |
24 |
|
Add a documentation link to the workflow |
job-level |
Manual |
http://my-server/my-doc.html |
|
Add a documentation link to the task |
task-level |
Manual |
http://my-server/my-doc.html |
|
Add an icon to the workflow |
job-level |
Manual |
http://my-server/my-icon.png |
|
Add an icon to the task |
task-level |
Manual |
http://my-server/my-icon.png |
|
generic information automatically added by the Job Planner. It contains the name of the calendar based on which the job is planned. |
job-level |
Automatic |
every_10_minutes |
|
generic information automatically added by the Job Planner. It contains the next execution date of the job. |
job-level |
Automatic |
2022-04-26 12:50:00 CEST |
|
contains the origin from which the job was submitted. |
job-level |
Automatic |
job-planner |
|
Notification |
||||
send email to recipient(s) based on job state events |
job-level |
Manual |
||
a list of job events associated with email notifications |
job-level |
Manual |
JOB_PENDING_TO_RUNNING, JOB_RUNNING_TO_FINISHED |
|
Housekeeping |
||||
once the job is terminated, this setting controls the delay after which it will be removed from the scheduler database |
job-level |
Manual |
3d 12h |
|
once the job is terminated with errors, this setting controls the delay after which it will be removed from the scheduler database. This generic information should be set in addition to REMOVE_DELAY when there is a need to keep the job longer in the scheduler database in case of error. |
job-level |
Manual |
3d 12h |
|
Task Control |
||||
skip sub-process cleaning after the task is terminated |
task-level |
Manual |
true |
|
skip pre-script execution and store its content as a file |
task-level |
Manual |
my_prescript.py |
|
Result Format |
||||
Assign a MIME content type to a byte array task result |
task-level |
Manual |
image/png |
|
Assign a file name to a byte array task result |
task-level |
Manual |
image_balloon.png |
|
Assign a file extension to a byte array task result |
task-level |
Manual |
.png |
|
Run As User |
||||
Allows overriding the impersonation method used when executing the task. Can be |
job-level, task-level |
Manual |
|
|
Allows overriding the login name used during the impersonation. This allows to run a task under a different user as the user who submitted the workflow. |
job-level, task-level |
Manual |
bob |
|
Allows defining or overriding a user domain that will be attached to the impersonated user. User domains are only used on Windows operating systems. |
job-level, task-level |
Manual |
MyOrganisation |
|
Allows overriding the password attached to the impersonated user. This can be used only when the impersonation method is set to |
job-level, task-level |
Manual |
MyPassword |
|
Similar to RUNAS_PWD but the password will be defined inside Third-Party Credential instead of inlined in the workflow. This method of defining the password should be preferred to RUNAS_PWD for security reasons. The value of RUNAS_PWD_CRED must be the third-party credential name containing the user password. |
job-level, task-level |
Manual |
MyPasswordCredName |
|
Allows overriding the SSH private key attached to the impersonated user. This can be used only when the impersonation method is set to |
job-level, task-level |
Manual |
MySSHKeyCredName |
|
CPython engine |
||||
Python command to use in CPython script engine. |
job-level, task-level |
Manual |
python3 |
|
Docker Compose engine |
||||
general parameters given to the docker-compose command in Docker Compose script engine. |
job-level, task-level |
Manual |
--verbose |
|
general parameters given to the docker-compose up command in Docker Compose script engine. |
job-level, task-level |
Manual |
--exit-code-from helloworld |
|
declare a string to be used as options separator in Docker Compose script engine. |
job-level, task-level |
Manual |
!SPLIT! |
|
Dockerfile engine |
||||
actions to perform in Dockerfile script engine. |
task-level |
Manual |
build,run |
|
tag identifying the docker image in Dockerfile script engine. |
task-level |
Manual |
my-image |
|
tag identifying the docker container in Dockerfile script engine. |
task-level |
Manual |
my-container |
|
options given to the |
job-level, task-level |
Manual |
--no-cache |
|
options given to the |
job-level, task-level |
Manual |
--detach |
|
command given to |
job-level, task-level |
Manual |
/bin/sh -c echo 'hello' |
|
options given to the |
job-level, task-level |
Manual |
-t -w /my/work/dir |
|
options given to the |
job-level, task-level |
Manual |
--time 20 |
|
options given to the |
job-level, task-level |
Manual |
--volumes |
|
options given to the |
job-level, task-level |
Manual |
--force |
|
declare a string to be used as options separator in Dockerfile script engine. |
job-level, task-level |
Manual |
!SPLIT! |
|
5.7.1. START_AT
The START_AT Generic Information can be used to delay a job or task execution at a specified date/time.
Its value should be ISO 8601 compliant. See Cron Tasks for more details.
Examples:
-
START_AT = "2020-06-20T18:00:00"will delay the job execution until 20th June 2020 at 6pm GMT. -
START_AT = "2020-06-20T18:00:00+02:00"will delay the job execution until 20th June 2020 at 6pm GMT+02:00.
START_AT can be defined at job-level (delay the execution of the whole job) or at task-level (delay the execution of a single task).
5.7.2. PARENT_JOB_ID
The PARENT_JOB_ID Generic Information is set automatically by ProActive when the current job has been submitted from another workflow using the Scheduler API.
It contains the id of the parent job which submitted the current job.
PARENT_JOB_ID is defined at job-level
5.7.3. NODE_ACCESS_TOKEN
The NODE_ACCESS_TOKEN Generic Information can be used to execute a task or all tasks of a workflow to specific nodes restricted by tokens.
The value of NODE_ACCESS_TOKEN must contain the token value. Workflows or tasks with NODE_ACCESS_TOKEN enabled will run exclusively on nodes containing the token.
See Node Source Policy Parameters for further information on node token restrictions.
NODE_ACCESS_TOKEN can be defined at job-level (applies to all tasks of a workflow) or at task-level (applies to a single task).
5.7.4. Email
Email notifications on job events can be enabled on workflows using the following generic information:
EMAIL: contains the email address(es) of recipient(s) which should be notified.
NOTIFICATION_EVENTS: contains the set of events which should trigger a notification.
These generic information can be defined at job-level only.
See Get Notifications on Job Events for further information.
5.7.5. REMOVE_DELAY
The REMOVE_DELAY generic information can be used to control when a job is removed from the scheduler database after its termination.
The housekeeping mechanism must be configured to allow usage of REMOVE_DELAY.
REMOVE_DELAY overrides the global pa.scheduler.core.automaticremovejobdelay setting for a particular job.
It allows a job to be removed either before or after the delay configured globally on the server.
The general format of the REMOVE_DELAY generic information is VVd XXh YYm ZZs, where VV contain days, XX hours, YY minutes and ZZ seconds.
The format allows flexible combinations of the elements:
-
12d 1h 10m: 12 days, 1 hour and 10 minutes. -
26h: 26 hours. -
120m 12s: 120 minutes and 12 seconds.
REMOVE_DELAY can be defined at job-level only.
5.7.6. REMOVE_DELAY_ON_ERROR
The REMOVE_DELAY_ON_ERROR generic information can be used to control when a job is removed from the scheduler database after its termination, if the job has terminated with errors.
The housekeeping mechanism must be configured to allow usage of REMOVE_DELAY_ON_ERROR.
REMOVE_DELAY_ON_ERROR overrides the global pa.scheduler.core.automaticremove.errorjob.delay setting for a particular job.
It allows a job to be removed either before or after the delay configured globally on the server.
The general format of the REMOVE_DELAY_ON_ERROR generic information is VVd XXh YYm ZZs, where VV contain days, XX hours, YY minutes and ZZ seconds.
The format allows flexible combinations of the elements:
-
12d 1h 10m: 12 days, 1 hour and 10 minutes. -
26h: 26 hours. -
120m 12s: 120 minutes and 12 seconds.
REMOVE_DELAY_ON_ERROR can be defined at job-level only.
5.7.7. Earliest Deadline First Policy
The Earliest Deadline First Policy is a Scheduling Policy which can be enabled in the ProActive Scheduler server.
When enabled, this policy uses the following generic information to determine jobs deadlines and expected duration:
-
JOB_DDL: represents the job deadline in absolute (e.g.2018-08-14T08:40:30+02:00) or relative to submission (e.g.+4:30) format. -
JOB_EXEC_TIME: represents job expected execution time in the format HH:mm:ss, mm:ss or ss (e.g.4:30)
See Earliest Deadline First Policy for further information.
JOB_DDL and JOB_EXEC_TIME can be defined at job-level only.
5.7.8. REQUIRED_LICENSES
The License Policy is a Scheduling Policy which can be enabled in the ProActive Scheduler server.
When enabled, this policy uses the REQUIRED_LICENSES generic information to determine which software licenses are consumed by the job or by the task.
REQUIRED_LICENSES is a comma-separated list of software names, which must match the names set in the License Policy configuration.
REQUIRED_LICENSES can be defined at job-level or task-level.
5.7.9. MAX_NODES_USAGE
The Node Usage Policy is a Scheduling Policy which can be enabled in the ProActive Scheduler server.
When enabled, this policy uses the MAX_NODES_USAGE generic information to determine how many Nodes a job and all its sub-jobs can use in parallel.
MAX_NODES_USAGE expects an integer value containing the number of parallel Nodes. When enabled on a job, MAX_NODES_USAGE will be implicitly applied to all sub-jobs.
For example, if job_A defines MAX_NODES_USAGE=10 and is currently using 4 Nodes, then job_B and job_C both children of job_A, can use a total of 6 Nodes in parallel.
A sub-job can override this behavior by setting MAX_NODES_USAGE in its definition, either to:
-
a positive value. In that case, the sub-job will still have a maximum Node usage limit, but independently from its ancestor.
-
a negative value. In that case, the sub-job will have no maximum Node usage limit.
MAX_NODES_USAGE can be defined at job-level only.
5.7.10. DISABLE_PTK
The DISABLE_PTK Generic Information can be used to prevent the Process Tree Killer from running after a task execution.
Disabling the Process Tree Killer is mostly useful when a task requires to start a backgroud process which must remain alive after the task terminates.
Simply define a DISABLE_PTK=true generic information on any given task to prevent the Process Tree Killer from running.
More information is available in the Task Termination Behavior section.
DISABLE_PTK can be defined at task-level only.
5.7.11. WALLTIME
The WALLTIME Generic Information can be used to enforce a maximum execution time for a task, or all tasks of a workflow.
The general format of the walltime attribute is [hh:mm:ss], where h is hour, m is minute and s is second.
The format still allows for more flexibility. We can define the walltime simply as 5 which corresponds to
5 seconds, 10 is 10 seconds, 4:10 is 4 minutes and 10 seconds, and so on.
|
When used at job-level, the configured walltime will not be applied to the workflow globally but to each individual task of the workflow. For example, if the walltime is configured at job-level to be ten minutes, each task of the workflow can run no more than ten minutes, but the workflow itself has no time limitation. |
As the walltime can also be configured directly in the workflow (xml attribute) or globally on the scheduler server (scheduler property), an order of priority applies.
More information is available in the Maximum execution time for a task section.
WALLTIME can be defined at job-level or task-level.
5.7.12. PRE_SCRIPT_AS_FILE
The PRE_SCRIPT_AS_FILE Generic Information can be used to store a task pre-script into a file and skip its execution.
It can be used for example to embed inside a workflow a data file or a file written in a script language not supported by ProActive tasks and delegate its execution to a command-line interpreter.
More information is available in the Save script section.
PRE_SCRIPT_AS_FILE can be defined at task-level only.
5.7.13. NODE_SOURCE
NODE_SOURCE is a multipurpose generic information which allows selecting only nodes that belong to the specified Node Source.
Other than selecting nodes, it allows also the dynamic provisioning of nodes when the selected Node Source is controlled by a Dynamic Policy or is a Native Scheduler Node Source.
NODE_SOURCE should be preferred to using NS or NODESOURCENAME generic information.
Example usages:
-
NODE_SOURCE=LocalNodes⇒ the task will run exclusively on nodes that belong to the LocalNodes node source. -
NODE_SOURCE=AzureNodeSource⇒ will dynamically provision nodes in AzureNodeSource (here AzureNodeSource refer to an AzureInfrastructure node source controlled by a DynamicPolicy) and run the task in the provisioned node. -
NODE_SOURCE=SlurmNodeSource⇒ will dynamically provision nodes in a Slurm cluster attached to SlurmNodeSource (here SlurmNodeSource refer to a NativeSchedulerInfrastructure node source) and run the task in the provisioned node.
NODE_SOURCE can be defined at job-level (applies to all tasks of a workflow) or at task-level (applies to a single task).
5.7.14. Native Scheduler
NS (short for Native Scheduler), NS_BATCH and NS_PRE are Generic Information used to deploy and configure workflow tasks inside a Native Scheduler infrastructure.
-
NS: execute a task associated with this generic information inside a ProActive Node Source interacting with a native scheduler. The Node Source will dynamically deploy a Node to execute a task marked with this generic information. Deprecated, consider using NODE_SOURCE instead. The value of this generic information can be:-
equal to the node source name. Example:
NS=Slurm. -
trueto select any Native Scheduler node source. -
falseto disallow executing the task on a Native Scheduler node source.
-
-
NS_BATCH: allows providing additional parameters to the native scheduler. Example:NS_BATCH=-q queue1 -lnodes=2:ppn=2. -
NS_PRE: allows providing a single line command which will be executed before the ProActive Node on the cluster. Example:NS_PRE=module load mpi/gcc/openmpi-1.6.4.
See Execute Tasks on a Native Scheduler Node Source for more information.
NS, NS_BATCH and NS_PRE can be defined at job-level (applies to all tasks of a workflow) or at task-level (applies to a single task).
5.7.15. NODESOURCENAME
NODESOURCENAME is used to deploy workflow tasks in a Node Source controlled by a Dynamic Policy.
The Node Source will dynamically deploy a Node to execute a task marked with this generic information.
Deprecated, consider using NODE_SOURCE instead.
See Dynamic Policy for more information.
NODESOURCENAME can be defined at job-level (applies to all tasks of a workflow) or at task-level (applies to a single task).
5.7.16. RESOURCE_TAGS
RESOURCE_TAGS is used to assign tags to compute instances deployed in a Node Source controlled by a Dynamic Policy.
RESOURCE_TAGS format is a json key/value structure, such as:
{
"tagName1" : "tagValue1",
"tagName2" : "tagValue2"
}The Node Source will forward these tags to the Node Source Infrastructure. The way these tags will be added to compute resources depends on the infrastructure. Currently, only the Azure Scale Set Infrastructure supports tags assignment.
See Dynamic Policy Resource Tagging and Scale Set Tagging for more information.
RESOURCE_TAGS can be defined at job-level (applies to all tasks of a workflow) or at task-level (applies to a single task).
5.7.17. Documentation
The Documentation generic information allows to associate an html documentation with a workflow.
Its value must contain an URL pointing to the workflow documentation.
Documentation can be defined at job-level only.
The task.documentation generic information allows to associate an html documentation with a task.
Its value must contain an URL pointing to the task documentation.
task.documentation can be defined at task-level only.
Documentation and task.documentation values can also be a relative path.
In that case, the html file containing the documentation must be put inside SCHEDULER_HOME/dist/war/getstarted/doc.
5.7.18. Icon Management
There are specific generic information that are dedicated to icon management.
The icon of a workflow is specified inside the job-level Generic Information using the keyword workflow.icon.
The icon of a task is specified inside task-level Generic Information using the keyword task.icon.
These generic information are used in ProActive portals for proper visualization of workflow and task icons.
The value of these generic information can contain either a url or a path to the icon.
ProActive server stores by default workflow icons in SCHEDULER_HOME/dist/war/automation-dashboard/styles/patterns/img/wf-icons/.
Example value with the default icon path: /automation-dashboard/styles/patterns/img/wf-icons/postgresql.png
5.7.19. Result Metadata
The following generic information can be used to assign result metadata to a workflow task.
Can only be used if the task result content is an array of bytes.
-
content.type: define the MIME type of the result. -
file.name: allows to store (Save as) the result from the scheduler or workflow-automation portals as a specific file name. -
file.extension: allows to store (Save as) the result from the scheduler or workflow-automation portals as a specific file extension with auto-generated file name.
See Assigning metadata to task result for further information.
Result metadata generic information can be defined at task-level only.
5.7.20. PYTHON_COMMAND
When using CPython tasks, the PYTHON_COMMAND generic information can be used to define the command starting the python interpreter.
The interpreter is started by default using the python command, but this generic information can be defined to use for example python3.
See Python script language for further information.
PYTHON_COMMAND generic information should be defined at task-level but can be defined at job-level to apply to all workflow tasks.
5.7.21. Docker Compose options
When using Docker Compose tasks, the following generic information can be used to control options given to docker-compose commands:
-
docker-compose-options: general parameters given to the docker-compose command. -
docker-compose-up-options: options given to thedocker-compose upcommand. -
docker-compose-options-split-regex: declare a string to be used as options separator.
See Docker Compose script language for further information.
The Docker Compose generic information should be defined at task-level but can be defined at job-level to apply to all workflow tasks.
5.7.22. Dockerfile options
When using Dockerfile tasks, the following generic information can be used to control options given to docker commands:
-
docker-actions: actions to perform. A comma separated list of possible actions (build, run, exec, stop, rmi). Default isbuild,run,stop,rmi. -
docker-image-tag: tag identifying the docker image. Default isimage_${PA_JOB_ID}t${PA_TASK_ID} -
docker-container-tag: tag identifying the docker container. Default iscontainer_${PA_JOB_ID}t${PA_TASK_ID} -
docker-build-options: options given to thedocker buildcommand. -
docker-run-options: options given to thedocker runcommand. -
docker-exec-command: command given todocker exec, if used indocker-actions. If the command contains spaces,docker-file-options-split-regexshould be used to split command parameters. -
docker-exec-options: options given to thedocker execcommand. Default is-t(which should always be included). -
docker-stop-options: options given to thedocker stopcommand. -
docker-rm-options: options given to thedocker rmcommand. -
docker-rmi-options: options given to thedocker rmicommand. -
docker-file-options-split-regex: declare a string to be used as options separator, instead of thespacecharacter.
See Dockerfile script language for further information.
The Dockerfile generic information should be defined at the task level. Some (docker-file-options-split-regex, or command options) may be defined at the job level to apply to all tasks of the workflow.
5.7.23. Job Planner
The Job Planner automatically adds two generic information to the jobs it submits:
-
calendar.name: the calendar name based on which the job is planned. -
next.execution: the next execution date of the planned job. The date is formatted with respect to the patternyyyy-MM-dd HH:mm:ss zand considers the time zone specified in the Job Planner configuration. When no time zone is specified, the default time zone of ProActive server is considered.
5.7.24. Submission.mode
The Submission Mode allows keeping track from where a Job has been submitted. It can have values in:
-
Interactive Submissions:
studio,catalog,workflow-execution,scheduler-portal -
Automated Submissions:
job-planner,service-automation,event-orchestration -
API Submissions:
workflow-api,cli,rest-api -
Custom:
user-defined value, to differentiate application-specific submissions.
It is implemented with the submission.mode Generic Information that records the information.
When submitting a workflow from one of the portals (Studio, Scheduler, Workflow Execution, Catalog, etc.), or when using one of the ProActive submission services (Job Planner, Service Automation, Event Orchestration) this Generic Information is automatically defined by the system, using the standardized values.
When a workflow is submitted from a third-party component (such as a company service), one can set this Generic Information value to a meaningful custom name, that will help identify the origin from which the workflow has been submitted.
The Submission Mode can be seen synthetically in the Health Dashboard for a selected time-frame in the widget “Submission Mode”, including custom values.
The Submission Mode can also be seen:
-
In Workflow Execution: the user can see the value in the Generic Information section of the detailed Job info.
-
In Scheduler Portal: the value is displayed in “Submitted from” column of the Job table, and in the Job info tab.
5.8. Task result
Another way to propagate data from a task to another is the use of the result script binding. Anywhere in a parent task (usually at the end) you can set a value to a reserved variable named result. This value will be available in the child tasks i.e which are depending on the parent task. If a task has one or several parents, results will always be an array.
Assuming that we have two tasks task1 and task2 written in Groovy:
// task1
result = "task1";// task2
result = "task2";and task3 that depends on tasks task1 and task2, then, you can access result values defined by the parents as follows:
// task3
println(results[0]);
// will print "task1"
println(results[1]);
// will print "task2"| results will be aggregated according to the order declared in the dependency list. Consequently, if the xml depends tag of task3 contains the list [task1, task2] (see the xml example below), then results[0] will contain the result of task1 and results[1] the result of task2. On the contrary, if the depends list is [task2, task1], then results[0] will contain the result of task2 and results[1] the result of task1. |
<depends>
<task ref="task1"/>
<task ref="task2"/>
</depends>For nearly all script languages, the results variable contains a list of TaskResult java object. In order to access the result value, the value() method of this object must be called. Example for Python/Jython:
print results[0].value()5.8.1. Assigning metadata to task result
Result metadata can contain additional information associated with the result. In order to store metadata information, you have to use the resultMetadata script binding. As for the result binding, the resultMetadata value of a task is available in its child tasks.
// task1
result = "task1";
resultMetadata.put("mymetadata", "myvalue")// task2
println(results[0].getMetadata());It is the user code which specifies the metadata semantics. However, some specific metadata can have a meaning when downloading or previewing results from the Scheduler portal
-
file.name: the name of the file, including the extension, which will be used when storing the result in binary format.
// fileNameTask file = new File("balloon13.png") result = file.getBytes() resultMetadata.put("file.name","balloon13.png") -
file.extension: the extension, which will be appended to the automatically generated name, when storing the result in binary format
// fileExtensionTask file = new File("balloon13.png") result = file.getBytes() resultMetadata.put("file.extension",".png") -
content.type: the display format, which will be used when previewing the file in the browser. Open the following link for the complete list of mime-types.
// contentTypeTask file = new File("balloon13.png") result = file.getBytes() resultMetadata.put("content.type","image/png")
A Task result can be added to the list of results of a Job, see section Result List below.
| The specific result metadata described above can also be set using Generic Information. For example, defining the generic information content.type = text/html is equivalent to adding this value to the resultMetadata map. |
5.9. Job Results
Job Results are composed of two elements: Result List and Result Map. Each task can contribute to both. Once the job is finished, the user can download/visualize Job Results from the Scheduler portal as shown in screenshot below. The label in Result List corresponds to the task name that generated the value.
5.9.1. Result List
Each task has its own result (see section Task result). Some of intermediate task results may be precious such that the user would like to access them easily at the job level. To do that, the user has to select precious task(s) and check the Task Result Added to Job Result checkbox as shown in the screenshot below. In that case, the task result will be added to the Result List when the job execution is finished.
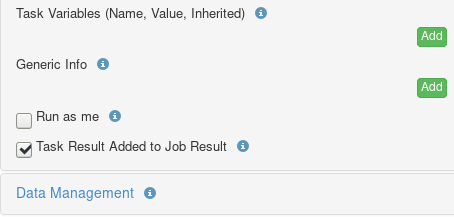
In the Job xml schema it is available as preciousResult:
<task name="Init_Task" preciousResult="true" >5.9.2. Result Map
In addition to the Results List, a Job can also store some results into a dedicated key-value map, which is called Result Map. Every task can contribute to this Result Map. It is a write-only map, in such a way that a task cannot see what other tasks already wrote to the result map. When several tasks write the same key to the result map, the last write always takes precedence. This map contains String as a key, and Serializable as value.
Consider the following groovy example.
Task 1 writes to Result Map:
resultMap.put("filename", "results.txt")
resultMap.put("latestError", "no error")Task 2 writes to Result Map:
resultMap.put("latestError", "wrong user id")Once the job is finished, Result Map would contain:
"filename" -> "results.txt"
"latestError" -> "wrong user id"5.10. Control Flow Scripts
To perform a control flow action such as if, replicate or loop, a Control Flow Script is executed on the ProActive node. This script takes the result of the task as input; meaning a Java object if it was a Java or Script task, or nothing if it was a native task.
The script is executed on the ProActive node, just after the task’s
executable. If the executable is a Java Executable and returns a result,
the variable result will be set in the script’s environment so that
dynamic decisions can be taken with the task’s result as input. Native
Java objects can be used in a Groovy script.
loop = resultSimilarly to how parameters are passed through the result variable to the script, the script needs to define variables specific to each action to determine what action the script will lead to.
-
A replicate control flow action needs to define how many parallel runs will be executed, by defining the variable
runs:
// assuming result is a java.lang.Integer
runs = result % 4 + 1The assigned value needs be a strictly positive integer.
-
An if control flow action needs to determine whether the if or the else branch is selected, it does this by defining the boolean variable
branch:
// assuming result is a java.lang.Integer
if (result % 2) {
branch = "if"
} else {
branch = "else"
}The assigned value needs to be the string value if or else.
-
The loop control flow action requires setting the
loop, which will determine whether looping to the statically defined target is performed, or if the normal flow is executed as would a continue instruction do in a programming language:
loop = result as BooleanThe assigned value needs to be a boolean.
Failure to set the required variables or to provide a valid control flow script will not be treated gracefully and will result in the failure of the task.
5.11. Loop and Replicate awareness
When Control Flow actions such as replicate or loop are performed, some tasks are replicated. To be able to identify replicated tasks uniquely, each replicated task has an iteration index, replication index, and a tag. In addition to help to identify uniquely, these tags are useful to filter tasks by iterations for example.
5.11.1. Task name
First, those indexes are reflected inside the names of the tasks themselves. Indeed, task names must be unique inside a job. The indexes are added to the original task name as a suffix, separated by a special character.
-
If a task named T is replicated after a loop action, the newly created tasks will be named T#1, T#2, etc. The number following the # separator character represents the iteration index.
-
The same scheme is used upon replicate actions: newly created tasks are named T*1, T*2, and so on. The number following the * separator represents the replication index.|
-
When combining both of the above, the resulting task names are of the form: T#1*1, T#2*4, etc., in that precise order.
5.11.2. Task tag
Tags are assigned automatically by the scheduler when a task is created by replication from another task. They are designed to reflect the task that initiated the replication for the first time, the type of replication (loop or replicate) and the iteration index or replication indexes. So the tag is formed like this: (LOOP|REPLICATE)-Name_of_the_initiator-index.
-
If the task T1 initiates a loop that contains the tasks T2 and T3, then the tasks T2#1 and T3#1 will have the tag LOOP-T1-1. The tasks T2#2 and T3#2 will have the tag LOOP-T1-3.
-
If the loop is a cron loop, the index is replaced by the resolved time of the initiated looping. For example, in a cron loop that was initiated the 21/12/2015 at 14h00, the task T1#1 will have the tag LOOP-T1#1-21_12_15_14_00.
-
If the task T1 replicates a block that contains the tasks T2 and T3, then the tasks T2*1 and T3*1 will have the tag REPLICATE-T1-1. The tasks T2*2 and T3*2 will have the tag REPLICATE-T1-2.
-
If the task T1#1, inside a loop, replicates tasks, the new tasks will have the tags REPLICATE-T1#1-1, REPLICATE-T1#1-2, etc…
-
If the replicated task T1*1 initiates a loop inside a replicate, the new created tasks will have the tags LOOP-T1*1-1, LOOP-T1*1-2, etc…
5.11.3. Task definition
Those indexes are also available as workflow variables. They can be obtained using the variable names:
-
PA_TASK_REPLICATION
-
PA_TASK_ITERATION
Here is how to access those variables:
-
Native Executable arguments:
<staticCommand value="/path/to/bin.sh">
<arguments>
<argument value="/some/path/${PA_TASK_ITERATION}/${PA_TASK_REPLICATION}.dat" />-
Dataspace input and output:
<task name="t1" retries="2">
<inputFiles>
<files includes="foo_${PA_TASK_ITERATION}_${PA_TASK_REPLICATION}.dat" accessMode="transferFromInputSpace"/>
</inputFiles><outputFiles>
<files includes="bar_${PA_TASK_ITERATION}_${PA_TASK_REPLICATION}.res" accessMode="transferToOutputSpace"/>| Scripts affected by the variable substitutions are: Pre, Post, Control Flow. No substitution will occur in selection scripts or clean scripts. |
5.11.4. Task executable
The iteration and replication indexes are available inside the executables launched by tasks.
In script tasks, the indexes are exported through the following workflow variables:
PA_TASK_ITERATION and PA_TASK_REPLICATION.
int it = variables.get("PA_TASK_ITERATION")
int rep = variables.get("PA_TASK_REPLICATION")In a similar fashion, environment variables are set when launching a
native executable: PAS_TASK_ITERATION and PAS_TASK_REPLICATION:
#!/bin/sh
myApp.sh /path/to/file/${variables_PAS_TASK_ITERATION}.dat5.12. Example: Embarrassingly Parallel problem
An Embarrassingly Parallel problem is a problem that is easy to split into smaller independent tasks. With ProActive Scheduler you can tackle this type of problem with the Replicate construct.
| Familiar with MapReduce? Well, a workflow using replication uses similar concepts. |
The Advanced workflows is an example of an embarrassingly parallel problem where the computation is easily distributed across ProActive Nodes.
5.13. Example: MPI application
MPI is often used in the area of parallel computing. The Scheduler integrates with MPI with the concept of multi node tasks. This particular task will acquire several nodes and will expose these nodes to the MPI environment.
Applications built with MPI are often executed using the mpirun command. It accepts several parameters to choose how many CPUs and how many machines will be used. One particular parameter is the machine file that is built by the Scheduler when using multi node tasks. Here is how an MPI application invocation would look like when executed with the Scheduler:
mpirun -hostfile $variables_PA_NODESFILE myApplication
The variable $variables_PA_NODESFILE contains the path to a machine file created by the Scheduler that will be similar to:
compute-host compute-host another-host
Meaning that myApplication will use 2 CPUs on compute-host and 1 CPU on another-host.
You can also use $variables_PA_NODESNUMBER to retrieve the number of acquired nodes.
You can find an example of a native task in this XML workflow or you can also build one yourself using the Workflow Studio.
To achieve the best performance for MPI applications, nodes can be selected taking into account their network topology. One might want to select nodes that are as close to each other as possible to obtain better network performance or nodes on different hosts to split the I/O load. Refer to Topology Types for more details.
5.14. Example: Install specific software tools and libraries before launching tasks
Some workflow tasks require the prior installation of specific software tools and libraries that are necessary to properly execute these tasks. ProActive offers two methods to enable the installation of such tools and libraries:
-
By using software containers encapsulating the required libraries and tools. ProActive enables then the execution of computational tasks in containers such as Docker, Podman or Singularity containers. See Section Fork environment for more details about executing tasks inside software containers.
-
By using pre-scripts, i.e., scripts that are executed just before the considered computational task, and on the same compute resource. Such pre-scripts implement the instructions for installing and configuring the required tools and libraries. ProActive solution allows writing pre-scripts in various languages. These include languages for operating systems (shell, batch, powershell, etc.), scripting languages (groovy, javascript, etc.) and programming languages (python, java, etc.). See Section Pre, Post & Clean Scripts for more details about pre-scripts.
6. Workflow Execution Control
ProActive Scheduler supports portable script execution through the JSR-223 Java Scripting capabilities. Scripts can be written in any language supported by the underlying Java Runtime Environment.
They are used in the ProActive Scheduler to:
-
Execute some simple pre, post and cleaning processing (pre scripts, post scripts and cleaning scripts)
-
Select among available resources the node that suits the execution (selection scripts).
6.1. Selection of ProActive Nodes
6.1.1. Selection Scripts
A selection script provides an ability for the Scheduler to execute tasks on particular ProActive nodes. E.g. you can specify that a task must be executed on a Unix/Linux system.
A selection script is always executed before the task itself on any candidate node:
the execution of a selection script must set the boolean variable selected,
that indicates if the candidate node is suitable for the execution of the associated task.
A Java helper org.ow2.proactive.scripting.helper.selection.SelectionUtils is provided for allowing
user to simply make some kind of selections. Some script samples are available in
PROACTIVE_HOME/samples/scripts/selection.
The following example selects only nodes running on Windows:
importClass(org.ow2.proactive.scripting.helper.selection.SelectionUtils);
/* Check if OS name is Windows */
if (SelectionUtils.checkOSName("windows")) {
selected = true;
} else {
selected = false;
}You can use variables inside the selection script, these variables must be visible within the task context, i.e., declared on job scope, on task scope, or result variable from a previous task. In the last case, it is mandatory that the task which declares the inherited variable precedes the task using the variable. Below is an example job in XML format which uses a task variable to select Unix/Linux as operating system. In this example, variable operating_system (task scope) resolves to variable operating_system_workflow (job scope).
<?xml version="1.0" encoding="UTF-8"?>
<job
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="urn:proactive:jobdescriptor:3.10"
xsi:schemaLocation="urn:proactive:jobdescriptor:3.10 https://www.activeeon.com/public_content/schemas/proactive/jobdescriptor/3.10/schedulerjob.xsd"
name="variable solving"
priority="normal"
onTaskError="continueJobExecution"
maxNumberOfExecution="2"
>
<variables>
<variable name="operating_system_workflow" value="linux" model=""/>
</variables>
<taskFlow>
<task name="Groovy_Task0">
<description>
<![CDATA[ The simplest task, ran by a groovy engine. ]]>
</description>
<variables>
<variable name="operating_system" value="$operating_system_workflow" inherited="false" />
</variables>
<scriptExecutable>
<script>
<code language="groovy">
<![CDATA[
import org.ow2.proactive.scripting.helper.selection.SelectionUtils
selected = SelectionUtils.checkOSName(variables.get("operating_system"))
]]>
</code>
</script>
</scriptExecutable>
</task>
</taskFlow>
</job>6.1.2. Generic Information
A few Generic Information allow to control where the associated task will be executed:
-
NODE_ACCESS_TOKEN: the task will be executed only on Nodes which have the specified token. A node token is defined as a parameter of a Node Source Policy.
-
NODE_SOURCE: the task will be executed only on Nodes which belong to the specified Node Source.
6.2. Fork environment
A fork environment is a new forked Java Virtual Machine (JVM) which is started exclusively to execute a task. For example, this task may need to use some third-party libraries, so it can be executed properly. In this example, the list of path elements to be added when starting a new JVM will be specified inside the Additional Classpath field.
Starting a new JVM means that the task inside it will run in a dedicated, configurable environment.
6.2.1. Fork environment modes
The fork environment can be activated through one of these four executions modes:
-
Standard forked mode,
-
Fork mode with customized configuration,
-
Run as me mode,
-
Fork mode with docker.
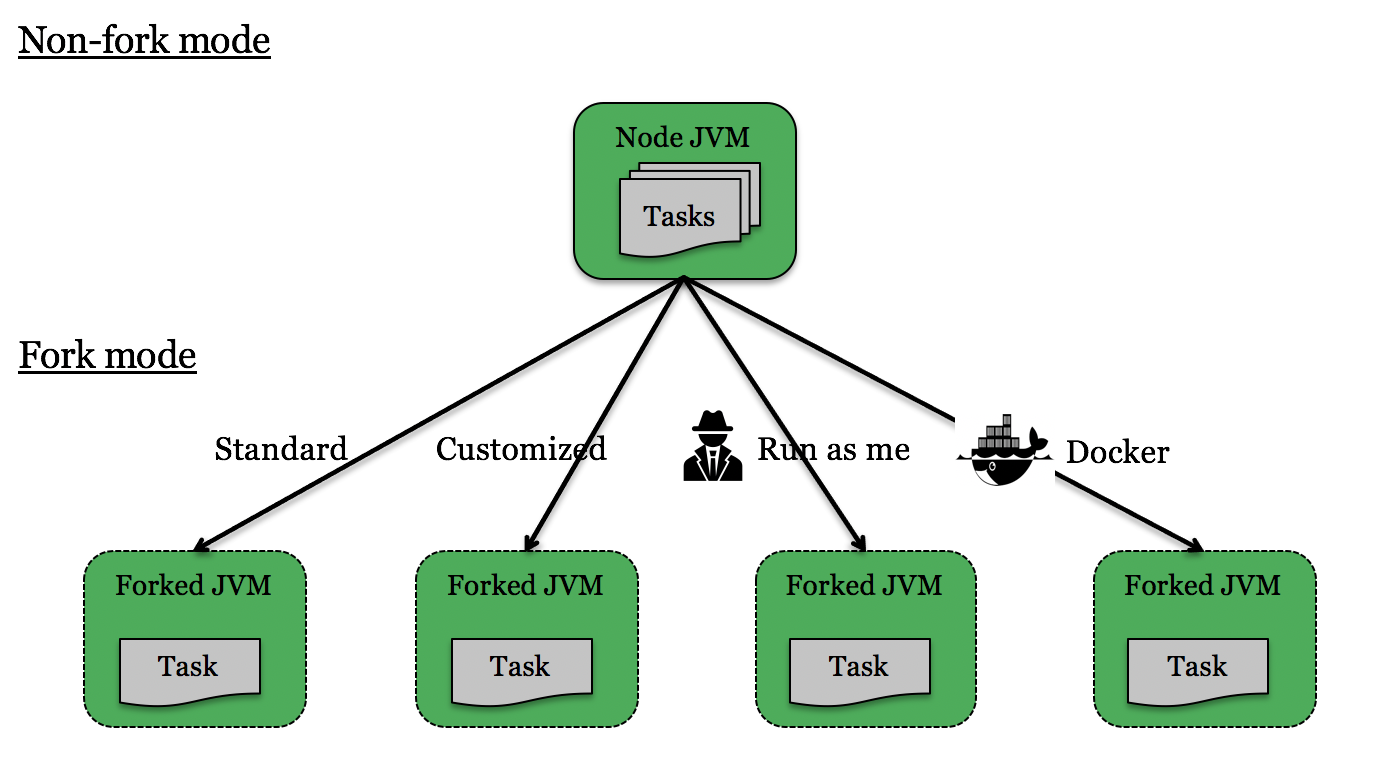
By default, all workflow tasks are executed in a standard fork mode, that is, executed in a forked JVM separated from the ProActive Node’s JVM.
This behavior can be controlled globally at the ProActive server level by modifying the global setting pa.scheduler.task.fork in the scheduler configuration file and also locally at the task level via the optional checkbox property Fork.
-
In case the server is configured in non-fork mode (i.e.
pa.scheduler.task.fork=false), the checkbox property Fork is unchecked and uneditable and all the fields under Fork Environment are uneditable. -
In case the server is configured in a fork mode (i.e.
pa.scheduler.task.fork=true), the checkbox property Fork is checked and uneditable and all the fields under Fork Environment are editable. -
In case the global setting is not set (i.e. comment out the related configuration through
#pa.scheduler.task.fork=true), each task can specify its execution mode through the checkbox property Fork. If the checkbox property Fork is unchecked, then all the other fields under Fork Environment are disabled.
6.2.2. Fork environment customization
The fork execution environment mechanism can be customized by writing a fork environment script.
This script contains a specific script binding called forkEnvironment containing a ForkEnvironment java object
giving access to various configuration settings.
For example, the following fork environment groovy script can be written to change the working directory of the task, and the path to the java executable:
forkEnvironment.setWorkingDir("/data/folder")
forkEnvironment.setJavaHome("/usr/java/default")6.2.3. Environment cleanup
After a task is executed, an internal mechanism called the Process Tree Killer ensures that all children processes started by the task are automatically terminated. This mechanism is explained in details in the Task Termination Behavior section.
The Process Tree Killer mechanism can be disabled using the DISABLE_PTK generic information.
6.2.4. Docker fork execution environment
A Docker fork execution environment is a specific usage of the fork environment mechanism. In that case, the ProActive Node’s JVM starts a docker container which will run the forked JVM described above. This forked JVM can be customized by the JVM settings and by the tool-set and isolation provided by Docker containers.
| If your task needs to install new software or updates software, then run it inside a Docker container. That way, other tasks will not be affected by changes, because Docker containers provide isolation so that the host machine’s software stays the same. |
The simplest way to use a Docker fork execution environment
From the Studio Portal, when editing a workflow task, open the Fork Environment section, and select Docker in the Fork Execution Environment Dropdown.
A sample Docker environment script will appear.
These settings ensure, that the current task is executed inside a Docker container, or fail if Docker is not installed or the user has no permission to run Docker containers.
| If the executing Node has no Docker installed, the task will fail. A selection script can ensure that tasks are executed only on Nodes which have Docker installed. |
Docker fork environment script
The default Docker fork environment script contains the following groovy code:
// This script creates a docker fork environment using java as docker image
// If used on windows:
// - currently, only linux containers are supported
// - make sure the drives containing the scheduler installation and TEMP folders are shared with docker containers
// - the container used must have java installed by default in the /usr folder. Change the value of the java home parameter to use a different installation path
// On linux, the java installation used by the ProActive Node will be also used inside the container
// Prepare Docker parameters
import org.ow2.proactive.utils.OperatingSystem;
import org.ow2.proactive.utils.OperatingSystemFamily;
dockerImageName = "java"
cmd = []
cmd.add("docker")
cmd.add("run")
cmd.add("--rm")
cmd.add("--env")
cmd.add("HOME=/tmp")
String osName = System.getProperty("os.name");
println "Operating system : " + osName;
OperatingSystem operatingSystem = OperatingSystem.resolveOrError(osName);
OperatingSystemFamily family = operatingSystem.getFamily();
switch (family) {
case OperatingSystemFamily.WINDOWS:
isWindows = true;
break;
default:
isWindows = false;
}
forkEnvironment.setDockerWindowsToLinux(isWindows)
// Prepare ProActive home volume
paHomeHost = variables.get("PA_SCHEDULER_HOME")
paHomeContainer = (isWindows ? forkEnvironment.convertToLinuxPath(variables.get("PA_SCHEDULER_HOME")) : variables.get("PA_SCHEDULER_HOME"))
cmd.add("-v")
cmd.add(paHomeHost + ":" + paHomeContainer)
// Prepare working directory (For Dataspaces and serialized task file)
workspaceHost = localspace
workspaceContainer = (isWindows ? forkEnvironment.convertToLinuxPath(workspaceHost) : workspaceHost)
cmd.add("-v")
cmd.add(workspaceHost + ":" + workspaceContainer)
cachespaceHost = cachespace
cachespaceContainer = (isWindows ? forkEnvironment.convertToLinuxPath(cachespaceHost) : cachespaceHost)
cmd.add("-v")
cmd.add(cachespaceHost + ":" + cachespaceContainer)
if (!isWindows) {
// when not on windows, mount and use the current JRE
currentJavaHome = System.getProperty("java.home")
forkEnvironment.setJavaHome(currentJavaHome)
cmd.add("-v")
cmd.add(currentJavaHome + ":" + currentJavaHome)
}
// Prepare container working directory
cmd.add("-w")
cmd.add(workspaceContainer)
if (isWindows) {
// linux on windows does not allow sharing identities (such as AD identities)
} else {
sigar = new org.hyperic.sigar.Sigar()
try {
pid = sigar.getPid()
creds = sigar.getProcCred(pid)
uid = creds.getUid()
gid = creds.getGid()
cmd.add("--user=" + uid + ":" + gid)
} catch (Exception e) {
println "Cannot retrieve user or group id : " + e.getMessage()
} finally {
sigar.close()
}
}
cmd.add(dockerImageName)
forkEnvironment.setPreJavaCommand(cmd)
// Show the generated command
println "DOCKER COMMAND : " + forkEnvironment.getPreJavaCommand()This script exports a variable composed of a list of command + arguments via the forkEnvironment.getPreJavaCommand function, which is picked up by the Node executing the Task. This variable is supposed to be a Docker run command inside a string. This string will be split by space and added in front of the fork execution command. As an example:
/usr/bin/java -cp [Classpath] [ExecutedClass]
And the Docker run command is:
docker run java
Then both will be combined to:
docker run java /usr/bin/java -cp [Classpath] [ExecutedClass]
The combined command will execute a JVM inside a docker container. Internally the command is split into docker, run, java, /usr/bin/java, -cp, [Classpath], [ExecutedClass]. That is important to know because the fork execution command is split by spaces. That means, that paths can’t contain spaces. The Docker container mounts the ProActive home and a folder in the temp directory of the operating system. Those cannot contain spaces, because if they do then the fork execution command will be split wrong and fail.
6.3. Pre, Post & Clean Scripts
Another functionality is the possibility to define pre and post scripts. For a given task (Java, Script or Native task), it is possible to launch a script before and after its execution. This possibility can be useful to copy files to a node, or clean a directory before or after task execution, for example.
This is a way to separate from business code the preparation of execution environment and its cleaning. A good example is a script that removes files from a specific directory once the task is finished.
Files.deleteIfExists(new File("/tmp/working_dir/").toPath())6.3.1. File transfer
Input/Output Data in Shared Directory
The easiest way to use your data on computing machines is to set up a shared directory available on all Compute Hosts. For Linux it’s typically an NFS directory, for Windows it could be an SMB network share. Then, in tasks you can manipulate files seamlessly across ProActive Nodes.
File inputData = new File("/data/username/inputfile");This approach has some limitations though:
-
The path to the shared folder should be identical on all Compute Hosts
-
It can be difficult to use with heterogeneous resources, e.g. Linux and Windows hosts
6.3.2. Save script
Save the pre-script in a file and skip its execution
Instead of executing a task pre-script, we also provide a way to save the pre-script into a file and skip its execution.
To do so, a Generic Information is required for the desired task, with the key
PRE_SCRIPT_AS_FILE, and the path of the file that you want to save your pre-script as its value.
The path should contain a file name. If it is an absolute path, then the file will be stored in this absolute path. If it is a relative path, then the file will be stored in the Local Space.
If you don’t give a specific extension in the path, the extension will be automatically assigned to the corresponding one of the language selected for this pre-script.
6.4. Run Computation with a user’s system account
When workflow tasks are executed inside a ProActive Node, they run by default under the system account used to start the Node.
The RunAsMe mode, also called user impersonation, allows to start a workflow Task either:
-
under the job owner system account (default RunAsMe).
-
under a specific system account (RunAsUser).
The RunAsMe mode is defined in the XML representation of a Task:
<task name="Linux_Bash_Task"
fork="true"
runAsMe="true" >
<description>
<![CDATA[ A task, ran by a bash engine. ]]>
</description>
<scriptExecutable>
<script>
<code language="bash">
<![CDATA[
whoami
]]>
</code>
</script>
</scriptExecutable>
</task>In the ProActive Studio, the RunAsMe mode is available in the Task Properties Fork Environment section.

In order to impersonate a user, RunAsMe can use one of the following methods:
-
PWD: impersonate a user with a login name and password (this is the default, it is also the only mode available on Windows Nodes).
-
KEY: impersonate a user with a login name and SSH private key.
-
NONE: impersonate a user with a login name and sudo.
The above modes are defined by the ProActive server administrator when ProActive Nodes are deployed. It is possible to define for each Node a different RunAsMe mode. The underlying operating system need to be configured appropriately in order to impersonate a task.
See RunAsMe section in the administration guide for further information.
The default mode for RunAsMe is to impersonate as the current user with the user login and password. Accordingly, the user’s login and password inside ProActive must match the login and password of the user in the target machine’s operating system.
It is possible though to impersonate through a different user, using a different password, or even using a different impersonation method as the one configured by default.
This possibility is given by adding Generic Information described in the below table to the workflow task. Each of these generic information can be defined both at task-level or job-level. When at job-level, it will apply to all tasks of this workflow with RunAsMe enabled. Other tasks without RunAsMe enabled will ignore these generic information.
| Name | Description | Example value |
|---|---|---|
|
Allows overriding the impersonation method used when executing the task. Can be |
|
|
Allows overriding the login name used during the impersonation. This allows to run a task under a different user as the user who submitted the workflow. |
bob |
|
Allows defining or overriding a user domain that will be attached to the impersonated user. User domains are only used on Windows operating systems. |
MyOrganisation |
|
Allows overriding the password attached to the impersonated user. This can be used only when the impersonation method is set to |
MyPassword |
|
Similar to RUNAS_PWD but the password will be defined inside Third-party credentials instead of inlined in the workflow. This method of defining the password should be preferred to RUNAS_PWD for security reasons. The value of RUNAS_PWD_CRED must be the third-party credential name containing the user password. |
MyPasswordCredName |
|
Allows overriding the SSH private key attached to the impersonated user. This can be used only when the impersonation method is set to |
MySSHKeyCredName |
6.5. Reserve more than one node for a task execution
To create a multi-nodes execution (often used for MPI applications), you need to add a parallel environment to the task definition. Parallel environment describes how many nodes are needed for a task execution as well as where these nodes should be located. Thus, in addition to the number of ProActive Nodes, you can specify the nodes network topology, e.g the set of nodes within some latency threshold, nodes on the same host and many more.
Here is the list of topologies we support:
-
Arbitrary topology does not imply any restrictions on nodes location
-
Best proximity - the set of closest nodes among those which are not executing other tasks.
-
Threshold proximity - the set of nodes within a threshold proximity (in microseconds).
-
Single Host - the set of nodes on a single host.
-
Single Host Exclusive - the set of nodes of a single host exclusively. The host with selected nodes will be reserved for the user.
-
Multiple Hosts Exclusive - the set of nodes filled in multiple hosts. Hosts with selected nodes will be reserved for the user.
-
Different Hosts Exclusive - the set of nodes each from a different host. All hosts with selected nodes will be reserved for the user.
For instance, if a user wants to run 4 processes in parallel inside the scope of one task and in the same compute host, then she/he should specify that in the Multi-Nodes Execution section as shown in the following screenshot.
In the Job xml schema, the multi-nodes execution is available at the parallel tag
<parallel numberOfNodes="4">
<topology>
<singleHostExclusive/>
</topology>
</parallel>6.6. Error Handling
It’s possible to have errors when your Job is executed. ProActive Scheduler provides several mechanisms to deal with exceptional situations in your Jobs. If a Task contains errors during Job execution, the ProActive Scheduler automatically restarts this Task. The number of automatic restarts is defined by the Workflow owner by assigning an integer value to the counter Number of Automatic Restarts. The user also defines Where he wants that the scheduler restarts In-Error tasks, i.e., on the same ProActive Node or on another ProActive Node.
If automatic restarts does not fix errors, the Scheduler applies one of the following Task error management policies, i.e., the one defined by the user during Workflow creation:
-
Level 0 - Default: Ignore Error and continue Job execution:
Each In-Error Task inside the Job transits to Faulty and its successor Tasks are executed.
-
Level 1 - In-Error: Continue Job execution, but suspend error-dependent Tasks:
Successor Tasks of each In-Error Task are Pending until errors are fixed. The Job is in In-Error status. The user can restart In-Error Tasks as many times as he wishes.
-
Level 2 - Pause: Continue running Tasks, and suspend all others:
Successor Tasks of each In-Error Task are paused until errors are fixed. The Job is paused. The user can restart In-Error Tasks as many times as he wishes.
-
Level 3 - Cancel: Running Tasks are aborted, and others not started:
The Job is canceled with all Tasks.
Error handling policy can be set globally on the job level, and also can be specified (overridden) individually for each Task.
6.6.1. Maximum execution time for a task
A timeout (also known as walltime) can be set at the task’s level to stop a task’s execution when the timeout is reached.
This timeout is defined as an attribute of the task element, for example:
<task name="Task_Walltime"
fork="true"
walltime="12:00">
...
</task>The general format of the walltime attribute is [hh:mm:ss], where h is hour, m is minute and s is second.
The format still allows for more flexibility. We can define the walltime simply as 5 which corresponds to
5 seconds, 10 is 10 seconds, 4:10 is 4 minutes and 10 seconds, and so on.
The walltime mechanism is started just before a task is launched. If a task does finish before its walltime, the mechanism is canceled. Otherwise, the task is terminated. Note that the tasks are terminated without any prior notice.
The walltime can also be configured using the WALLTIME Generic Information. The syntax of this generic information is similar to the task walltime attribute.
The interest of using a generic information rather than a task attribute is that the WALLTIME generic information, if defined at job-level, can be applied to all tasks of a workflow.
|
When used at job-level, the configured walltime will not be applied to the workflow globally but to each individual task of the workflow. For example, if the walltime is configured at job-level to be ten minutes, each task of the workflow can run no more than ten minutes, but the workflow itself has no time limitation. |
Finally, an administrator can configure the walltime globally at the scheduler server level. To do so, in PROACTIVE_HOME/config/scheduler/settings.ini, the property pa.scheduler.task.walltime must be defined with a global walltime.
For example, to define a global walltime of one hour:
pa.scheduler.task.walltime=1:00:00
As the walltime can be configured in multiple ways, an order or priority applies to the various configuration (from highest to lowest priority):
-
Walltime configured as a task attribute
-
Walltime configured as generic information
-
Walltime configured globally at the scheduler-level.
This order of priority ensures that a user can easily override a larger scope configuration.
6.7. Cron Workflows
The ProActive Scheduler allows to schedule Workflows with the Job Planner. Find more information in the Job Planner User Guide.
6.8. Cron Tasks
ProActive Scheduler supports the execution of time-based tasks or cron tasks. The users can assign a
cron expression to the loop variable of a Loop in a ProActive Job. All tasks which belong
that Loop will be executed iteratively and indefinitely. The start time of the next iteration
is the next point of time specified by the cron expression.
6.8.1. Cron Expression Syntax
The syntax of the follows the UNIX crontab pattern, a string consists of five space-separated segments. Please refer cron4j documentation for further details.
6.8.2. Setting up Cron Tasks
Setting up a cron task requires two steps:
-
Define a Loop with the desired cron tasks
-
Assign a cron expression as the
loopvariable value
Example that prints Hello every 10 minutes:
<job name=”cron_job”>
<genericInformation>
<info name="START_AT" value="2014-01-01T00:00:00+01:00"/>
</genericInformation>
<task name=”cron_task”>
<scriptExecutable>
<script>
<code language="javascript">
print("Hello");
</code>
</script>
</scriptExecutable>
<controlFlow>
<loop target=”cron_task”>
<script>
loop = “10 * * * *”
</script>
<loop>
</controlFlow>
</task>
</job>You can find a complete example running a simple task every minutes in this XML workflow.
6.8.3. Notes
-
The execution of the first iteration occurs immediately and does not depend on the cron expression specified. However the user can specify a start time for the first iteration using
START_ATgeneric information. Its value should be ISO 8601 compliant. -
Each iteration yields one or more task results and the user can query the job status and task status to retrieve information of each iteration.
-
It is assumed that execution time of each iteration is less that time gap specified by the cron expression. If the execution time of an iteration is longer, the execution of the next iteration will occur at next point of time with respect to the current time. For instance it is possible to observe lesser number of iteration executed within a certain time period than number of expected iterations, if some iterations had take longer finish time.
-
If the execution of the task defining the loop (where the <controlFlow> block is defined) fails, the cron execution is terminated.
-
ProActive Scheduler executes any cron task indefinitely. Therefore the status of ProActive Job will remain
RUNNINGunless the cron task execution terminates either by the user (for instance by killing the job or the task) or due an error in the task execution.
6.9. Remote Visualization
Using the Scheduler Web Interface, it is possible to access the display of the ProActive Node running a given task. First remote visualization must be activated via the Scheduler configuration files (set novnc.enabled to true).
| Remote visualization works via VNC where the REST API will connect to the node running the task, i.e a graphical application. The VNC output will be forwarded to the your browser and you will be able to interact with the application. |
The task that you want to visualize must output a special string using the following format: PA_REMOTE_CONNECTION;JOB_ID;TASK_ID;vnc;HOSTNAME:PORT where JOB_ID must be the current job id, TASK_ID the current task id and HOSTNAME:PORT the hostname and port where the VNC server runs.
It is the task’s responsibility to print the string. Here is a sample script that starts a Xvnc server and runs a graphical application. It can be used in a native task for instance.
In the Scheduler Web Interface, select the running job and use the Preview tab to enable remote visualization.
| Since it runs a graphical application, the task will never exit and run forever. The common use case is that you want to check manually some results via the graphical application and then exit the application. The task will then terminate normally. |
6.10. Troubleshoot a Workflow Execution
When a task has IN_ERROR status, a right click on it allows the user to select Mark as finished and resume. This will set the task status as FINISHED and then resume job execution: this task won’t be executed again, subsequent tasks will execute as if the task executed correctly. This allows the user to manually perform actions to the IN_ERROR task, without cancelling the whole job execution.
If the task has not IN_ERROR status, the Mark as finished and resume option will be in grey, meaning that the action is disabled.
6.11. Get Notifications on Job Events
Add a "NOTIFICATION_EVENTS" Generic information in the workflow level, to list events on which a user wants to be notified. List is comma-separated and should be taken from(events are not case sensitive):
-
Job change priority (or JOB_CHANGE_PRIORITY)
-
Job In-Error (or JOB_IN_ERROR)
-
Job paused (or JOB_PAUSED)
-
Job pending to finished (or JOB_PENDING_TO_FINISHED)
-
Job pending to running (or JOB_PENDING_TO_RUNNING)
-
Job restarted from error (or JOB_RESTARTED_FROM_ERROR)
-
Job resumed (or JOB_RESUMED)
-
Job running to finished (or JOB_RUNNING_TO_FINISHED)
-
Job submitted (or JOB_SUBMITTED)
-
Job running to finished with errors (or JOB_RUNNING_TO_FINISHED_WITH_ERRORS)
-
Job aborted (or JOB_ABORTED)
Scheduler can send email to the users when one of the above events is received.
If a user wants to be notified by all these events, the "NOTIFICATION_EVENTS" Generic information should have "All" (not case sensitive) as its value.
Notifications will only be sent for jobs whose generic information (workflow level) contains user’s email address(es) under the "EMAIL" key, if multiple email addresses need to be used, they should be separated by comma. Example:
<genericInformation>
<info name="EMAIL" value="user0@example.com, user1@example.com"/>
<info name="NOTIFICATION_EVENTS" value="Job paused, Job resumed"/>
</genericInformation>To enable this functionality, the configuration need to be done following the steps introduced in Get Notification on Job Events Configuration.
6.12. Chaining Workflows: Submit a Workflow from another Workflow
In ProActive Studio, the SubmitJobNoWait and SubmitJobAndWait templates under the Controls menu allow you to submit a workflow from another workflow using the schedulerapi binding.
These templates accept the single parameter:
-
called_workflow: a ProActive Catalog path where the syntax is checked by the PA:CATALOG_OBJECT model. The path must be a valid expression that matches the following pattern:bucketName/workflowName[/revision]referencing the workflow to submit from the Catalog (e.g. basic-examples/Native_Task). In case one wants to promote the variablecalled_workflowat the level of the Workflow in order to be able to select the submitted Workflow at submission time, he just has to duplicate the variable at the Workflow level and mark the one at the Task level as inherited.
By default, these templates do not pass any parameter to the submitted workflow (using only default values provided by the workflow).
It is possible to modify this behavior by changing the SubmitJobNoWait or SubmitJobAndWait implementation.
For example, the following line can be replaced:
workflow_variables = Collections.EMPTY_MAPby
workflow_variables = [firstName:'John', lastName:'Doe']To provide the firstName and lastName variables parameters to the submitted workflows.
The SubmitJobNoWait or SubmitJobAndWait templates behavior is different in the sense that the latter will wait until the submitted workflow terminates.
In case an error occurs in the chained jobs, a user may want to escalate this error from the submitted (child) job to the parent job by throwing an exception. It is possible to integrate this behavior in the SubmitJobAndWait implementation using the schedulerapi binding as described in the code below.
jobid = variables.get("jobID")
jobState = schedulerapi.getJobState(jobid)
jobStatus = jobState.getStatus().toString().toUpperCase()
isJobSuccessful = !(jobStatus.equals("FAILED") || jobStatus.equals("CANCELED") || jobStatus.equals("KILLED") || (jobStatus.equals("FINISHED") && jobState.getNumberOfFaultyTasks() > 0))
if (isJobSuccessful) {
println("Submitted job id=" + jobid + " (" + variables.get("called_workflow") + ") has been successfully run")
} else {
throw new IllegalStateException("Submitted job id=" + jobid + " (" + variables.get("called_workflow") + ") has failed. The error is escalated to the parent job.")
}6.13. Control and Validations
Web Validations and Email Validations are two Tasks available in the Studio’s control-notification Bucket.
When the Workflow’s execution flow reaches one of these Tasks, the Job is paused, emails are sent if necessary and a Validation is created in the Notification Portal.
From there, the Job remains in pause until an authorized user or user group performs an action on the Validation.
A Web Validation defines:
-
A message: The associated message readable by all notified users.
-
A severity: The associated severity. Can be CRITICAL, ERROR, WARNING or INFO.
-
The Job submitter authorization: If the user who submits the job is authorized to perform an action on the Validation.
-
Authorized users: A comma separated list of users (login names) who will be notified and able to process the Validation.
-
Authorized groups: A comma separated list of groups who will be notified and able to process the Validation.
Email Validations define an extra field called Emails which holds a comma separated list of emails.
Each provided email will be notified that a Validation is pending. The email contains a link to the Notification Portal
where the user can perform an action on the Validation.
Authorized users may perform three types of actions on a Validation:
-
Yes: The Job will resume.
-
No: The Job will be killed.
-
Abstain: The Job will remain paused. Another user must process the Validation.
All actions are final for each user. A user cannot modify his response. Once a Validation receives a Yes or No action, the Validation is considered processed and no future actions can be done by any user.

6.14. Adding Labels to Jobs
A label is a property that can be attached to a job, and changed dynamically by end-users. The Labels give the possibility to tag Jobs, group them and manipulate them by filtering based on these custom labels. These Labels act as a custom status for the Jobs. For example, a company can label jobs which are having errors to be reviewed by operators (label "to-be-reviewed"), and later mark them as "reviewed" when done. Job labels can be used for this specific purpose, but for any other purpose.
Before being able to use labels for Jobs, an Administrator has to define the authorized label list, see Manage job labels. If you are not an Admin of your platform, and want to use Labels, ask your administrator to add a label list.
It’s possible to add a label on a job in Workflow Execution The user can set a label on a job by clicking on Job Actions button of the job and then click on Edit label. The user can select any of the labels available in the sub-menu list. It’s possible as well to remove a label from a job by selecting Job Actions button of the job and then click on Remove label.
The user can set a label as well on a job from Scheduler Portal. It’s possible to select one or more jobs and then, from the right-click drop-down menu, the user can select Edit label and chose from the available labels. The user has the option to remove a label from a job or a list of jobs by selecting Remove label from the same drop-down menu.
7. Data Spaces
If a shared folder or file system is not an option in your environment, the ProActive Scheduler provides a convenient way to transfer files between server and tasks.
This mechanism is called ProActive Data Spaces.
Data Spaces come into two categories:
-
Server Data Spaces: Global and User Spaces belong to this category. It represents data spaces located on the server side.
-
Node Data Spaces: Local and Cache Spaces belong to this category. It represents data spaces located on the Node or during a Task execution.
7.1. Global and User Spaces
Server Data Spaces have two types of storage on the host where the ProActive server is running:
-
A Global Space where anyone can read/write files
-
An User Space which is a personal user data storage
By default, these spaces are linked to folders in the data directory of the ProActive Scheduler host:
-
PROACTIVE_HOME/data/defaultglobal -
PROACTIVE_HOME/data/defaultuser
But it can be changed in PROACTIVE_HOME/config/scheduler/settings.ini.
See Data Spaces configuration for further details on how to configure the Global and User spaces.
7.2. Local Space
The Local Space is a Node Data Space created dynamically when a Task is executed.
The Local Space allows to:
-
Transfer files from one of the Server Spaces (Global or User) to the task execution context, before the task starts its execution.
-
Transfer files from the task execution context to one of the Server Spaces (Global or User) at the end of the task execution.
These two types of transfers must be declared in the Task definition in order to occur (transfer is not implicit). You need to define which files have to be transferred from a data space to computing nodes by using input files and reciprocally from computing nodes to a data space by using output files:
<task name="task1">
...
<inputFiles>
<files includes="tata" accessMode="transferFromGlobalSpace"/>
</inputFiles>
<outputFiles>
<files includes="titi*" accessMode="transferToGlobalSpace"/>
</outputFiles>
...
</task>Upon the execution of the previous example, ProActive Scheduler automatically transfers all files to a ProActive Node where the task will be executed. The files are put in a special place called Local Space on the ProActive Node. It corresponds to the working directory of a task when the task is in fork mode (default). From a task point of view, files can be accessed normally like shown below:
File inputFile = new File("tata")Then, based on the previous task definition, all the files whose the name starts with titi (e.g titi, titi2, etc.) produced by task1 will be transferred back automatically to Global Space by the Scheduler once the task is finished.
Files can be also transferred from/to User Space by specifying transferFromUserSpace/transferToUserSpace.
Before running your jobs you should first upload your files into either Global or User Space. To do it you can export folders linked to these spaces by one of the standard protocols like FTP, NFS, or use available web interfaces like Pydio.
It is possible to use wildcards in transfer directives, such as:
<task name="task1">
...
<inputFiles>
<files includes="**/tata" accessMode="transferFromGlobalSpace"/>
</inputFiles>
<outputFiles>
<files includes="*" accessMode="transferToGlobalSpace"/>
</outputFiles>
...
</task>More information of pattern syntax can be found in the FileSystem class JDK documentation.
7.3. Cache Space
In addition to transferring to the Task Local Space, it is also possible to transfer files to the Node host Cache Space.
From the Node host point of view, the Cache Space is unique and shared for all tasks and all ProActive Nodes deployed on the host.
Transfers to the cache are not concurrent, only a single task can transfer to the cache at the same time. I.e if multiple tasks are run in parallel on the same hosts and they all transfer to the cache, these transfers will be executed sequentially.
If a file declared for the transfer is newer than the existing version in the cache, the file will be updated.
In order to transfer files to the cache, simply use the cache transfer directives inside your job:
<task name="task1">
...
<inputFiles>
<files includes="tata" accessMode="cacheFromGlobalSpace"/>
<files includes="toto" accessMode="cacheFromUserSpace"/>
</inputFiles>
...
</task>The files will not be transferred to the Local Space of the task, so it will not be possible to access these files from the current directory.
In order to access these files, use the cachespace variable which contains the location of the cache, for example in groovy:
inputFile = new File(cachespace, "tata")There are no transfer directives to transfer output files from the cache. Output files transfers are only possible from the Local Space.
Files in the cache space are automatically deleted after a given period. The default invalidation period is two weeks, which means that files older than two weeks will be automatically deleted.
In order to change this period, the ProActive Node must be started with the property node.dataspace.cache.invalidation.period (in milliseconds).
The property node.dataspace.cachedir can also be used to control the cache location on the node.
8. Script Languages
8.1. Script Engines Names
This section gathers the available scripts engines and the operating system where they run.
| Script engine naming is case-sensitive |
| Script Engine Name | Description | Operating System | Additional Requirements |
|---|---|---|---|
|
An engine able to run several linux shell scripts using the shebang notation. |
Linux, Mac |
|
|
An engine able to run linux bash shell scripts. |
Linux, Mac |
|
|
An engine able to run Windows CMD scripts. |
Windows |
|
|
An engine able to run PowerShell scripts. |
Windows |
Powershell 2.0 Engine and .NET Framework 3.5 must be installed |
|
An engine able to run VBScript commands and scripts. |
Windows |
|
|
An engine able to run Docker containers defined as Dockerfile. |
Linux, Mac, Windows |
Docker must be installed |
|
An engine able to run composite Docker containers defined as Docker-compose description file. |
Linux, Mac, Windows |
Docker and Docker-Compose must be installed |
|
An engine able to run Kubernetes pods using a kubernetes yaml job description file. |
Linux, Mac, Windows |
Kubernetes client kubectl must be installed |
|
An engine able to run Javascript code using the Nashorn JSR223 implementation. |
Linux, Mac, Windows |
|
|
An engine able to run Groovy scripts. |
Linux, Mac, Windows |
|
|
An engine able to run JRuby scripts. |
Linux, Mac, Windows |
|
|
An engine able to run Jython scripts |
Linux, Mac, Windows |
|
|
An engine able to run native CPython scripts |
Linux, Mac, Windows |
CPython and py4j module must be installed |
|
An engine able to run R language scripts |
Linux, Mac, Windows |
R must be installed and the rJava library |
|
An engine able to run Perl scripts |
Linux, Mac, Windows |
Perl must be installed |
|
An engine able to create html content using PHP interpreter |
Linux, Mac, Windows |
PHP must be installed |
|
An engine able to run Scala scripts |
Linux, Mac, Windows |
8.2. Bash and Shell
The Bash and Shell script engines allows to run linux shell scripts inside ProActive Tasks. The main difference between the two script engines is that the Shell script engine must use the Shebang instruction to define the Shell in use inside the script.
Both engines features the following behaviors:
-
Script bindings are translated as environment variables.
-
Workflow variables cannot be modified by shell scripts except when adding a post script written in another language such as the
update_variables_from_filescript. -
The result of the script engine execution corresponds to the return code of the bash or shell process executed.
Example bash script (the shebang notation is omitted):
echo "Hello world"Example shell script:
#!/bin/ksh
print "Hello world"Writing Bash or Shell scripts in ProActive Workflows is rather straightforward, but a few considerations need to be taken into account.
The automatic binding mechanism works differently as other scripting language: it makes use of environment variables.
For example, suppose that the workflow variable foo is defined. This workflow variable can be accessed in the script engine through a specific environment variable created by the ProActive Scheduler:
echo "Here is the value of the foo variable:"
echo "$variables_foo"The Script Bindings Reference chapter shows how various bindings can be used in bash or shell script engines.
In chapter Script variables, we explain how a given task script can modify the variable map and propagate its modifications inside the workflow. This does not apply to shell script engines, i.e. a shell script engine cannot modify the variables map directly.
For example, suppose the initial value of the foo variable is "Old Value" and Task_A contains the script:
echo "Here is the value of the foo variable:"
echo "$variables_foo"
echo "I want to modify the value of the foo variable:"
variables_foo="New Value"And Task_B a child of Task_A contains:
echo "Here is the value of the foo variable:"
echo "$variables_foo"Then, Task_B will display
Here is the value of the foo variable: Old Value
We can see that the execution of Task_A had no impact on the foo variable.
In general, when a modification of a workflow variable is needed, other script engines should be used.
In ProActive Catalog, an example groovy post script called update_variables_from_file allows to propagate a variable modification from a shell main Task script using a temporary file:
Task_A main bash script:
echo "Here is the value of the foo variable:"
echo "$variables_foo"
echo "I want to modify the value of the foo variable:"
variables_foo="New Value"
echo "foo=$variables_foo">>$localspace/.variablesTask_A grovy post script (update_variables_from_file)
new File(localspace, ".variables").eachLine { line ->
keyvalue = line.split("\\s*=\\s*")
if (keyvalue.length == 2) {
variables.put(keyvalue[0], keyvalue[1])
}
}Task_B a child of Task_A:
echo "Here is the value of the foo variable:"
echo "$variables_foo"Displays:
Here is the value of the foo variable: New Value
8.3. Windows Cmd
Windows Cmd script engine behaves similarly as bash script engine, but for Microsoft Windows Operating systems.
It features the following behaviors:
-
Script bindings are translated as environment variables.
-
Workflow variables cannot be modified by Windows Cmd scripts except when adding a post script written in another language such as the
update_variables_from_filescript (see Bash script language for further explanations). -
The result of the script engine execution corresponds to the return code of the
cmd.exeprocess executed.
Example variable usage:
echo "Here is the value of the foo variable:"
echo "%variables_foo%"8.4. VBScript
VBScript engine behaves similarly as Windows CMD but using visual basic syntax instead of batch. It uses the cscript.exe command to execute vbs scripts.
It features the following behaviors:
-
Script bindings are translated as environment variables. They must be accessed inside the script as a process variable.
-
Workflow variables cannot be modified by VB scripts except adding a post script written in another language such as the
update_variables_from_filescript (see Bash script language for further explanations). -
The result of the script engine execution corresponds to the return code of the
cscript.exeprocess executed.
Example variable usage:
Set wshShell = CreateObject( "WScript.Shell" )
Set wshProcessEnv = wshShell.Environment( "PROCESS" )
Wscript.Echo "Hello World from Job " & wshProcessEnv( "variables_PA_JOB_ID" )Any error occurring during the script execution does not imply necessarily that the workflow task running the script will fail. This is due to the cscript command not immediately exiting upon error.
In order to report a failure to the task when running a VB script, the following instruction can be added in the beginning of the script:
On Error Quit 1Example:
On Error Quit 1
Wscript.Echo "This will produce an error" & (1 / 0)8.5. Javascript
Javascript engine allows running Javascript scripts inside ProActive Tasks. This engine is based on Nashorn Javascript engine. Nashorn Javascript engine provides Rhino compatibility mode which is described in the following documentation.
Example of Javascript ProActive Task which modifies Job Variable:
var status = variables.get("orderStatus")
if (status == "delivered") {
status = "returned"
}
variables["orderStatus"] = status
variables.put("otherVar", "someConstValue")Example of Javascript ProActive Task which modifies Job Variable containing JSON object:
var jsonVariable = JSON.parse(variables.get("jsonVariable")) // you need to parse your variable first
jsonVariable["newVar"] = "newValue" // then you can modify it as regular json
var serializedJsonVariable = JSON.stringify(jsonVariable) // then you need to serialize it to string
variables["jsonVariable"] = serializedJsonVariable // and finally you can overwrite existing variable
You have to use variables["myVarName"] = somevar syntax,
instead of variables.put("myVarName", somevar) syntax, for storing the variables if you are using Javascript variables.
You still can use variables.put("myVarName", "someConstantValue") syntax for storing constants.
|
Example of Javascript ProActive Task which returns JSON object as a result:
var jsonObject = {"orderStatus": "done", "customerName": "privatePrivacy"};
var serializedJsonObject = JSON.stringify(jsonObject) // then you need to serialize it to string
result = serializedJsonVariable
To save a JSON object as a variable or as a task result
you have to serialize to a string first, by using JSON.stringify()
|
8.6. Python
We support both Jython and Python Script Engines. Jython is an implementation of the Python programming language designed to run on the Java platform, Jython programs use Java classes instead of Python modules. The advantage of using our Jython Script Engine is that you do not need to do any installation. It includes some modules in the standard Python programming language distribution, but lacking the modules implemented originally in C. Besides, the libraries such as numpy, matplotlib, pandas, etc. are not supported by Jython. And the libraries which depends on numpy such as TensorFlow, PyTorch and Keras etc. are not supported neither.
In order to support native Python, we provide also a Python Script Engine. To use the Python Script Engine, the 'Language' field should be put to 'cpython'. By using Python Script Engine, you can personalize the Python version that you want to use. Since there are many different versions of Python (mainly Python2 and Python3) which are not compatible, ProActive supports all the Python versions (Python2, Python3, etc). By default, the Python used to execute the script is the default Python version on your machine. In order to use another Python version to execute the task, it is required to add a 'PYTHON_COMMAND' Generic Information. Its value should contain the symbolic or absolute path to the desired python command to run (for example 'python3' or '/usr/local/opt/python3/bin/python3.6'). If the Generic Information is put at task level this version of Python will be only used for this task, if it is put in the job level this version of Python will be used for all the tasks in this job.
For every tasks which use the native python script engine:
-
Python must be installed on the ProActive Node which will be used to execute the task.
-
The py4j module must be installed. Please refer to Python Script Engine (Python task) for the introduction about the installation of Python Script Engine.
Here is a workflow example (in xml format) about a simple Python task:
<taskFlow>
<task name="Python_Task" >
<description>
<![CDATA[ The simplest task, ran by a python engine. ]]>
</description>
<genericInformation>
<info name="PYTHON_COMMAND" value="python3"/>
</genericInformation>
<scriptExecutable>
<script>
<code language="cpython">
<![CDATA[
import platform
print("The current version of python you are using is: " + platform.python_version())
print("Hello World")
]]>
</code>
</script>
</scriptExecutable>
</task>
</taskFlow>A jython script engine execution runs in the same Java process as the Task execution. A cpython script engine execution runs inside a separate python process.
8.7. R
ProActive R script engine is based on the Java R Interface. In order to use the R script engine inside a ProActive Node (container which executes a workflow Task), the following prerequisites are needed:
-
A R distribution must be installed.
-
The rJava package must be installed.
-
The
R_HOMEenvironment variable needs to be configured, to allow the script engine finding the R distribution. -
The
R_LIBSenvironment variable might need to be configured if R libraries cannot be found automatically in $R_HOME/library.
The ProActive R script engine works on both Linux and Windows.
Here is an example of R script:
jobName <- variables[['PA_JOB_NAME']]
cat('My job is called', jobName, '\n')The following paragraphs describes the R script language specific syntaxes.
The progress variable is set as follows (notice the leading dot):
.set_progress(50)In contrary to other languages such as groovy or jruby, the parent tasks results (results variable) is accessed directly:
print(results[[0]])Variable affectation can be done via:
variables[["myvar"]] <- "some value"Access to dataspaces variables is similar to other languages:
print(userspace)
print(globalspace)
print(inputspace)
print(localspace)
print(cachespace)
print(outputspace)Some internal R types (such as lists, vectors, strings) are automatically converted when stored as a result or in the workflow variable map, but other types such as data.table are not automatically converted. Conversion for these types should be done manually, for example using json serialization or an output file.
Java objects such as fork environment variable, scheduler, userspace or globalspace APIs are not available in R.
8.8. PowerShell
ProActive PowerShell script engine is based on jni4net to call the Powershell API from Java.
It requires that Powershell 2.0 Engine and .NET Framework 3.5 are installed on the relevant machines.
An example of Powershell script:
$variables.Set_Item('myvar', 'value')
$result = Get-DateIn contrary to other languages such as groovy or jruby, the parent tasks results (results variable) is accessed directly:
Write-Output $results[0]Variable affectation can be done via:
$variables.Set_Item('myvar', 'value')Internal PowerShell types such as Dates are automatically serialized to an internal format which can be understood by another powershell task, for example in the following two tasks:
Task1:
$result = Get-DateTask2:
Write-Output $results[0].DayThe second task is able to automatically use the Date object received from the first task.
When an internal PowerShell type needs to be used by another language than PowerShell, a manual conversion such as json must be performed.
8.9. Perl
The Perl script engine features the following behaviors:
-
Script bindings are translated as environment variables.
-
Workflow variables cannot be modified by Perl scripts except when adding a post script written in another language such as the
update_variables_from_filescript (see Bash script language for further explanations). -
The result of the script engine execution corresponds to the return code of the
perlprocess executed.
In that sense, the Perl script engine behaves similarly as the Bash or Cmd script engines.
Please refer to Script Bindings Reference for the complete list of bindings accessible through environment variables.
Inside Perl, you can access environment variables using the %ENV hash.
Next examples clarify how script engine bindings can be accessed inside Perl scripts.
A workflow variable can be accessed using system environment variables:
my $jobName= $ENV{"variables_PA_JOB_NAME"};Similarly, the result of a parent task:
my $parent_task_result= $ENV{"results_0"};Or another script binding (for example, USERSPACE):
my $USERSPACE= $ENV{"USERSPACE"};8.10. PHP
The PHP script engine features the following behaviors:
-
Script bindings are translated as environment variables.
-
Workflow variables cannot be modified by PHP scripts except when adding a post script written in another language such as the
update_variables_from_filescript (see Bash script language for further explanations). -
PHP script engine is meant to return HTML content and makes use of result metadata through the content.type="text/html" generic information. Using the script engine without defining this generic information in the task is not recommended.
-
The result of the script engine execution is a byte array containing the HTML content produced by the
phpcommand. In case thephpcommand returns a non zero value, the result of the script engine execution will be the command exit code and the associated workflow task will be in error.
The php command returns a non-zero exit code only in case of syntax errors. When runtime issues occur, PHP will generally output warnings and the php command will return a zero exit code, not triggering a workflow task failure. This can be modified by using PHP exception mechanism and calling exit(error_code) in case of serious failures.
|
Inside PHP, you can access environment variables using the getenv() function.
Next examples clarify how script engine bindings can be accessed inside PHP scripts. Please refer to Script Bindings Reference for the complete list of bindings accessible through environment variables.
A workflow variable can be accessed using system environment variables:
<?php
echo "<p>Hello World from <b>job ".getenv("variables_PA_JOB_ID")."</b></p>";
?>Similarly, the result of a parent task:
<?php
echo "<p>Result of parent task is <b>".getenv("results_0")."</b></p>";
?>Or another script binding (for example, USERSPACE):
<?php
echo "<p>Userspace is located at <b>".getenv("USERSPACE")."</b></p>";
?>8.11. Docker Compose
The execution of a Docker_Compose task requires the installation of both Docker and Docker Compose on the host machine of the ProActive Node. Please refer to the official Docker documentation to see how to install Docker and Docker Compose.
A Docker_Compose task expects the content of a Docker Compose file to be implemented inside the Script editor of the Task Implementation section. You can find out how to write Docker Compose files in the official Docker Compose documentation.
To get started, we present below the content of the Script editor of a simple example of a Docker_Compose task.
helloworld:
image: busybox
command: echo "Hello ProActive"The above example describes a container which is called 'helloworld'. That container is created from a busybox image, which will run the command 'echo "Hello ProActive"'
The Docker_Compose task allows to set parameters to the docker-compose tool with regard to the docker-compose CLI reference.
docker-compose [general parameters] COMMAND [options]
It supports general parameters as well as commands options (we currently only support options for the up command).
You can specify these options by supplying a space character separated list in the generic informations.
-
To define a general parameter, use the key docker-compose-options and supply "--verbose" as an example value.
-
To define a docker-compose up option, use the key docker-compose-up-options and supply "--exit-code-from helloworld".
The two latter generic information will be used to generate the following command:
docker-compose --verbose up --exit-code-from helloworld
If splitting by space is prohibitive you can specify the split regex in the generic informations with the key docker-compose-options-split-regex. If you supply e.g. "!SPLIT!" as value, then your docker-compose-up-options will need to look like this: "--option1!SPLIT!--option2".
8.12. Dockerfile
8.12.1. Introduction
The Dockerfile engine allows to define a docker image using the Dockerfile syntax, build this image and run a container instance from it. Once the execution is done, the container is stopped and the built image is deleted. The build, start, stop and, remove actions can be parametrized through advanced command line options which are detailed in the Docker actions section.
The execution of a Dockerfile task requires the installation of Docker engine on the host machine of the ProActive Node. Please refer to the official Docker documentation to see how to install Docker.
To use a Dockerfile task, you have to put the content of a Dockerfile inside the Script editor of the Task Implementation section. You can find out how to write Dockerfile in the official Dockerfile documentation. A Dockerfile task allows executing a succession of docker commands according to the lifecycle of Docker containers. In order, docker build, docker run, docker stop, docker rm and docker rmi are run when a Dockerfile task is executed, this sequence of actions can be configured (see below).
To get started, we present below the content of the Script editor of a simple example of a Dockerfile task.
FROM ubuntu:18.04
RUN echo "Hello ProActive"
RUN sleep 30The execution of this example will create an image using the Docker build command and start a container from this image using the specified commands (echo and sleep). At the end, the built image and the started container are deleted.
The created image default tag is image_${PA_JOB_ID}t${PA_TASK_ID} and the default container tag is container_${PA_JOB_ID}t${PA_TASK_ID}.
8.12.2. Docker actions
The default sequence of docker commands (build, run, stop, rm, rmi) can be modified to use the docker script engine in different configurations such as multiple workflow tasks.
For example, an image could be built in a first task, and the same image can be reused in other tasks (and removed eventually in a terminating task):
Another example would be to build an image and start a container in a first task, and then reuse this container in a different task:
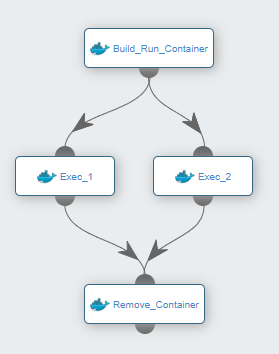
These different modes are configured using the docker-actions Generic Information.
For example, docker-actions=build,run allows to build an image, run a container, without performing stop, rm and rmi operations.
docker-actions supports the following commands build, run, exec, stop (includes both stop and rm), rmi.
As the default image and container tag names contains the job id and task id, it is important to use the following generic information when sharing images or containers accross multiple tasks or multiples workflows:
-
docker-image-tag: override default tag identifying the docker image. -
docker-container-tag: override default tag identifying the docker container.
| When starting the docker container in one task and reusing this container in another task, it is necessary to start the container in detached mode (see below for explanation on how to define additionnal options to docker commands). |
When a build action is not present in docker-actions, the content of the Dockerfile in the task script editor will be ignored. In that case, the docker-image-tag generic information will be used to identify the image, which must be present in the local docker cache.
|
8.12.3. Additional options
Parsing options
The following command line options need to be parsed by the Java Virtual Machine before generating the real command which will be executed. The default options parsing uses <space> as separator, but when an individual option contains spaces (such as a character string containg spaces), this could lead to parsing issues. In order to solve these parsing issues, the generic information docker-file-options-split-regex can be used to define a pattern which will be used as options separator. This pattern must comply to the Java Regular Expression syntax and will be given as parameter to the split function when parsing options.
For instance, if the docker-file-options-split-regex generic information is equal to !SPLIT!, then the option /bin/sh!SPLIT!-c!SPLIT!echo 'hello', will be parsed as [/bin/sh, -c, echo 'hello']
Docker build
The Dockerfile task allows to set parameters to the docker build command with regard to the docker-build CLI reference.
docker build [OPTIONS] PATH | URL | -
To define a docker-build option, use the generic information docker-build-options.
For instance, by using the docker-build-options generic information with the value --add-host, a custom host-to-IP mapping will be added to the image.
Docker run
The Dockerfile task allows to set parameters to the docker run command with regard to the docker-run CLI reference.
docker run [OPTIONS] IMAGE[:TAG|@DIGEST] [COMMAND] [ARG...]
To define a docker-run option, use the generic information docker-run-options.
For instance, by using the docker-run-options generic information with the value --detach, the container will be started in detached mode.
| use the detached mode uption to run a container and share this running container between multiple workflow tasks. |
Docker exec
The docker exec command can be executed optionnally if included in Docker actions.
The Dockerfile task allows to set parameters to the docker exec command with regard to the docker-exec CLI reference.
docker exec [OPTIONS] CONTAINER COMMAND [ARG...]
To define the command and arguments which need to be executed inside a running container, use the generic information docker-exec-command.
For instance by using the docker-exec-command generic information with the value my-program arg1 arg2, the resulting command will be docker exec <container-tag> my-program arg1 arg2.
when command arguments contain spaces, use the generic information docker-file-options-split-regex to define an alternate option parsing pattern. For example: /bin/sh!SPLIT!-c!SPLIT!echo 'hello'
|
To define a docker-exec option, use the generic information docker-exec-options.
For instance, by using the docker-exec-options generic information with the value --workdir /my/workkdir, the command will be executed with the specified work directory.
Docker stop
The Dockerfile task allows to set parameters to the docker stop command with regard to the docker-stop CLI reference.
docker stop [OPTIONS] CONTAINER [CONTAINER...]
To define a docker-stop option, use the generic information docker-stop-options.
For instance by using the docker-stop-options generic information with the value --time 30, the container will be stopped after 30s.
Docker rm
The Dockerfile task allows to set parameters to the docker rm command with regard to the docker-rm CLI reference.
docker rm [OPTIONS] CONTAINER [CONTAINER...]
To define a docker-rm option, use the generic information docker-rm-options.
For instance by using the docker-rm-options generic information with the value --volumes, the anonymous volumes associated with the container will be automatically deleted after the container is removed.
Docker rmi
The Dockerfile task allows to set parameters to the docker rmi command with regard to the docker-rmi CLI reference.
docker rmi [OPTIONS] IMAGE [IMAGE...]
To define a docker-rmi option, use the generic information docker-rmi-options.
9. Proactive Catalog: Object Storage and Versioning
The ProActive Catalog provides the storage and versioning of Workflows and several other objects inside Buckets. It also features a searching functionality using a GraphQL query language to fetch Workflows based on particular parameters. The Catalog is a RESTful service. A Swagger interface is provided to understand and interact with the service.
This chapter will cover:
-
ProActive Catalog main concepts.
-
How to interact with the Catalog from the various ProActive Workflows and Scheduling Portals.
The Catalog administration guide describe how the catalog can be configured and how access control of buckets can be enforced.
9.1. Bucket concept
A Bucket is a collection of ProActive Objects and in particular ProActive Workflows that can be shared between users.
When the ProActive Scheduler is first started, it contains already a predefined set of buckets, such as:
-
controls (set of workflows containing basic constructs such as branch,loop or replicate)
-
basic_examples (set of Workflows samples publicly readable)
-
notification_tools (set of tasks which can be used to send email or web notifications and/or validations).
-
data_connectors (set of Workflows which can be used to transfer files and data from various sources as explained in the Data Connectors chapter)
Listing the Catalog for existing Buckets is done using the following HTTP request (protocol, port and hostname needs to be adapted accordingly):
GET http://localhost:8080/catalog/buckets
It is also possible to list all objects inside a particular Bucket using its bucketName:
GET http://localhost:8080/catalog/buckets/{bucketName}/resources
Then, we can fetch a particular object based on its name:
GET http://localhost:8080/catalog/buckets/{bucketName}/resources/{name}
| By default, the Catalog will always return the latest version of the objects. |
9.2. Bucket naming requirements
Every bucket is identified by a unique bucket name. The bucket naming should match the following rules:
-
The bucket name must be between 3 and 63 characters long and can contain only lower-case characters, numbers, and dashes.
-
A bucket name must start with a lowercase letter and cannot terminate with a dash.
9.3. Object naming requirements
Each Catalog object is identified by a unique name. The object naming should respect the following rules:
-
Empty values are not allowed.
-
Must not be any trailing whitespace at the beginning or/and at the end.
-
Accept all characters except forward slash and comma ('/', ',').
9.4. Object versioning
The Catalog provides versioning of objects. You can list all the revisions of a particular object using the HTTP request:
GET http://localhost:8080/catalog/buckets/{bucketName}/resources/{name}/revisions
The revision of objects is identified by its commit_time. Commit time specifies the time when the object’s version was added in the Catalog.
You can fetch an object detailed metadata information using its name and commit_time:
GET http://localhost:8080/catalog/buckets/{bucketName}/resources/{name}/revisions/{commit_time}
When an object revision is added to the catalog, depending on its type, it may be parsed by the catalog service to extract some meaningful information.
For example, from a ProActive Workflow, the workflow name, project_name, description, documentation, Generic Information and Workflow variables are extracted.
These information are used in the various portals which interacts with the catalog such as the Workflow Execution Portal.
9.5. Retrieving and searching Objects
9.5.1. Get an Object from the REST API
From REST API it’s possible to retrieve the raw content of a specific revision of an object. For this case it’s required to specify name and commit_time of the object’s revision:
GET http://localhost:8080/catalog/buckets/{bucketName}/resources/{name}/revisions/{commit_time}/raw
In order to get the raw content of a last revision of an object use next REST API endpoint:
GET http://localhost:8080/catalog//buckets/{bucketName}/resources/{name}/raw
In this case you need to provide only the name of an object.
| A complete documentation of the Catalog REST API is available on the following link. |
9.5.2. GraphQL usage
GraphQL is the standardized query language, which provides opportunity to search and retrieve the Workflow by specified criterion from the Catalog. NOTE: Please follow the graphiql endpoint in order to query for the specific Workflow.
9.6. Catalog Portal
The Catalog Portal provides the capability to store objects like Workflows, Calendars, Scripts, etc. Powerful versioning together with full access control (RBAC) is supported, and users can easily share Workflows, templates, and other objects between teams, and various environments (Dev, Test, Staging, Prod).
9.6.1. Creating new buckets
Create a new bucket easily by clicking on the plus button.
In the Create the new bucket window, it is possible to associate a bucket to a specific users group.
By doing so, only users from the same group will be able to access the content of the bucket.
The content of the buckets associated with the default - no group is accessible by any user, regardless of the groups they belong to.
A bucket with no associated group is also known as a public bucket.
More information regarding bucket access control is available in the Catalog administration guide.
9.6.2. Removing Objects Inside a Bucket
Select the objects to remove (CTRL + left click to select multiple objects) and click on the trash button.
| All the object’s content will be removed from the database and it cannot be restored. |
9.6.3. Exporting/Importing Objects into the Catalog
Catalog Objects can be exported to a local archive, and share them easily by email, cloud, etc. The same archive can be imported again in the Catalog on the same scheduler or in a different one.
| Use this feature to easily share Catalog objects across different environments. |
To export the selected objects as a ZIP archive, press the download button from portal view.
To import, either a downloaded catalog archive zip file or a single object, click on the upload button and follow the instructions:
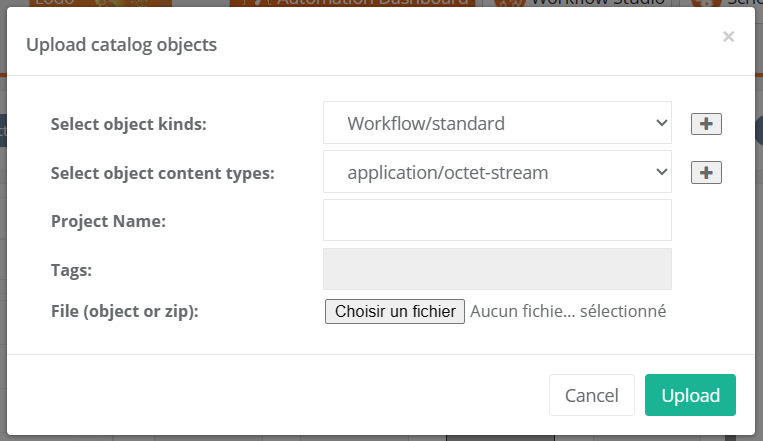
-
Object Kind: The kind of object to add. New Kinds can be added by clicking the
plusbutton. -
Content Type: The Content Type is used to indicate the media type of the resource. New content Types can be added by clicking the
plusbutton. -
Project Name: The name of the project to which belongs the object. The project name can be provided for all catalog objects (e.g. workflow, script, rule, etc).
-
Tags: The tags of the object as a comma-separated values list. The tags can not be provided for workflow and zip files.
| In case of uploading an archive, all the objects in the zip must have the same Kind and Content Type. |
9.6.4. Create a zip archive with Catalog objects
When a user creates an archive in order to upload a set of Catalog objects, hidden files should be excluded from this archive.
Create a zip archive with Catalog objects in Mac OS.
First, go to the folder with the objects that you want to archive.
Then, you can execute the following command to archive the files without the .DS_Store and __MACOSX files:
|
zip -r ArchiveForCatalog.zip . -x "*.DS_Store" -x "__MACOSX"
9.6.5. Object Versioning in Catalog Portal
The HEAD of a Catalog object corresponds to the last commit and it is displayed on the portal.
In order to see all the commits of the selected Object, please click on the clock button inside the description area.
The commits are shown in chronological order by commit time.
It is possible to restore any previous commit to the HEAD position by clicking the restore button.
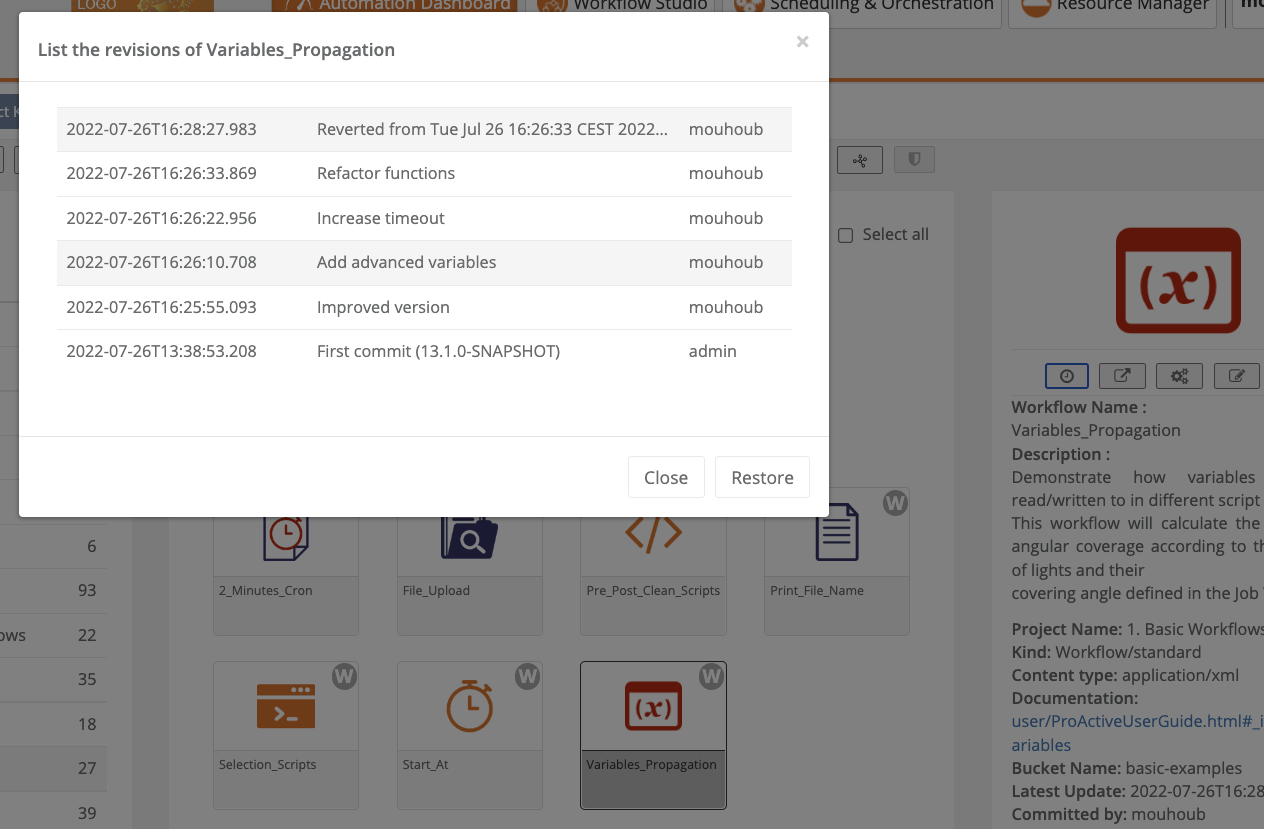
9.6.6. Catalog RBAC management
RBAC, or Role Based Access Control, represents a control model for a system in which each access decision is based on the role to which the user is associated. In the catalog, RBAC operations are only performed by admins or bucket owners. RBAC operations can be distinguished in two types:
-
Managing an authorization for a bucket
-
Managing an authorization for a specific object in a bucket
Both bucket and object authorizations can be assigned for either a specific user (using her/his username) or a user group (that contains multiple users). For each specific bucket or object, only one authorization can be assigned to a username or a user group. However, the user can eventually have multiple authorizations due to a mix of username and user-group related authorizations for a bucket or an object. Furthermore, the created authorizations can be modified or deleted.
An authorization gives the specified user(s) some access permission to the specific bucket or object. We provide four access types that can be authorized:
-
Read: The user or user group can only read the bucket and its objects (in case of a bucket authorization) or the object only (in case of a catalog-object authorization) and execute it.
-
Write: The user or user group have, in addition to the read right, the privilege to add new objects in the bucket and to modify or delete one or many.
-
Admin: The user or user group have, in addition to the write rights, the ability to modify a bucket (e.g. change the group) or delete a bucket. Moreover, they can create, modify or delete the authorizations of other users for the bucket or its objects. The same apply in case of a catalog-object admin authorization where the user or group of users, in addition to the write rights, can create, modify or delete a catalog-object authorizations for other users. However, they can not create, edit or delete bucket authorization neither edit nor delete them.
-
No Access: The user or group of users have no access to the bucket and its objects (in case of a bucket authorization) or to a specific object (in case of a catalog-object authorization). This access type is usually used when the admin wants to authorize a user group except for some specific users, or authorize access to a bucket except for some specific objects.
To manage the authorizations, there is a dedicated authorization view for each bucket that is accessible by clicking on the shield-like button above the buckets' list, as shown in the figure below.

The same is also available for an object. Moreover, when you select an object, the authorization view button will appear above the objects of the selected bucket (the middle view of the portal). The figure below shows the icon location.

Once you click on it (bucket or object authorization view button), the authorization view will open. The figure belows shows the authorization view when the admin has clicked on the authorization view of a bucket.
The authorization view consists in two parts:
-
First, there are three buttons that allow the admin to refresh the authorizations list, add a new authorization and delete an existing one
-
Second, under the buttons, there is the list that shows the authorizations that are assigned to the current bucket. In the case of a bucket authorization view, the list shows the authorizations created for the bucket and all of its objects. However, in the case when the admin click on the authorization view button above the selected object, the list will show only the authorizations created for the selected object. The figure below shows an example.
Each authorization has the following properties:
-
Bucket Name
-
Catalog Object (optional): If this attribute is empty, the authorization is automatically considered for the bucket. However, if the admin specifies an object name, the access is created for the specified object.
-
Grantee Type: Group or user
-
Grantee (required): the username or the user group name
-
Access Type: read, write, admin or no access
-
Priority: This attribute is only used for access associated with a group. Thus, if the user belongs to 2 groups, each of which has a different type of access, the system will choose the access with the highest priority for these users.
To create a new authorization, the admin just needs to click on the "+" button.
Then the view of creating authorization (as shown in the figure below) will be popped up.
The admin needs to fill in the authorization attributes (as presented above), then click the "Add authorization" button.
The figure below shows an example of an authorization which authorize the user named olivia the write access to the bucket admin-bucket.
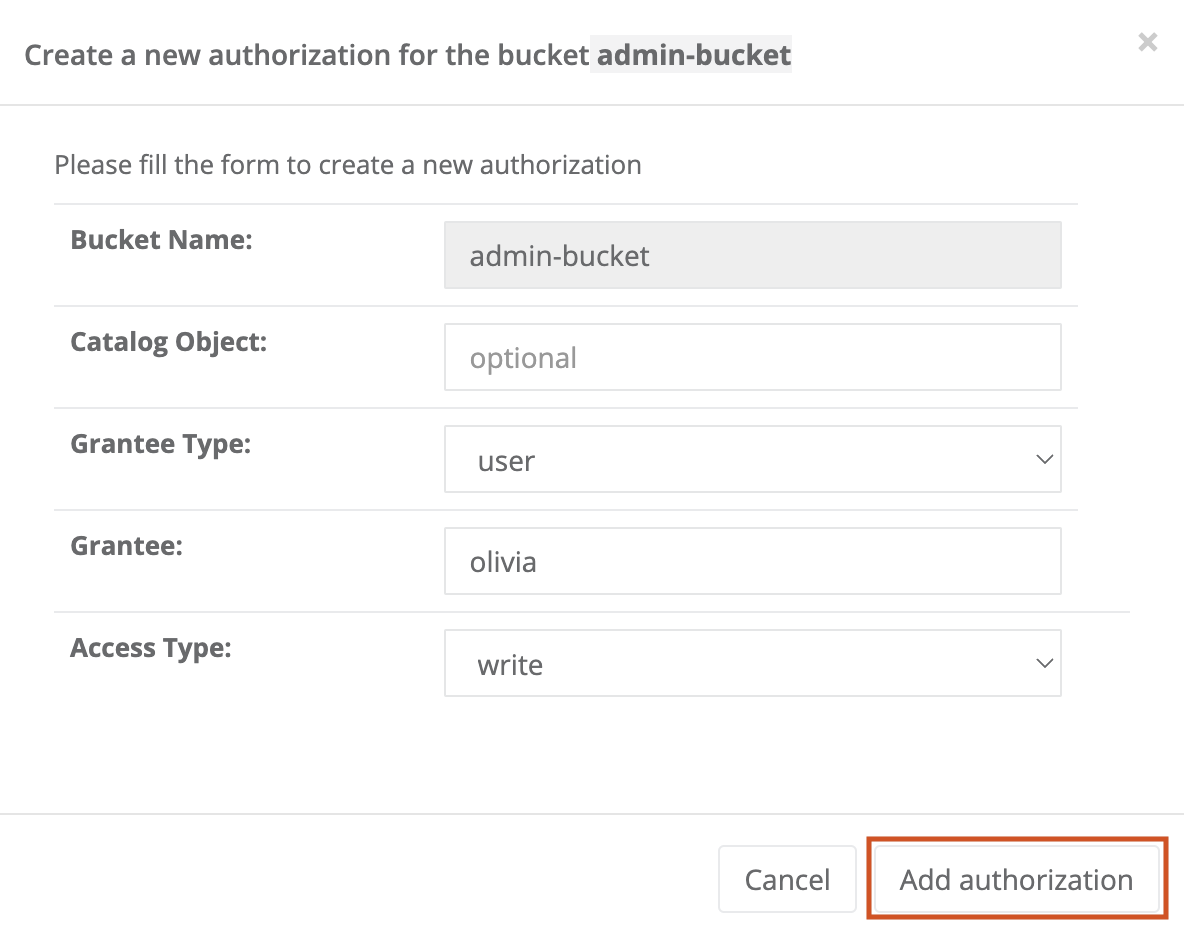
Once the admin has created an authorization, it will appear in the authorizations list in the authorization view, as shown in the figure below.
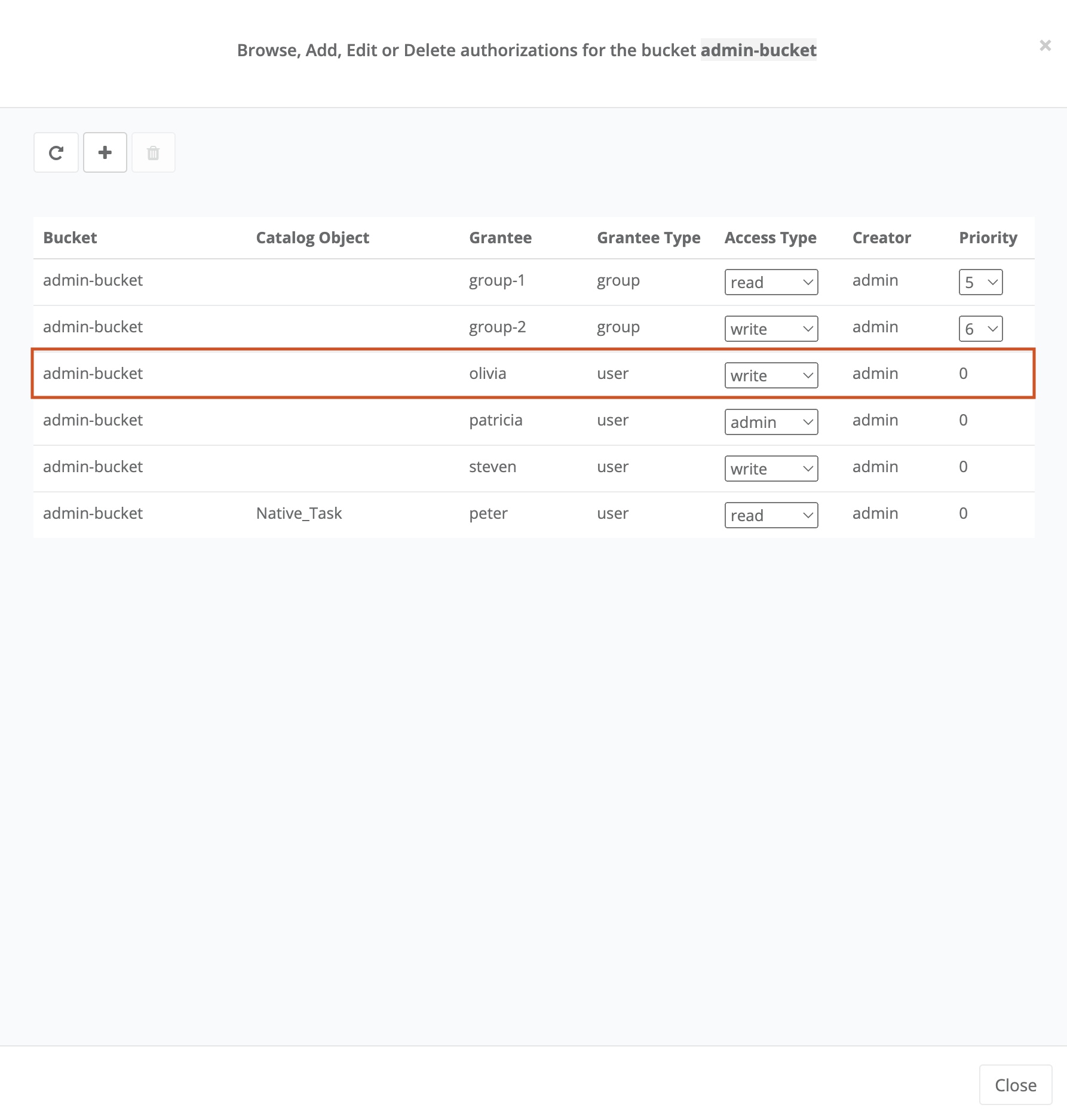
Once the authorization has been created, the admin will be able to visualize a "shield" icon next to bucket or the object to which the authorization was created. The figure below shows an example.
Moreover, when the user, who is benefiting from the authorization, log in to his/her account, she/he will be able to visualize an icon indicating the rights she/he possess over the bucket or the object. These icons are the following:
-
The first icon indicates that the user has "read" rights over the bucket or the object.
-
The second icon indicates that the user has "write" rights over the bucket or the object.
-
The third icon indicates that the user has "admin" rights over the bucket or the object.
-
The fourth icon appears only on a bucket to which the user has "no access" rights over it, but only when the user also has a read, write or admin rights over at least one object in the bucket.
The figure below shows how the user visualize the authorization icon next to the bucket.
The figure below shows how the user visualize the authorization icon next to the objects.
If the object does not have an icon next to it (e.g. Native_Task_Windows), it implies that it has not a direct authorization assign to it, and the user will have the same right over it as she/he has over the bucket containing it.
To delete an authorization, the admin simply needs to select one from the list and the delete button will be activated. It is the button with a "bin" symbol next to the add a new authorization button "+". The figure below shows an example.
Once the admin delete the authorization, it will be removed from the list as shown in the figure below.
To update an authorization, the admin needs to click on the drop-down list of the access type or the priority level and select a new value. The figure below shows an example.
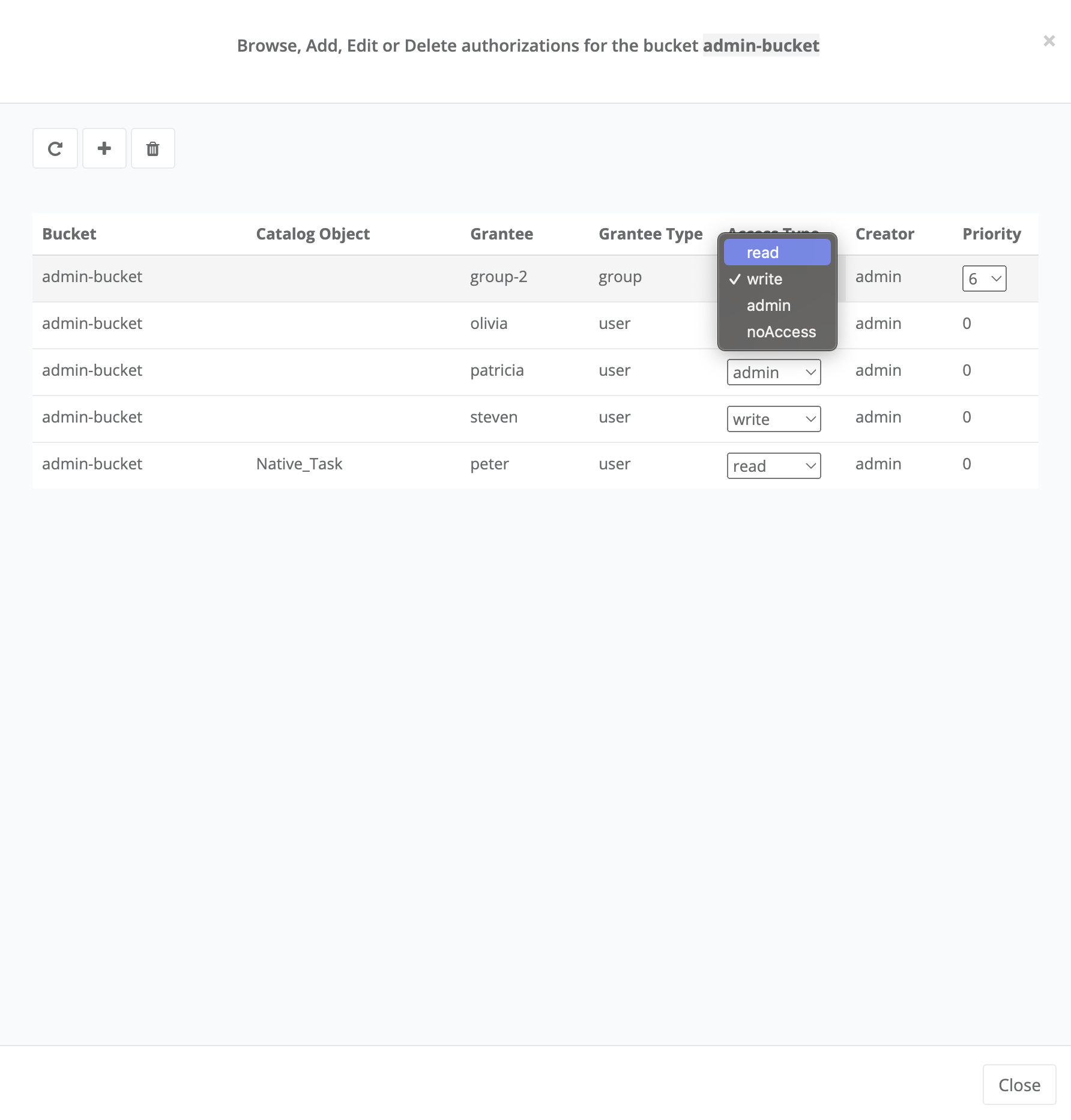
Once the selection is made the authorization will be updated as shown in the figure below.
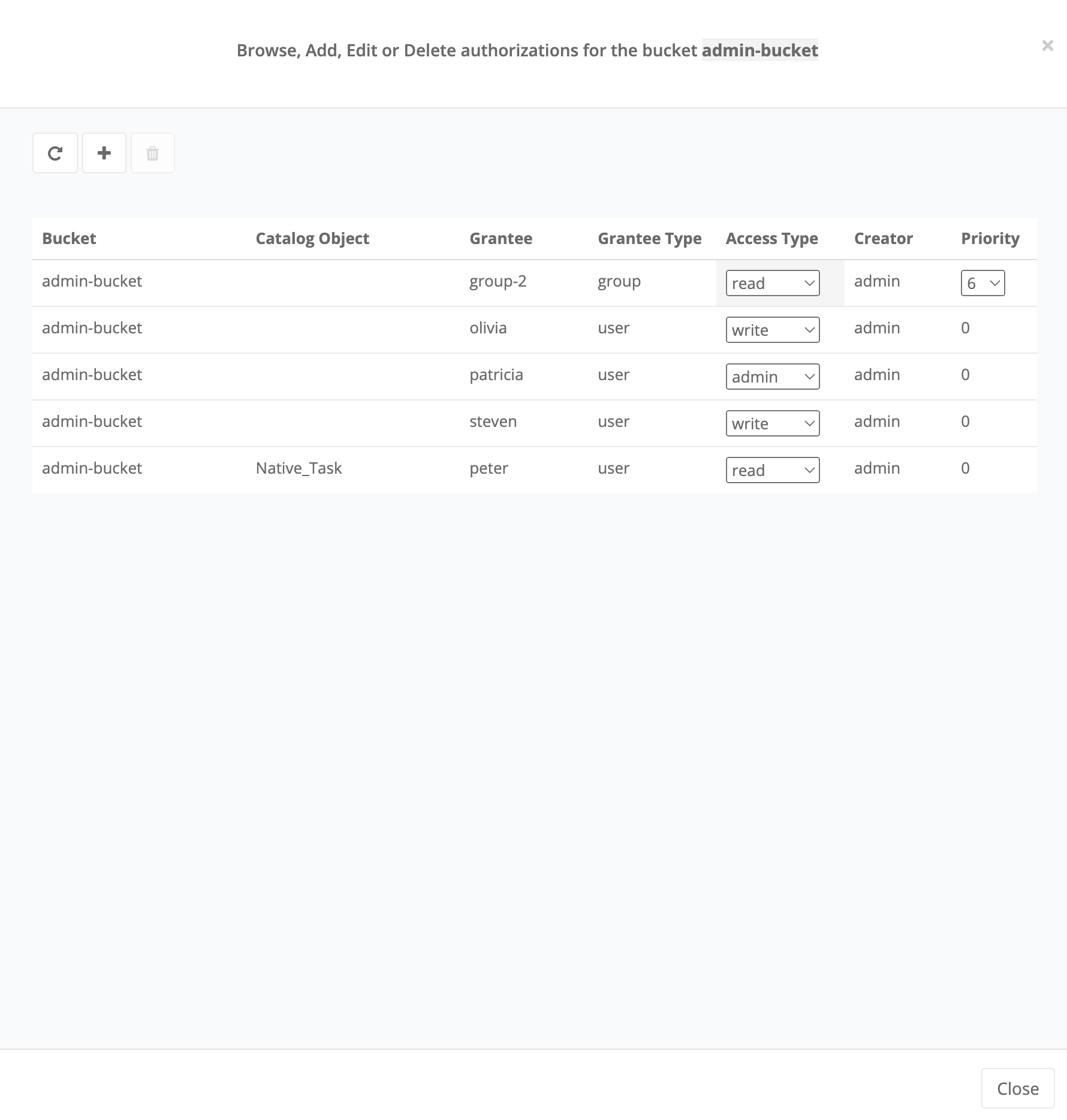
However, when a user has admin rights over a bucket or an object, he/she can not downgrade his/her rights while updating the authorization. Another user, with admin rights over the bucket or the object, can do it for him/her.
9.6.7. Authorization calculation rules
Since each user might belong to multiple user groups, a user could have multiple authorizations over a bucket due to his/her username or user group(s) authorizations. In such case, the resulting access type will be calculated as follows:
-
If the username-assigned authorization exists, it is prioritized and its access type will be the user’s resulting rights over the bucket.
-
If multiple user-groups authorizations exist, without a username authorization, the resulting user’s rights over the bucket will be the access type of the group authorization that have the highest priority.
In the case where a user has multiple authorizations over an object, the resulting access type will be calculated as follows:
-
If the username-assigned authorization for the object exists, it is prioritized and its access type will be the user’s resulting rights over the object.
-
If multiple user-groups authorizations exist for the object, without a username authorization, the resulting user’s rights over the object will be the access type of the group authorization that have the highest priority.
-
If both username-assigned authorizations and user-groups authorizations do not exist for the object, the resulting user’s rights for the object will be the same as the user’s resulting rights over the bucket that contains the object.
10. Notification-service
10.1. Overview
The Notification Portal allows users to subscribe, be notified and react when different types of events occur during Job execution, on the state of the ProActive Scheduler or when automating and scheduling jobs with the Job Planner.
The Notification Portal is also where users can perform actions on Validations when they are authorized to visualize them. Learn more at the Validation’s dedicated section.
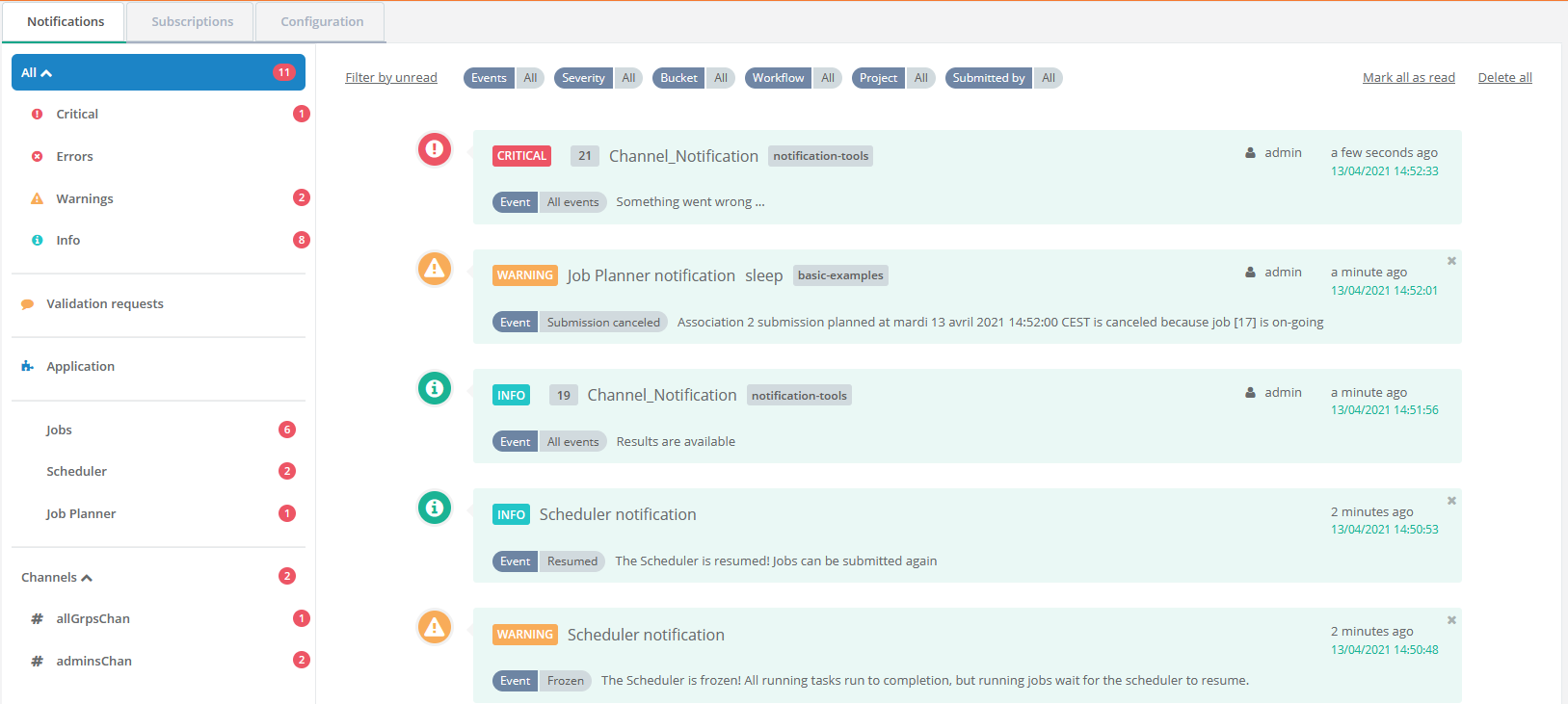
10.2. Subscriptions
10.2.1. Principle
A notification Subscription consists in a set of events selected by a user for a particular service, a type of workflows or a specific workflow.
Event reception is configurable and allows portal notifications, email sending and custom script execution.
A user creating a subscription will need to:
-
Select one of the subscription types
-
Select one or more events from a predefined list that user will be notified of.
-
Activate one or more Notification Methods.
10.2.2. Subscription types
There are three types of Subscriptions:
-
Service subscriptions.
-
Job subscriptions.
-
Channel subscriptions.
Service subscriptions
Service subscriptions are unique for each service they are associated to and created by default for every user. It enables to subscribe to events that may occur on a particular service like the ProActive Scheduler or the Job Planner.
Service subscriptions are deactivated by default, to start receiving notifications users only needs to:
-
Activate one or more Notification Methods.
-
Select desired events
-
Activate the Subscription.
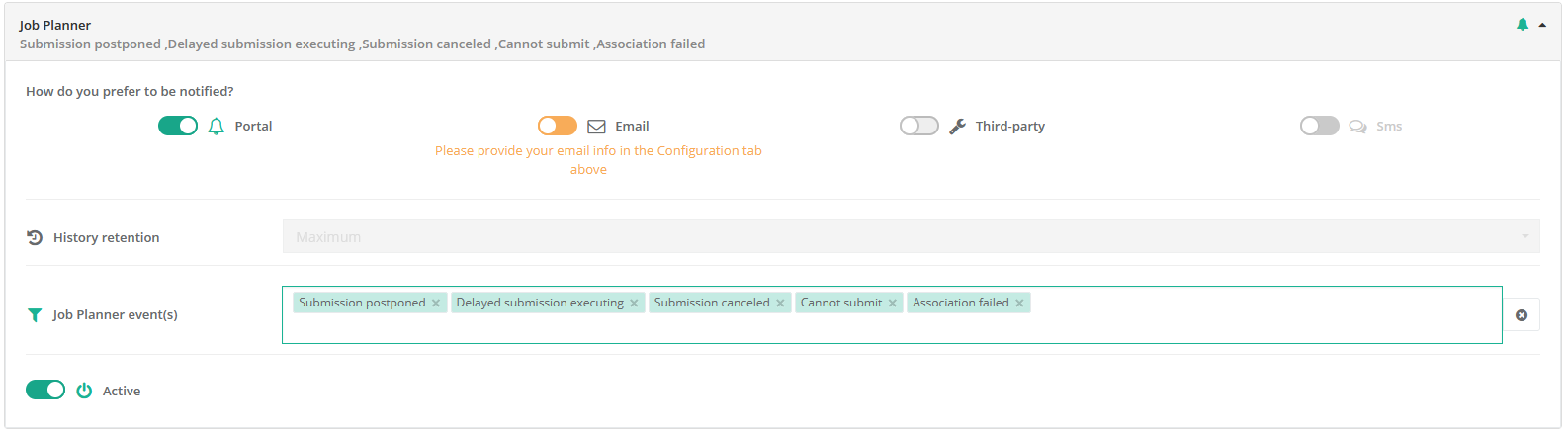
To modify a service subscription simply click on it and do your adjustments. The subscription is automatically saved.
Job subscriptions
Job subscriptions must be defined and created in order to receive notifications. Users can have multiple job subscriptions with different granularity on the workflows they are associated to.
At least one field of Workflow data must be provided to create the subscription, that means it is not possible to create a job subscription that will listen for all jobs submitted to the Scheduler.
| A workflow name which references a variable (e.g., my_workflow_${my_var} or my_workflow_$my_var) is replaced by substituting the variable with its value, in case this variable is defined at the workflow level. The replacement is performed when the job subscription is created. |

Two scenarios are possible when creating a job subscription:
-
If a bucket name only is set, then the user will be notified for all Workflows of the specified bucket.
-
Otherwise there has to be an exact match between the bucket name, project name and workflow name of the workflow you wish to be notified of and the associated subscription.
To create a job subscription, go to the Notification Portal, job subscriptions tab and click on the + button
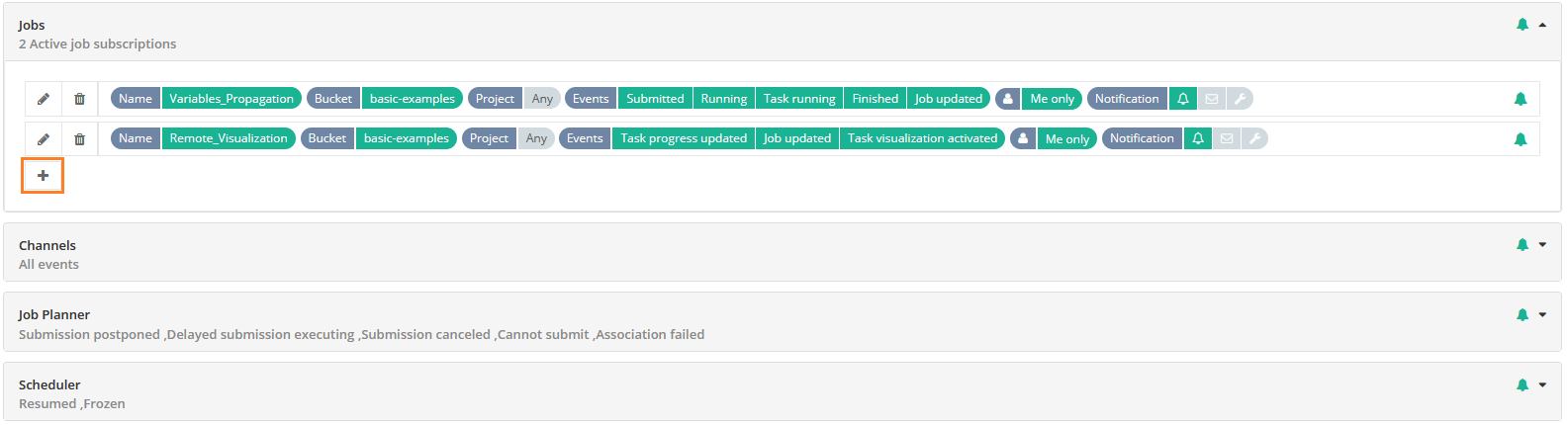
Then fill and select the mandatory fields and click on Save
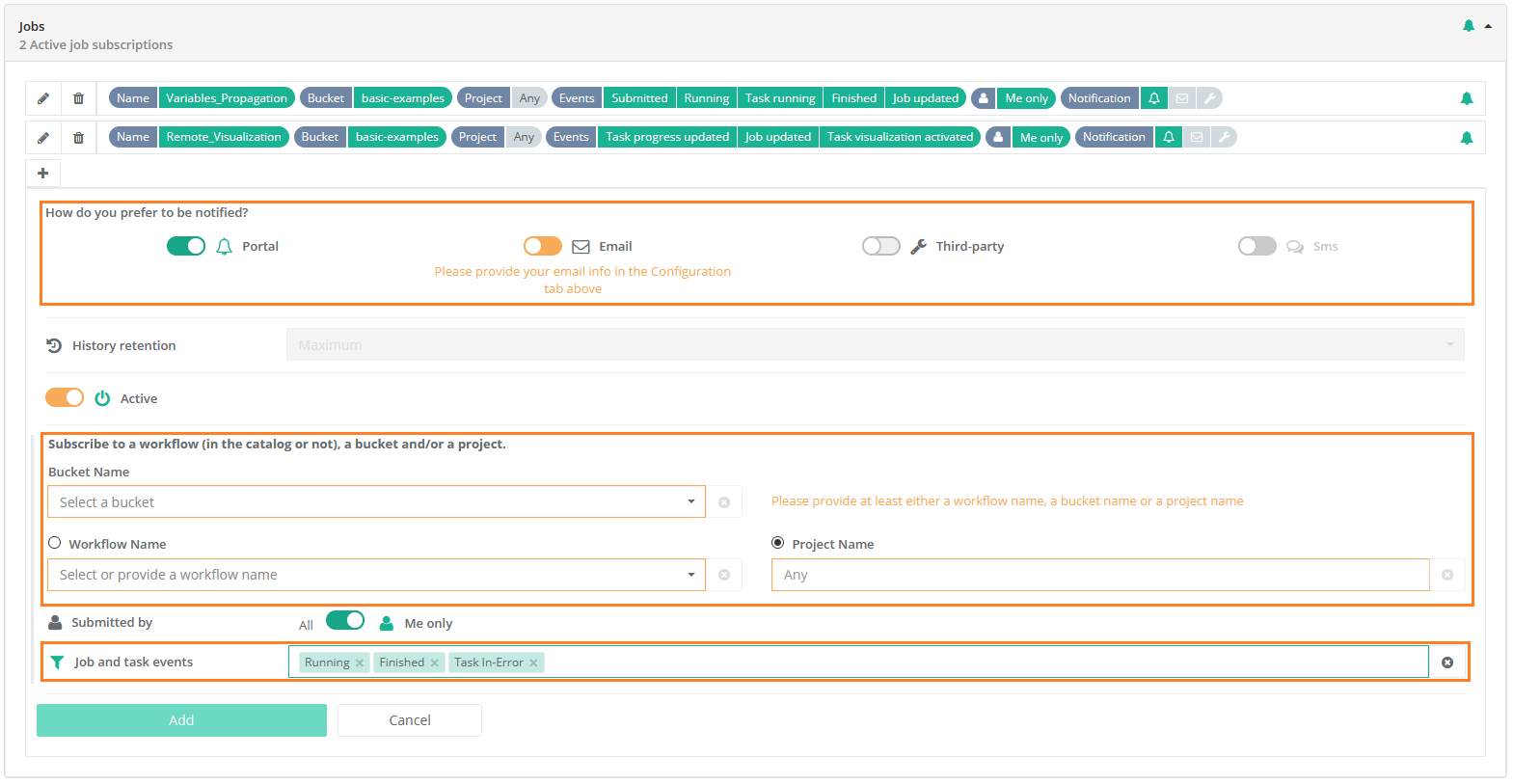
The Submitted by switch may be activated to be notified of events for job submitted only by the user who created the subscription.
To modify a job subscription simply click on it, do your adjustments and save it.
Channel subscriptions
Like service subscriptions, channel subscriptions are unique to each user. It allows users to subscribe to channels created beforehand. A user that is a notification service administrator can subscribe to any channel. Otherwise, a user can subscribe to:
-
A public channel (a channel authorized for all groups).
-
A channel whose group authorization matches one of the user groups.
To visualize past notifications and start receiving new ones, a user must update his channel subscription with the following actions:
-
Activate a notification method for the channel subscription.
-
Select desired channels from the user’s available channels list
-
Finally, activate the subscription.
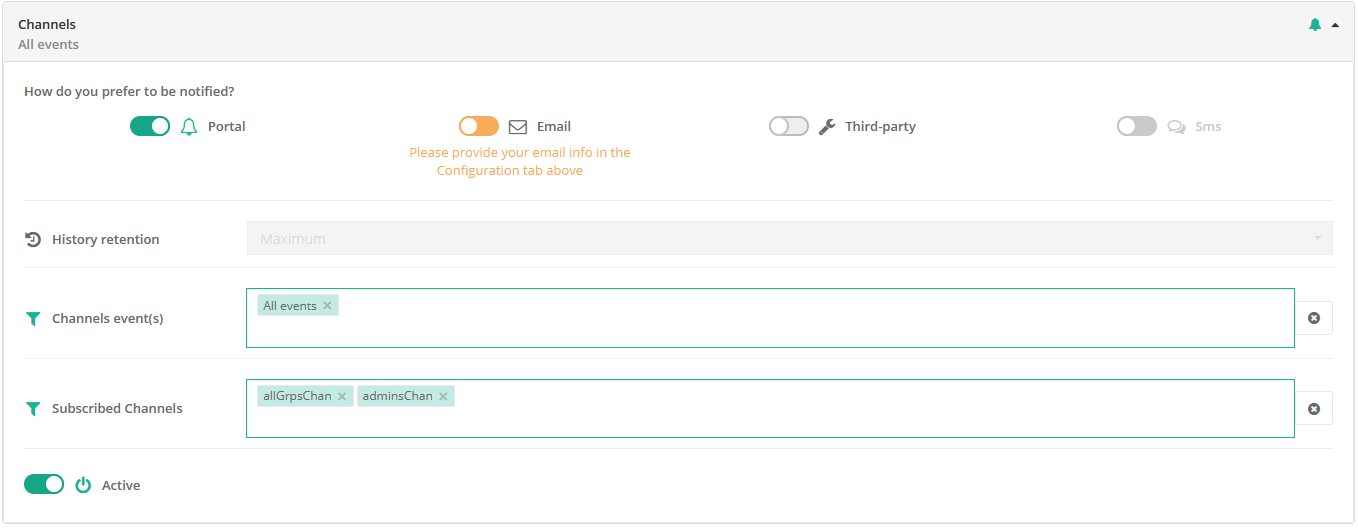
Go to the Channel section to learn more about channels.
10.2.3. Notification methods
To define the way to be notified, a user must select at least one notification method. It is mandatory to have at least one active notification method in order to create or update a subscription.
There are three notification methods available
-
"Portal": The notification will be displayed in the Notification Portal.
-
"Emails": The notification will be sent by email. Users can specify multiple email addresses as recipients for notifications. In order to use this method, the SMTP settings must be defined in the dedicated configuration file, inside the ProActive server. Please refer to the corresponding Email notification configuration section in the administration guide.
-
"Third-party": To trigger a script execution. It also requires configuration to specify the location of the script, or optional options such as multiple script execution. Go to the Third party notification method section in the Admin guide to look at the full configuration.
Notification Method confirmation
An administrator can activate confirmation request for notification methods other than portal. In such a scenario, once you’ve specified the notification method parameter, an input field will become visible below the third-party parameter or telephone parameter, prompting the user to enter a confirmation code. In the case of emails, the verification code input field is always shown.
It is also possible to resend from there a confirmation code in case it hasn’t been received , or if it has exceeded its 15 minutes life span and is now expired.
-
"Email": When a new email address is added, an email will be sent with the confirmation code in the body.
-
"Third-party": An execution will occur with the confirmation code in the accessible MESSAGE script field.
For notification methods which parameters are mandatory (ie: Email), the user may go to his subscriptions and activate the notification method to start receiving notification by this mean once the parameter is confirmed.
If a notification method parameter is deleted or changed and reused in the future, then a new confirmation request will be triggered.
10.2.4. Third-Party parameter
Users can provide subscription-specific third-party parameters, in contrast to the global third-party parameter in User Settings, which applies to all of a user’s subscriptions, the subscription-specific parameter is injected into each script execution triggered by the corresponding subscription. Executions for other subscriptions, whether for the same user or different users, will use the values defined in their own respective subscriptions.
10.3. Channels
10.3.1. Principle
A notification service Channel is a centralized space in the Notification Portal
for groups of users to receive notifications created from a workflow using the Channel_Notification task.
It consists of a unique name and a set of user groups authorized to subscribe to the channel.
In order to receive channel notifications, it is required to create one or more channels and update the Channel subscription to specify which channels we wish to be notified of.
10.3.2. Rules
-
Unlike other notifications, channel notifications are retroactive. It means that when a user subscribes to a channel that already had notifications , they will appear to the user.
-
Channel notifications cannot be deleted, the Housekeeping takes care of it once their life span is exceeded.
-
Notification service administrators can subscribe to any channels. Other users must be part of at least one of the authorized groups defined in the channel in order to subscribe to a channel, unless all groups are authorized (public channels).
10.3.3. Channel Creation
All users are able to create channels for any group. It is required to provide a unique channel name and a list of groups which will be authorized to subscribe to the channel.
It can either be authorized for all groups, a subset of the channel owner groups, or any free input.
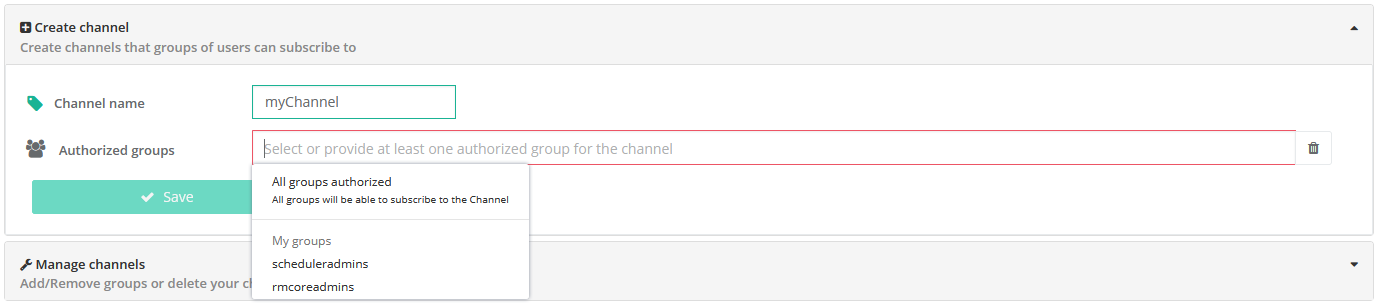
10.3.4. Channel Management
Channel management is where users can update channels by modifying a channel’s name, add or remove authorized groups or delete it.
A notification service administrator is able to update any channels, whether he is the creator of the channel or not. Other users can update only channels that they have created.
To update a channel’s name or authorized groups, simply make the update and click on the Save button.
To delete a channel, click on the Bin icon on the left of the channel definition.
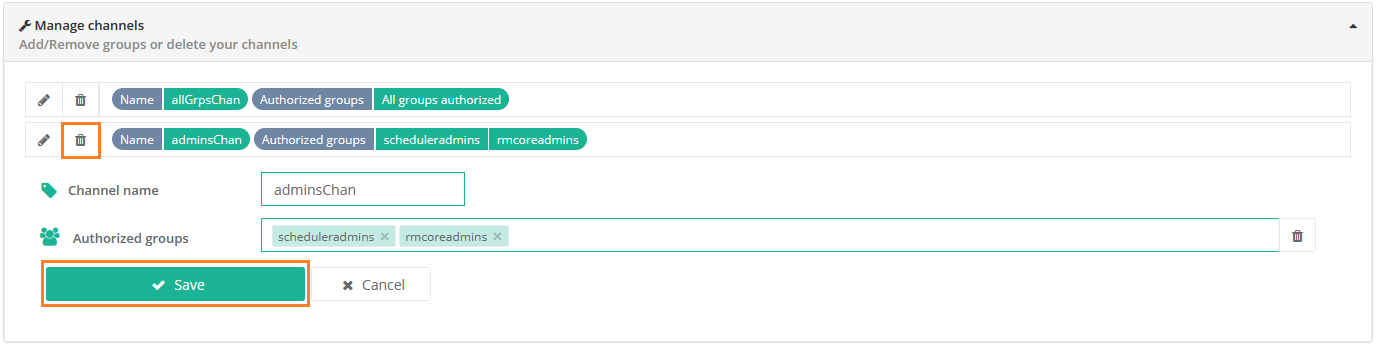
10.3.5. Channel Notification
In order to send a channel notification, a user must append the Channel_Notification task to a Workflow.
The notification’s message, severity and notified groups are configurable by the user in the Channel_Notification.
Simply update the following Task variables values to do so.
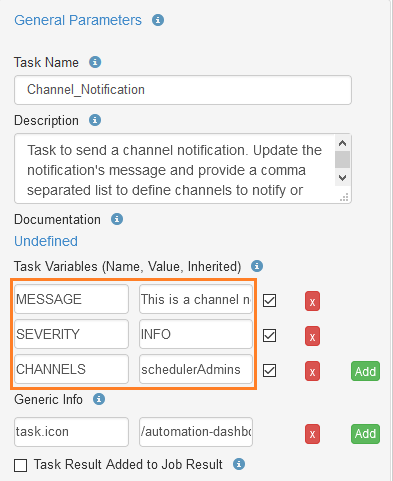
-
MESSAGE: The message that will be displayed to the notified users. This variable is a free input and cannot be empty.
-
SEVERITY: Users can define the notification’s severity by updating this variable. Available severities are INFO, WARNING, ERROR, CRITICAL. The default severity is INFO.
-
CHANNELS: channels that will be notified. It can be a single channel, a comma separated list of channels, or the
Allkeyword.
All (default) means:
- For a notification-service administrator, send a notification to all channels
- For a standard user, send a notification to all authorized channels (the user belongs to an authorized group of these channels).
10.4. Event types
Type |
Readable name |
Severity |
Message |
Description |
|
Job finished |
INFO |
The job is finished |
The job was running and is now finished |
|
Job running |
INFO |
The job is running |
The job was pending and is now running |
|
In-error |
ERROR |
A task in the job encountered an error, the error handling is set to suspend in error task dependencies and set the job In-error |
The job is in-error |
|
Paused |
WARNING |
The job was running and has been paused |
The job is paused |
|
Removed |
INFO |
The job has been removed from the scheduler |
The job is removed |
|
Restarted |
INFO |
The job was in error and the user has restarted it |
The job is restarted after being in-error for a while |
|
Resumed |
INFO |
The job was paused and has been resumed |
The job is resumed |
|
Submitted |
INFO |
The job has been submitted to the scheduler |
The job is submitted to the scheduler |
|
Finished with issues |
ERROR |
A task in the job encountered an error, the error handling is set to ignore it and continue job execution |
The job has finished with errors |
Type |
Readable name |
Severity |
Message |
Description |
|
Task In_Error |
ERROR |
A task in the job encountered an error and has been set In-Error |
A task in the job is In-Error |
|
Task waiting on error |
INFO |
A task in the job is waiting for a new execution attempt after being in error, faulty or failed. |
A task in the job is waiting for restart after an error |
|
Task finished |
INFO |
A task in the job is finished |
A task in the job is finished |
|
In-Error Task finished |
INFO |
A task in the job was in error and is now finished |
An In-Error task in the job is finished |
|
Task running |
INFO |
A task in the job was pending and is now running |
A task in the job is running |
|
Task skipped |
INFO |
The task was not executed, it was the non-selected branch of an IF/ELSE control flow action. |
A task in the job is skipped |
|
Task replicated |
INFO |
A task in the job is replicated |
A task in the job is replicated |
|
Task finished with errors |
ERROR |
A task with no execution attempts left is faulty, failed or in error. |
A task has finished with the an error status |
|
Task progress updated |
INFO |
Task progress updated to x% |
The task progress variable has been updated, it can be a value between 0 and 100. |
|
Task visualization activated |
INFO |
Task visualization activated |
A task’s remote visualisation has been activated |
Type |
Readable name |
Severity |
Message |
Description |
|
Paused |
WARNING |
A user has paused the scheduler, all running jobs run to completion but jobs wont be submitted |
The Scheduler is paused, all running jobs run to completion |
|
Database down |
CRITICAL |
The Schedulers database is down |
The Schedulers database is down |
|
Killed |
WARNING |
A user has killed the Scheduler, ProActive server needs to be restarted |
The Scheduler is killed! The process of the scheduler’s executable is killed. No interaction can be done anymore. |
|
Resumed |
INFO |
The scheduler was paused or frozen and has been resumed |
The Scheduler is resumed! Jobs can be submitted again |
|
Stopped |
WARNING |
The scheduler has been stopped |
The Scheduler is stopped! Jobs cannot be submitted anymore. Already running jobs run to completion, but not pending jobs. |
|
Frozen |
WARNING |
The scheduler has been stopped |
The Scheduler is frozen! All running tasks run to completion, but running jobs wait for the scheduler to resume. |
|
Shutting down |
WARNING |
The scheduler has been shutdown |
The Scheduler is shutting down… The scheduler is shutting down itself. |
|
Started |
INFO |
The scheduler has started |
The Scheduler is started! Jobs can be submitted. |
Type |
Readable name |
Severity |
Message |
Description |
|
Association failed |
CRITICAL |
The server was unable to retrieve the resource |
A Catalog resource is not found, the association changes to FAILED status |
ERROR |
The association |
An association’s status has been updated to FAILED due to the previous execution having an error |
||
Update the association |
Job Planner could not retrieve the calendar of a Workflow-Calendar association. The association’s status has been updated to FAILED. |
|||
|
Cannot submit |
ERROR |
Job-planner was unable to submit the |
Job Planner was unable to submit the workflow from the bucket to the scheduler |
|
Submission postponed |
WARNING |
Submission of the workflow |
A submission has been postponed because the previous execution is still under way |
|
Submission canceled |
WARNING |
Submission of the workflow |
A submission has been canceled because the previous execution is still under way |
The workflow Variables_Propagation in the bucket |
The workflow execution time is before the current time that means we missed an execution and it is not configured to postpone the execution |
|||
The workflow |
Binded to the upper notification, it informs how many execution were missed |
|||
|
Delayed submission executing |
INFO |
The workflow |
A planned workflow execution that has been postponed is now executing |
Job Planner has detect that the execution of the workflow |
The workflow execution time is before the current time that means we missed an execution and it is configured to submit a new execution |
Type |
Readable name |
Severity |
Message |
Description |
|
Started |
INFO |
The Resource Manager has started |
ProActive has been launched, and the Resource Manager has started |
|
Shutting Down |
INFO |
The Resource Manager is shutting down |
ProActive has been stopped and the Resource Manager is shutting down |
|
Shutdown |
INFO |
The Resource Manager is shutdown |
ProActive is stopped, and the Resource Manager is shut down |
|
Node down |
WARNING |
The Node |
A node has been declared as down by the Resource Manager |
|
Node lost |
WARNING |
The Node |
The Resource Manager can not connect to a Node, therefore it is declared as lost |
|
Node removed |
INFO |
The Node |
A Node Source has been undeployed, and the node has been removed |
|
Node added |
INFO |
The Node |
A Node Source has been deployed, and the node has been added |
|
Node Source shutdown |
INFO |
The Node Source |
A Node Source has been undeployed |
|
Node Source removed |
INFO |
The Node Source |
A Node Source has been removed |
|
Node Source defined |
INFO |
The Node Source |
A Node Source has been defined |
|
Node Source updated |
INFO |
The Node Source |
A Node Source has been updated |
|
Node Source created |
INFO |
The Node Source |
A Node Source has been deployed |
10.5. Presets
Presets are not individual event types like the ones described above; instead, they are preconfigured groupings within a subscription’s list of event types. These presets conveniently group related event types, and when selected, automatically add multiple events to the subscription
Name |
Subscription |
Description |
|
Jobs |
Automatically adds the events JOB_IN_ERROR, JOB_FINISHED_WITH_ISSUES, TASK_IN_ERROR, TASK_FINISHED_WITH_ERRORS to the subscription |
10.6. Microsoft teams notifications
To receive Microsoft Teams notifications using the Notification Service Third-Party notification method, some configuration must be applied on both the Microsoft and Notification Service sides.
These configurations are described in the admin guide here and are mandatory to be able to receive Teams notifications.
10.6.1. Configure User Settings
To send Teams notifications, the Third-Party script must connect and retrieve a token using a user’s Microsoft credentials.
The script reads these credentials from the User Settings.
The login is provided as plain text but the password must be encrypted before being saved in the User Settings.
You can see how to encrypt the password Here
Once the password is encrypted:
-
Connect to ProActive and go to the Notification Portal
-
Click on the Configuration tab then open the Settings drop-down
-
Click on the "Add" button, at the right of the Third-Party input row.
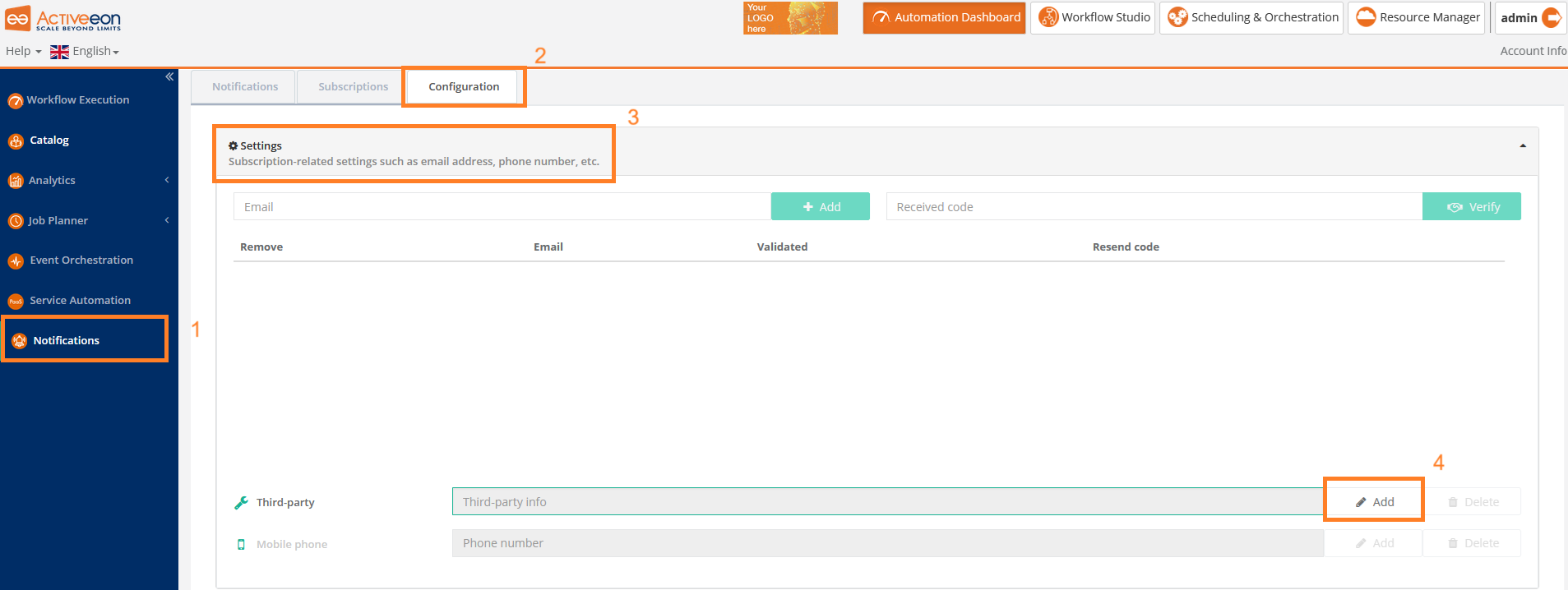
-
Provide your Microsoft login and your encrypted password enclosed by ENC()
-
Click on save
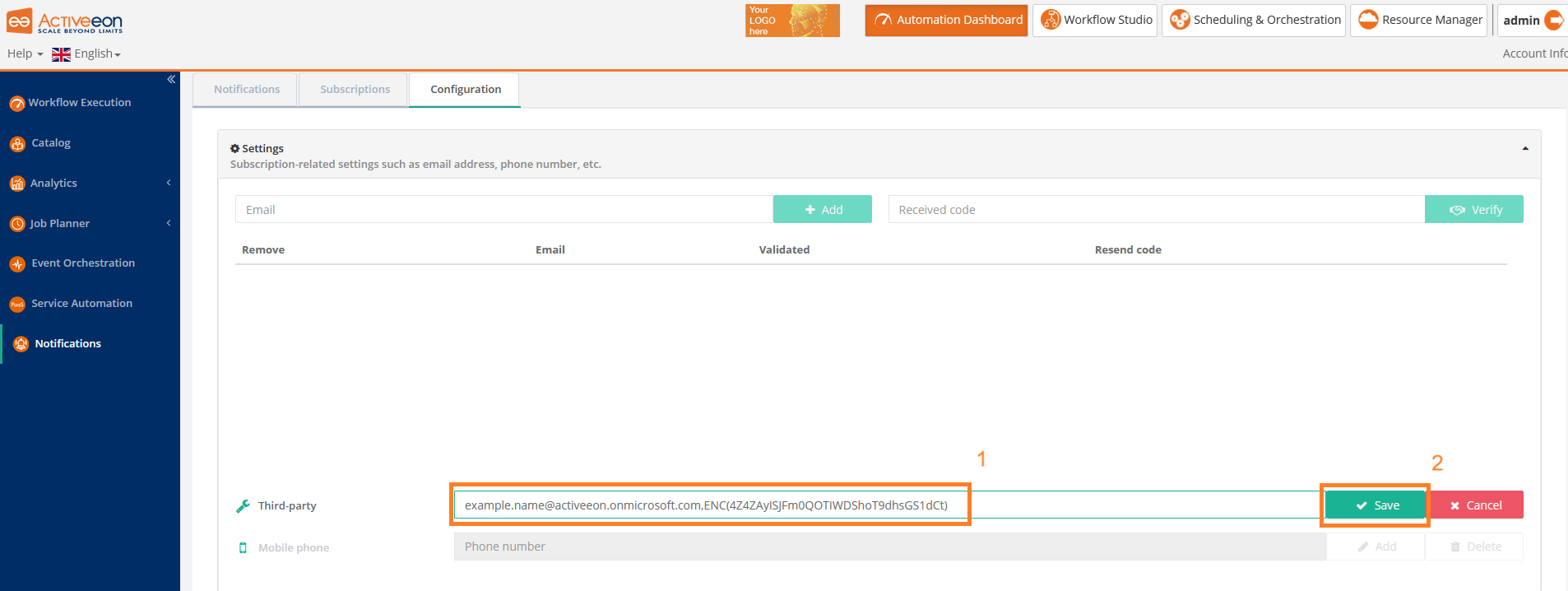
10.6.2. Get microsoft Teams channel URLs
Each subscription that needs to send notifications to Teams must provide channel URLs.
At least one must be provided and it defines the channel(s) where the notification is sent.
You can easily retrieve channel URLs from the Microsoft Teams desktop app or web browser:
And you copy the URL:
10.6.3. Configure subscriptions
Users can decide which subscription notifies which channel.
To do so, the Third-Party param input accepts a list of channel URL, separated by a carriage return or whitespaces.
Finally, the Third-Party notification method should be activated
Here is an example with a Job subscription that notifies two channels when any job is running. The channel URLs have been truncated.
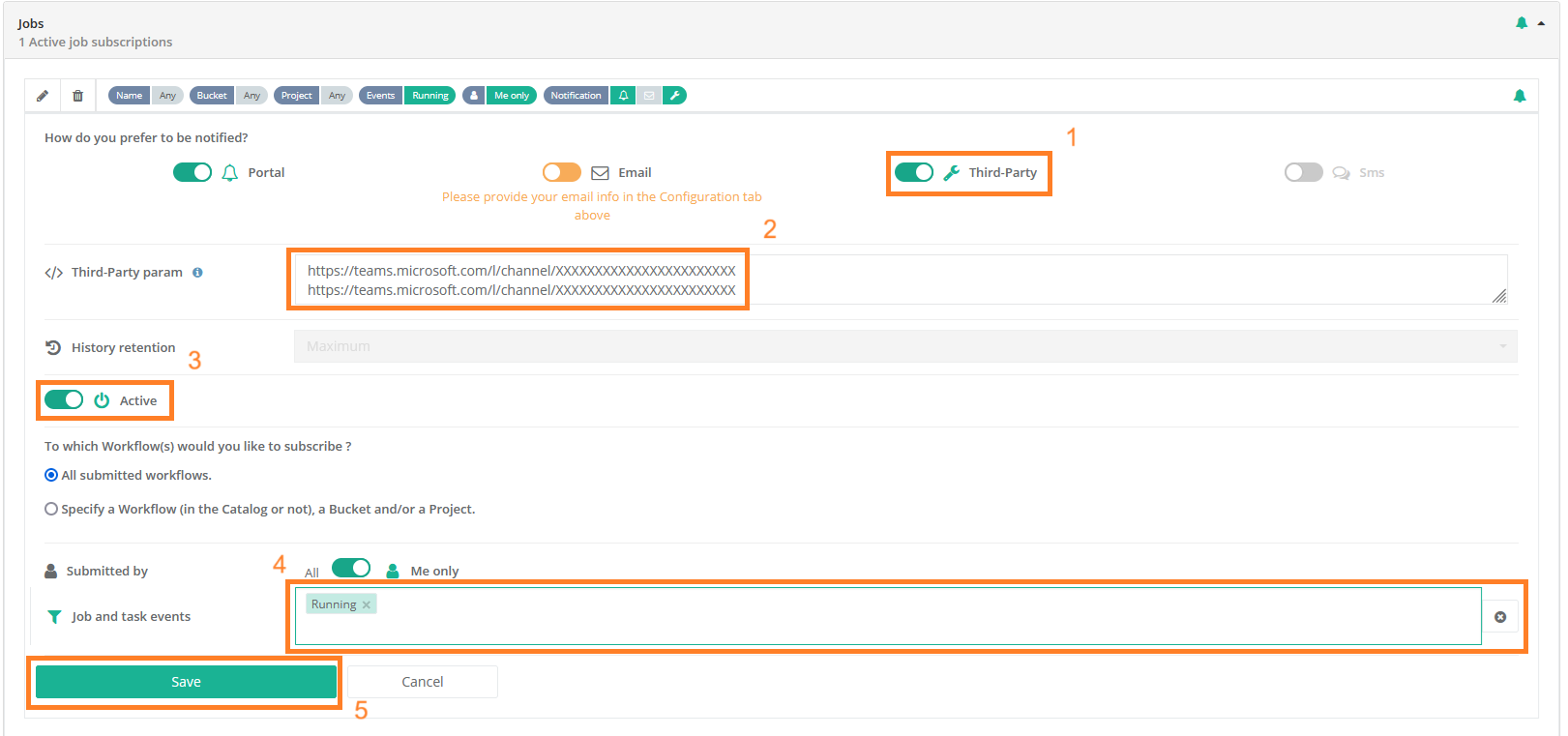
The principle is the same for unique service subscriptions.
The result is a new message in teams channels
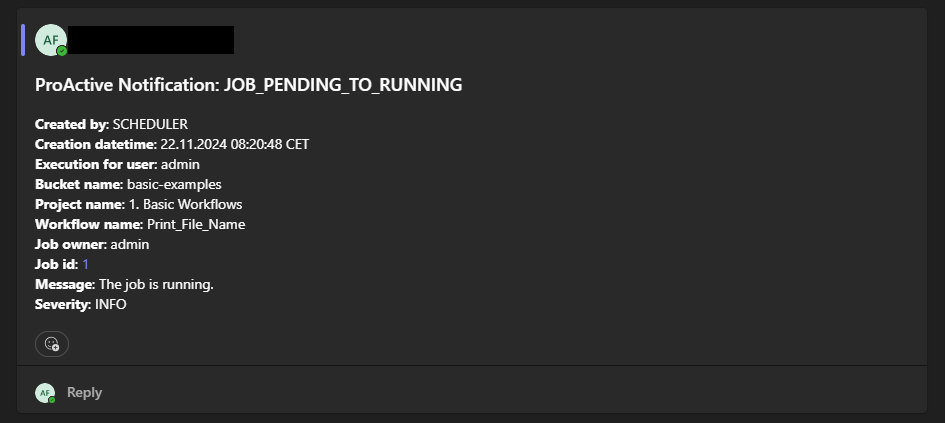
10.7. Slack notifications
To receive Slack notifications using the Notification Service Third-Party notification method, some configuration must be applied to the Notification Service.
This configuration is described in the Admin Guide here.
Once the configuration done, users only need to provide webhooks and activate the Third-Party notification method of subscriptions to start receive Slack notifications.
10.7.1. User Settings webhooks
Users can provide webhooks in their User Settings Third-Party parameter. These webhooks will always be notified by all notifications triggered by all subscriptions, unless the script is configured differently as explained in this section.
To provide User Settings webhooks, simply add the webhooks in the Third-Party input as a comma separated list.
10.7.2. Subscription webhooks
Webhooks provided in Subscriptions are notified only by Notifications created by the Subscription they belong to.
This allows to be notified of precise Events to specific channels.
By default, the script notifies the User Settings webhooks PLUS the Subscription webhooks.
To add Subscription webhooks, simply add webhooks separated by whitespaces or carriage returns in the Third-Party input as show above
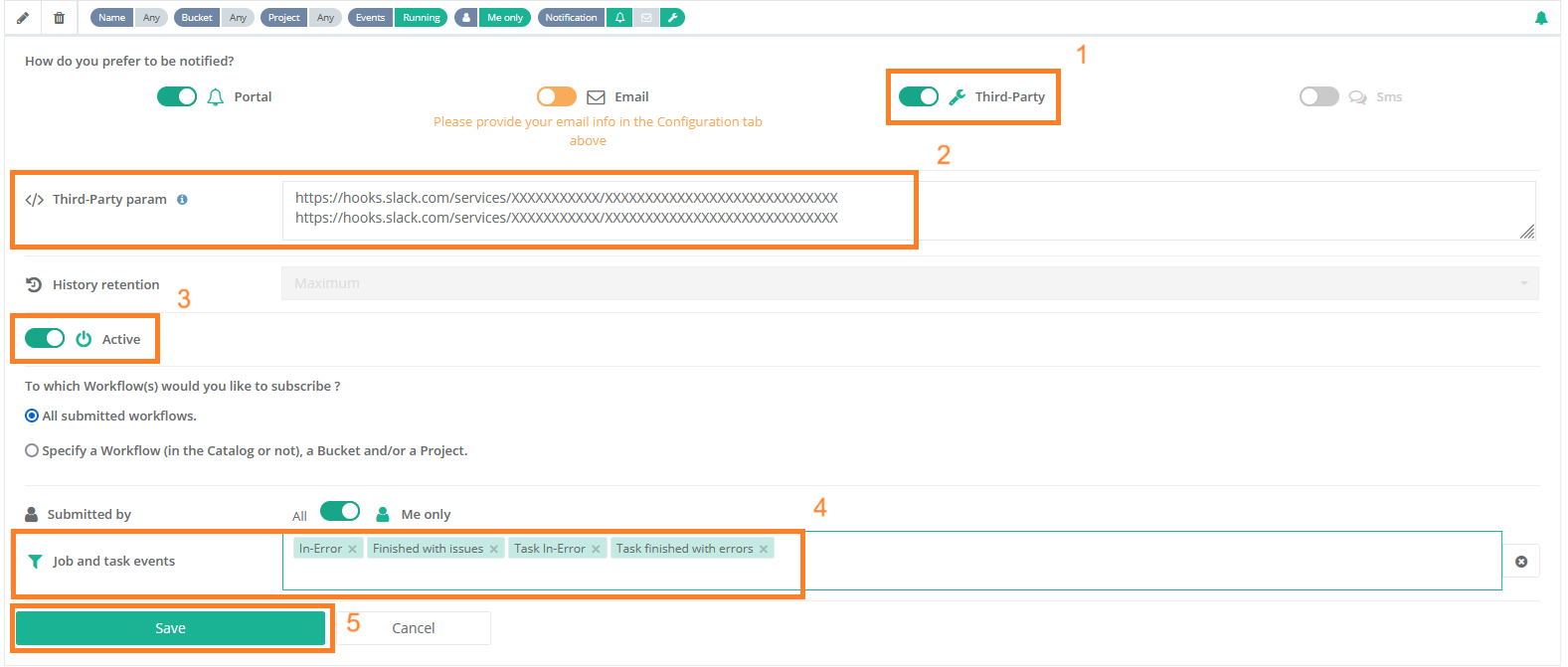
11. Third-party credentials
11.1. Overview
Tasks executed by ProActive
Scheduler might need to use a password or another kind of
credentials to access third-party services or applications. For example
a user might wish to pass his MySQL password to Native Task which runs
a mysql command to dump a database.
In such cases it is often desirable to store the credentials separately from the Workflow definition. ProActive Scheduler provides such facility.
Third-party credentials in ProActive Scheduler are user-defined key-value pairs of strings stored on the server side in encrypted form. The credentials are accessible in the tasks executed by the user via API (Script and Java Tasks) or variable substitution (arguments of Native Tasks and parameters of Java Tasks).
11.2. Managing third-party credentials
Methods to add or remove the credentials and to list the stored credential keys are exposed in both Java and REST APIs.
End users can manage their credentials using the Scheduler Web Interface & Workflow Execution (Portal → Manage third-party credentials) or the Command Line Interface.
11.2.1. Example CLI usage
Add credential:
$ ./bin/proactive-client --put-credential MY_MYSQL_PASSWORD mypassword Credential "MY_MYSQL_PASSWORD" successfully stored.
List credentials (only keys are listed):
$ ./bin/proactive-client --list-credentials [...] MY_MYSQL_PASSWORD
Remove credential:
$ ./bin/proactive-client --remove-credential MY_MYSQL_PASSWORD Credential "MY_MYSQL_PASSWORD" successfully removed.
11.3. Using third-party credentials
11.3.1. In a Script Task
In a Script Task, the credentials script binding is a hash map containing all user’s
credentials:
// mysqlPassword will contain the value corresponding to "MY_MYSQL_PASSWORD" key
mysqlPassword = credentials.get('MY_MYSQL_PASSWORD')
The credentials script binding can also be used in additional scripts defined inside a ProActive Task.
To know in which scripts credentials is available, study the Script Bindings Reference.
|
11.3.2. In Java Task
In a Java Task, the method getThirdPartyCredential of JavaExecutable
returns the credential corresponding to the key passed as parameter:
public class PrintAndReturnCredentialsTask extends JavaExecutable {
@Override
public Serializable execute(TaskResult... results) throws Throwable {
// mysqlPassword will contain the value corresponding to "MY_MYSQL_PASSWORD" key
String mysqlPassword = getThirdPartyCredential("MY_MYSQL_PASSWORD");
[...]
}
}Another way to use credentials in Java tasks is via parameters. If a
parameter contains a string of the form $credentials_<credential
key>, the string is replaced with the value of the corresponding
credential:
<task name="...">
<javaExecutable class="...">
<parameters>
<!-- mysqlPassword will contain the value corresponding to "MY_MYSQL_PASSWORD" key -->
<parameter name="mysqlPassword" value="$credentials_MY_MYSQL_PASSWORD"/>
</parameters>
</javaExecutable>
</task>11.3.3. In a Native Task
Finally, a credential can be passed to a Native Task via
arguments. Note that, as with Java Task parameters, the $credentials_
prefix is necessary. In the example below, /bin/echo will be called
with the value corresponding to the key MY_MYSQL_PASSWORD (if the
key is not present, no replacement occurs):
<task name="Task1">
<nativeExecutable>
<staticCommand value="/bin/echo" >
<arguments>
<argument value="$credentials_MY_MYSQL_PASSWORD"/>
</arguments>
</staticCommand>
</nativeExecutable>
</task>12. Scheduler, Resource Manager, DataSpace, Synchronization, and Signal APIs
From a Script Task, several APIs are accessible via Java objects bound to dedicated script bindings:
-
Scheduler API: using the
schedulerapibinding, it is possible to interact directly with the scheduler server and do several operations (submit jobs, wait for tasks termination, list running jobs, etc.). -
Resource Manager API: using the
rmapibinding, it is possible to interact directly with the RM and do several operations (lock nodes, change node tags, monitor nodes, get thread dump, etc.). -
DataSpace API: the
userspaceuriorglobalspaceuribindings allow to manipulate files present in User or Global spaces. Operations include listing, uploading, downloading, or deleting files. -
Synchronization API: using the
synchronizationapibinding, it is possible to handle advanced task synchronization dynamically.
12.1. Scheduler API
From inside a Script Task, you can use the Scheduler API binding like the following:
// importing necessary classes
import org.ow2.proactive.scheduler.common.job.*
import org.ow2.proactive.scheduler.common.task.*
import org.ow2.proactive.scripting.*
// connect to the scheduler
schedulerapi.connect()
// create a hello world job
job = new TaskFlowJob()
job.setName("HelloJob")
task = new ScriptTask()
task.setName("HelloTask")
task.setScript(new TaskScript(new SimpleScript("println 'Hello World'", "groovy")))
job.addTask(task)
// submitting the job
jobid = schedulerapi.submit(job)
// Wait for the task termination
taskResult = schedulerapi.waitForTask(jobid.toString(), "HelloTask", 120000)
// displaying the task output
println taskResult.getOutput().getAllLogs(false)The complete API description can be found in the SchedulerNodeClient JavaDoc.
The schedulerapi script binding can also be used in additional scripts defined inside a ProActive Task.
To know in which scripts schedulerapi is available, study the Script Bindings Reference.
|
12.2. Resource Manager API
From inside a Script Task, you can use the Resource Manager API binding like the following:
// connect to the rm
rmapi.connect()
// displaying the RM state
full = rmapi.getRMStateFull()
full.getNodesEvent().each { event ->
println(event.getNodeUrl())
println(event.getNodeState())
}
// add node token to the current node
// get current node url
nodeUrl = variables.get("PA_NODE_URL")
rmapi.addNodeToken(nodeUrl, "MyOwnToken")
println "Test rmapi.getTopology() " + rmapi.getTopology()
println "Test rmapi.getExistingNodeSources() " + rmapi.getExistingNodeSources()
println "Test rmapi.getInfrasToPoliciesMapping() " + rmapi.getInfrasToPoliciesMapping()
println "Test rmapi.getConnectionInfo() " + rmapi.getConnectionInfo()
println "Test rmapi.getRMStateFull() " + rmapi.getRMStateFull()
println "Test rmapi.getRMThreadDump() " + rmapi.getRMThreadDump()
println "Test rmapi.getState() " + rmapi.getState()
println "Test rmapi.getSupportedNodeSourceInfrastructures() " + rmapi.getSupportedNodeSourceInfrastructures()
println "Test rmapi.getSupportedNodeSourcePolicies() " + rmapi.getSupportedNodeSourcePolicies()
println "Test rmapi.getVersion() " + rmapi.getVersion()
println "Test rmapi.isActive() " + rmapi.isActive()
// do not forget to disconnect from the rm
rmapi.disconnect();The complete API description can be found in the documentation of RMRestInterface Java interface.
The sessionid argument has to be ignored when using the rmapi script binding.
The rmapi script binding can also be used in additional scripts defined inside a ProActive Task.
To know in which scripts rmapi is available, study the Script Bindings Reference.
|
12.3. DataSpace API
The traditional way to transfer files from the user or global space to a task is by using file transfer directives as described in chapter Data Spaces.
Where file transfer directives are sufficient to cover usual cases, it is sometimes necessary to manipulate directly the dataspace API to have a finer control level.
Below is an example use of this api inside a Script Task:
// connect to the user space
userspaceapi.connect()
// push file
inFile = new File("inFile.txt");
inFile.write("HelloWorld")
userspaceapi.pushFile(inFile, "remoteDir/inFile.txt")
// list files
remotefiles = userspaceapi.listFiles("remoteDir", "*.txt"
println remotefiles
// pull File
outFile = new File("outFile.txt")
userspaceapi.pullFile("remote/inFile.txt", outFile)
println outFile.textThe complete description of user and global space APIs can be found in the DataSpaceNodeClient JavaDoc.
The userspaceapi and globalspaceapi script bindings can also be used in additional scripts defined inside a ProActive Task.
To know in which scripts these bindings are available, study the Script Bindings Reference.
|
12.4. Synchronization API
This Synchronization API allows for both communication and synchronization between Tasks and between Jobs dynamically at execution. It is based on a Key-Value Store offering atomic operations. It enables to easily put into action all classical synchronization patterns: Critical Sections and Mutual Exclusion, Rendez-vous, Barriers, Producer/Consumer…
In summary and for simple use, just go to ProActive Studio and use the predefined templates in the Controls menu (e.g., Key_Value). Use those templates in your own workflow to see how it works. You can further try the examples below to better understand the usage of the Synchronization API.
Task synchronization is traditionally handled by the ProActive Scheduler through Task Dependencies, where dependent ProActive Tasks are started only after their parents Tasks completed.
In some cases, static task dependencies are not enough to synchronize tasks execution.
This is the case when a task depends on the status of another task executed in a different branch of a workflow, a sibling task or even another job/workflow.
For example, let’s suppose workflow A contains a single task A_1 starting an apache server. Task A_1 starts the server and remains alive while the server is up. When workflow A is killed, task A_1 stops the Apache server.
A task B_1 of another workflow B wants to interact with this server.
Problem: task B_1 does not know if the apache server is up and how to contact it.
Using Task Synchronization API, task A_1 can advertise the server URL to the Synchronization Service.
Task B_1 can use Task Synchronization API to wait until the apache server is advertised, it can also perform the necessary operations and advertise task A_1 that the operation is complete and the apache server can be terminated.
As we can see, Task Synchronization API can be used for two-ways synchronization.
Synchronizations can be used in any part of a Task (Pre/Post/Clean Scripts, Task Implementation, Selection Script). Using Synchronization API within Selection Scripts is a way to avoid a Task to be started (consuming a Node) and to be actually doing nothing, just waiting for a specific condition to occur.
12.4.1. Usage
Task Synchronization API is a Java API defined by the following API documentation.
The Synchronization API is connected to a centralized Synchronization Service. This service ensures that each request is executed atomically, and that changes are persisted on disk.
The Synchronization API is available inside ProActive Tasks through the synchronizationapi script binding.
Channels
The Synchronization Service works as a Key-Value Store organized in channels. Each channel acts as a private Key-Value Store.
This means that each put operation is identified by a 3-tuple: <Channel_identifier, Key_binding, Value>.
Users of the Synchronization API are responsible to create channels as fit their needs. Channels have no notion of ownership, a channel created by workflow A started by user Alice can be used by workflow B started by user Bob.
This is because Synchronization API is often used to synchronize workflow tasks across multiple users.
Therefore, channel naming is important and should be precise enough to avoid accidental overlap. Channels should be created when needed and deleted after use.
For example, a channel which is used only inside a specific job instance (to synchronize tasks withing this job) should be created inside some initialization task at the beginning of this job, and deleted in some cleaning task at the end. The channel name should contain the Job Id.
When channels are created, the user can decide if the channel should be persisted on disk or kept in memory only.
On startup, the Synchronization Service contains only the persistent channels which were previously created using the Synchronization API. In-memory channels created before the reboot of the scheduler are lost.
API Description
The Synchronization API is similar to the Java 8 Map interface, with the following differences:
-
It contains methods to create/delete channels and methods to interact with the channel Map itself.
-
Each channel Map operations must take a channel identifier parameter.
-
The Synchronization API supports Java 8 lambdas, but lambdas must be passed as string arguments defining Groovy Closures. For example,
compute("channel1", "key1", "{k, x -> x+1}")instead ofcompute("channel1", "key1", (k, x) -> x+1). -
The Synchronization Service guaranties that multiple operations, coming from different ProActive Tasks, will all be executed atomically.
-
In addition to the methods present in the Java 8 Map interface, Synchronization API provides blocking methods to wait for a specific condition on a channel. This is mainly why this API is called Synchronization, it allows for different ProActive Tasks to be blocked until specific conditions are met.
-
When an error occurs during the Groovy Closure compilation or execution, dedicated exceptions (CompilationException or ClosureEvaluationException) will be thrown.
12.4.2. Examples
Example 1: Simple Key/Value With Selection Script
In this first example, we will show how one task can delay the execution of another task using the Synchronization API and a selection script.

This workflow contains the following Tasks:
-
Init: Initialize the channel. This task creates a channel using the current job id. It also sets a
lockbinding in the key/value store with an initial true value.jobid = variables.get("PA_JOB_ID") synchronizationapi.createChannel(jobid, false) synchronizationapi.put(jobid, "lock", true) println "Channel " + jobid + " created." -
TaskB_Wait: Wait to be unlocked. This task will not be executed until the
lockbinding changed to false. A selection script allows to handle this verification:selected = !(synchronizationapi.get(variables.get("PA_JOB_ID"), "lock")) -
TaskA: Unlock TaskB. This task will sleep for a few seconds and then unlock TaskB using the Synchronization API:
println "Sleeping 5 seconds" Thread.sleep(5000) println "Unlocking Task B" synchronizationapi.put(variables.get("PA_JOB_ID"), "lock", false) -
Clean: Delete the channel. This task simply deletes the channel used in this job. As there is no automatic mechanism to remove channels, it is necessary to delete them explicitly when they are not used any more.
jobid = variables.get("PA_JOB_ID") synchronizationapi.deleteChannel(jobid ) println "Channel " + jobid + " deleted."
Here is output of the Key/Value workflow:
[28t2@trydev.activeeon.com;14:24:22] Channel 28 created. [28t0@trydev.activeeon.com;14:24:28] Sleeping 5 seconds [28t0@trydev.activeeon.com;14:24:33] Unlocking Task B [28t1@trydev.activeeon.com;14:24:40] Task B has been unlocked by Task A [28t3@trydev.activeeon.com;14:24:46] Channel 28 deleted.
| It is also possible to debug the operations performed on the Synchronization Store. This is possible by using the Server Logs associated with the job. Server Logs are very verbose, the [Synchronization] pattern helps to find logs associated with the Synchronization API: |
[2018-04-24 14:24:22,685 de72716883 INFO o.o.p.s.u.TaskLogger] task 28t2 (Init) [Synchronization]Created new memory channel '28' [2018-04-24 14:24:22,786 de72716883 INFO o.o.p.s.u.TaskLogger] task 28t2 (Init) [Synchronization][Channel=28] Put true on key 'lock', previous value was null [2018-04-24 14:24:34,431 de72716883 INFO o.o.p.s.u.TaskLogger] task 28t0 (TaskA) [Synchronization][Channel=28] Put false on key 'lock', previous value was true [2018-04-24 14:24:46,882 de72716883 INFO o.o.p.s.u.TaskLogger] task 28t3 (Clean) [Synchronization]Deleted memory channel '28'
The Complete Workflow example can be downloaded here.
Example 2: Simple Key/Value with Explicit Wait
In this second example, we will show how one task can delay the execution of another task using the Synchronization API and an explicit wait call.
This example is very similar to the first example, but instead of delaying the execution of TaskB using a selection script, TaskB will start its execution and explicitly call the Synchronization API to wait.
-
Tasks Init, TaskA and Clean do not change
-
TaskB_Wait is modified. The selection script is removed and instead the following code is used in the main task definition:
println "Waiting for Task A" synchronizationapi.waitUntil(variables.get("PA_JOB_ID"), "lock", "{k, x -> x == false}") println "Task B has been unlocked by Task A"As you can see, the waitUntil method expects a BiPredicate defined as a string Groovy Closure. The predicate receives two parameters:
kcontains the key, andxcontains the binding associated with this key. This predicate is evaluated on the lock binding, and waits until this binding == false.
Here is the output of the Example 2 workflow:
[29t2@trydev.activeeon.com;14:43:42] Channel 29 created. [29t0@trydev.activeeon.com;14:43:49] Sleeping 5 seconds [29t1@trydev.activeeon.com;14:43:48] Waiting for Task A [29t0@trydev.activeeon.com;14:43:54] Unlocking Task B [29t1@trydev.activeeon.com;14:43:55] Task B has been unlocked by Task A [29t3@trydev.activeeon.com;14:44:01] Channel 29 deleted.
The Complete Workflow example can be downloaded here.
Example 3: Critical Section
In this last example, we will show how we can create a critical section inside a workflow, which means, a section of the workflow which can only be accessed by a configurable number of slots.
The Critical Section workflow is defined with a Replicate Control Structure:
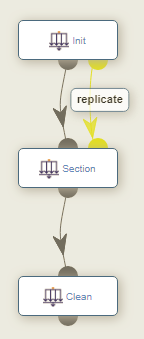
It contains the following Tasks:
-
Init: Initialize the channel. This task creates a channel using the current job id. It also sets a
available_slotsbinding in the key/value store with an initial value based on the workflow user-definedNB_SLOTSjob variable.jobid = variables.get("PA_JOB_ID") synchronizationapi.createChannel(jobid, false) synchronizationapi.put(jobid, "available_slots", Integer.parseInt(variables.get("NB_SLOTS"))) println "Channel " + jobid + " created."This tasks also define a control flow script used to define the number of replicated tasks. The number of replicated tasks is parametrized with the user-defined
NB_TASKSjob variable:runs=Integer.parseInt(variables.get("NB_TASKS")) -
Section: Wait for the critical section to be available. This task will block until the number of available slots is greater than 0. As soon as at least one slot is available, it decrements the
available_slotscounter and perform some computation. When the computation is terminated, it releases the slot by incrementing back theavailable_slotscounter.println "Waiting for available slot" jobid = variables.get("PA_JOB_ID") synchronizationapi.waitUntilThen(jobid, "available_slots", "{k, x -> x > 0}", "{k, x -> x - 1}") println "Enter critical section" // simulate some computation Thread.sleep(10000) println "Release slot" synchronizationapi.compute(jobid,"available_slots", "{k, x -> x + 1}")As you can see, the first method used in this section is waitUntilThen. This method expects both a BiPredicate and a BiFunction defined as strings Groovy Closure.
The semantic of this method is to wait until the predicate is met and, as soon as it is, immediately perform a remapping.
In our scenario, the number of available slots is immediately decremented to reserve a slot and enter the critical section.
Releasing of the slot is performed at the end of the task using the compute method.
-
Clean: Delete the channel. Same code as the previous examples.
Here is the output of the Example 3 workflow:
[3t0@trydev.activeeon.com;16:14:14] Channel 3 created. [3t1@trydev.activeeon.com;16:14:22] Waiting for available slot [3t4@trydev.activeeon.com;16:14:22] Waiting for available slot [3t3@trydev.activeeon.com;16:14:22] Waiting for available slot [3t5@trydev.activeeon.com;16:14:22] Waiting for available slot [3t1@trydev.activeeon.com;16:14:23] Enter critical section [3t4@trydev.activeeon.com;16:14:23] Enter critical section [3t4@trydev.activeeon.com;16:14:33] Release slot [3t1@trydev.activeeon.com;16:14:33] Release slot [3t3@trydev.activeeon.com;16:14:33] Enter critical section [3t5@trydev.activeeon.com;16:14:34] Enter critical section [3t6@trydev.activeeon.com;16:14:38] Waiting for available slot [3t3@trydev.activeeon.com;16:14:43] Release slot [3t5@trydev.activeeon.com;16:14:44] Release slot [3t6@trydev.activeeon.com;16:14:44] Enter critical section [3t6@trydev.activeeon.com;16:14:54] Release slot [3t2@trydev.activeeon.com;16:14:59] Channel 3 deleted.
We can see that no more than two replicated tasks enter the critical section at the same time, and that releasing slots allows new tasks to enter the critical section.
The complete Workflow example can be downloaded here.
Implementing the Critical Section example using selection scripts rather than explicit wait methods is more complex.
The reason behind is that selection scripts are meant to be stateless.
The same selection script is executed on all ProActive Nodes by the Scheduler before deciding if a Node can be used to execute a single Task.
In our use case, we must both decide atomically if a slot is available (stateless) and reserve a slot (stateful). This decision will be performed simultaneously on all available ProActive Nodes.
An example implementation can be downloaded here. It makes use of a reserved_slots binding containing a set of task ids.
|
12.4.3. Conclusion
Task Synchronization API can be used for multiple dynamic synchronization patterns such as:
-
Cross-workflow synchronization
-
Critical Sections
-
Barriers (Wait for several parallel tasks to reach a certain point)
-
Producer / Consumer
A complete example of Producer / Consumer, ServiceDeployerConsumer can be downloaded here.
12.5. Signal API and Templates
The Signal API is a high-level API that enables users to interact with running jobs via signals (we also call them actions).
That is, it allows a job to expose specific signals (e.g., soft_stop to properly finish a job) that can be triggered by users from the Workflow Execution portal or Scheduler portal.
You can try the examples below to better understand how it works.
In summary and for simple use, just go to ProActive Studio and use the predefined templates in the Controls bucket, 4. Signal Templates project: for example: Check_For_Signals, Wait_For_Signals, Wait_For_Signals_Reactive or Wait_For_Signals_With_Variables. Fill up the Task Variable SIGNALS, and use those templates in your own workflow to be able to receive input from, for instance, the Workflow Execution portal or Scheduler portal.
Check_For_Signals is a template workflow composed of two tasks. The first sends a ready notification for the signals specified in the variable SIGNALS'. The second task checks if one signal is received, and if not, the workflow runs in a loop where each iteration lasts one minute. This workflow allows users to do an iterative processing, and decide at each iteration to continue this processing or not, i.e., (i) declare being ready to receive one or more signals, (ii) do some processing, then (iii) receive signals and decide whether to continue the processing or not.
Wait_For_Signals is a template workflow that contains a single task, which sends a ready notification for the specified signals in the 'SIGNALS' variable, then checks if one or more signals are received by the job. If not, the workflow runs in a loop where each iteration lasts one minute. This workflow allows users to iteratively wait for the reception of one or more signals, then trigger some processing.
Wait_For_Signals_Reactive is a template workflow that sends a ready notification for all specified signals in the 'SIGNALS' variable, then waits until one signal among those specified is received. This workflow contains no loop. It performs a blocking wait, then immediately triggers some processing at a signal reception.
Wait_For_Signals_With_Variables is a template workflow that uses signals having input parameters. It contains a single task that sends a ready notification for all the signals (with input parameters) specified in the variable SIGNALS, then loops until one signal among those specified is received by the job. The signal input parameters have predefined values that can be changed when sending the signal.
At a more detailed level and advanced use, the Signal API allows jobs and users to exchange signals using a communication channel provided by the synchronization API. The typical usage scenario of the Signal API is the following:
-
Signals are defined by their name and, optionally, a list of variables. Variables attached to a signal have the same structure as Workflow variables but are declared exclusively using the Signal API.
-
If the signal has variables, then a new window will appear where the user can set the variables values and then send the signal with variables to the job. If the signal does not have variables then the window will not appear. Adding variables to a signal allows to enhance the manual control of the workflow execution. After receiving the signal with attached variables, the workflow will then need to process this information and react accordingly (e.g. continue a calculation with a new set of parameters, etc…)
-
A job declares to be ready to handle one or more signals that can have attached variables. The signals are then displayed in the Workflow Execution portal or Scheduler portal(e.g., display the
soft_stopsignal). -
The job waits to receive these signals, or check for their reception regularly.
-
A user clicks on the signal displayed in the Workflow Execution portal or Scheduler portal (e.g., click on the
soft_stopsignal), which sends this signal to the job. -
At the signal reception, the job executes the corresponding behavior (defined in the workflow). When the signal has attached variables, variables must be valid according to their model specification (see Variable Model). Sending a signal will not be possible unless they are validated.
As already mentioned, the Signal API uses the synchronization API to store jobs' signals, with respect to the following specifications:
-
It uses a single persistent channel (called PA_SIGNALS_CHANNEL + {jobId}) to store the signals and variables of all jobs. The signal channel contains an entry per signal.
-
Job signals are automatically removed when the job execution finishes (i.e., the job is in the status Finished, Cancelled, Failed or Killed).
The Signal API is based on the synchronization API. However, these APIs are intended for different purposes. The Synchronization API is used to exchange information (e.g., messages) between tasks and between jobs, whereas the Signal API is useful to exchange signals between a job and users (via the Workflow Execution portal or the REST API), it cannot be used to send signals from one job to another.
12.5.1. Usage
Task Signal API is a Java API defined by the following API documentation.
The Signal API is available inside ProActive Tasks through the signalapi script binding.
It is easy to use, and offers a set of basic operations on signals summarized as follows:
-
readyForSignal: declares that the current job is ready to receive and handle one or more signals with or without variables. Variables are passed as a list of JobVariable objects This operation constructs new signals (by adding the prefix
ready_to the input signals), then adds them to job signals. For example, if a job declares ready for the signalsoft_stop, the signalready_soft_stopis added to the set of job signals. Additionally, if the input signal (e.g.,soft_stop) already exists among the job signals (which means that it has been sent and handled previously), the operation ready for signal automatically removes it, thus the job is ready again to receive and handle the same signal. -
sendSignal, sendManySignals: sends programmatically one or more signals with or without variables given as input to the current job signals. This operation removes the corresponding ready signals if they already exist. For instance, sending
soft_stopremoves the signalready_soft_stopif it already exists among the job signals. Though signals are meant to be sent manually by a human user through to ProActive web portals, it is also possible to use these methods to send them programmatically inside the workflow. -
checkForSignals: verifies whether all of the signals given as input exist among the set of job signals.
-
waitFor, waitForAny: blocking instruction that waits until one signal (among those given as input) is added to the set of job signals. The instruction waitFor will return a map that represents the name and value of the signal variables. waitForAny instruction returns the first signal object that is received among those given as input
-
removeSignal, removeManySignals: removes one or more signals from the set of job signals.
-
getJobSignals: returns the current job signals and variables.
In addition to the above operations available within ProActive Tasks, users and third-party systems can send signals to a specific job via ProActive Signals REST endpoint.
12.5.2. Examples
Standard and simple use with predefined tasks in the Control template menu
-
Check_For_Signals: a control pattern that executes a loop until one ore more signals, given as input, are received.
-
Wait_For_Signals: a blocking control pattern that blocks the task execution waiting for the reception of one or more signals given as input.
Advanced use with Signal templates
The Signal menu contains many workflow examples that use all signal operations. Below, we give an example of a groovy code that uses some Signal API operations.
//Declare that the current job is ready to receive and handle the 'soft_stop' signal
signalapi.readyForSignal("soft_stop")
//Display current job signals
println("Job signals "+ signalapi.getJobSignals())
//Wait util the 'soft_stop' signal is sent (via the Workflow Execution portal, Scheduler portal or REST API)
signalapi.waitFor("soft_stop")
//Remove the 'soft_stop' signal from the set of job signals
signalapi.removeSignal("soft_stop")Here is another example of a groovy code that uses some Signal API operations with signal variables.
import org.ow2.proactive.scheduler.common.job.JobVariable
//Declare the signal variables
List <JobVariable> signalVariables = new java.util.ArrayList<JobVariable>()
signalVariables.add(variables.get("INTEGER_VARIABLE"))
signalVariables.add(variables.get("BOOLEAN_VARIABLE"))
//Declare that the current job is ready to receive and handle the 'soft_stop' signal with the given variables
signalapi.readyForSignal("soft_stop", signalVariables)
//Display current job signals
println("Job signals "+ signalapi.getJobSignals())
//Wait util the 'soft_stop' signal with variables is sent (via the Workflow Execution portal, Scheduler portal or REST API)
outputParameters = signalapi.waitFor("soft_stop")
//The outputParameters represent a hashmap containing the names of the variables and their values entered by the user
println "Output parameters = " + outputParameters
//Remove the 'soft_stop' signal from the set of job signals
signalapi.removeSignal("soft_stop")
Usage of the Signals REST endpoint
Below, we provide an example based on curl, which shows how to use the Signals REST endpoint for sending a signal to a specific job:
curl -X POST -H "sessionid:$sessionid"
http://try.activeeon.com:8080/rest/scheduler/job/job_id/signals?signal="soft_stop"12.5.3. Conclusion
The Signal API allows users to interact with jobs during their execution, thus enabling to impact and change jobs' behaviors at runtime. Many use cases can be fulfilled using this API. For instance:
-
Softly stopping a job: when the stop signal is received, the job executes some code that properly finish this job.
-
Stop or continue job execution based on the user decision: a job suspends its execution waiting for the user to send a signal, either stop or continue.
-
Scaling up and down resources on user demand: a job that deploys resources (e.g., compute resources, workers/agents, etc) can scale up and down these resources when receiving the corresponding signals from users (via the Workflow Execution portal), or from third-party systems (via the Signals REST endpoint).
13. ProActive Modules APIs
In addition to the core component APIs described above, ProActive workflow tasks can also interact with other ProActive Modules such as Service Automation and Notification Service.
13.1. ProActive Service Automation (PSA) API
The ProActive Service Automation API, or ProActive Service Automation Client, is a way by which a workflow can communicate with the Service Automation module
The ProActive Service Automation Client hides the complexity of building and sending HTTP requests manually by providing ready-to-use code callable from various tasks.
Below is an example of a groovy script starting a managed service.
| This example has been truncated for readability and is not meant to be used as is. |
// Import necessary classes from the Service Automation Client
import org.ow2.proactive.pca.service.client.ApiClient
import org.ow2.proactive.pca.service.client.api.ServiceInstanceRestApi
import org.ow2.proactive.pca.service.client.model.ServiceInstanceData
import org.ow2.proactive.pca.service.client.model.ServiceDescription
import com.google.common.base.Strings;
// Get session id using the Scheduler API
def sessionId = schedulerapi.getSession()
// Create a ServiceInstanceRestApi object
def pcaUrl = variables.get('PA_CLOUD_AUTOMATION_REST_URL')
def apiClient = new ApiClient()
apiClient.setBasePath(pcaUrl)
def serviceInstanceRestApi = new ServiceInstanceRestApi(apiClient)
// Read workflow variables
def serviceId = variables.get("SERVICE_ID")
def instanceName = variables.get("INSTANCE_NAME")
def serviceActivationWorkflow = variables.get("SERVICE_ACTIVATION_WORKFLOW")
// Prepare service description
ServiceDescription serviceDescription = new ServiceDescription()
serviceDescription.setBucketName(bucketName)
serviceDescription.setWorkflowName(startingWorkflowName)
// Run service
def serviceInstanceData = serviceInstanceRestApi.createRunningServiceInstance(sessionId, serviceDescription, Integer.parseInt(variables.get("PA_JOB_ID")))
// Acquire service Instance ID
def serviceInstanceId = serviceInstanceData.getInstanceId()
// Acquire service endpoint
serviceInstanceData = serviceInstanceRestApi.getServiceInstance(sessionId, serviceInstanceId)
endpoint = serviceInstanceData.getDeployments().iterator().next().getEndpoint().getUrl()
// Store variables and result
variables.put("INSTANCE_ID_" + instanceName, serviceInstanceId)
variables.put("ENDPOINT_" + instanceName, endpoint)
result = endpointThe complete ProActive Service Automation Client API is available in the javadoc Service Automation Client JavaDoc.
13.2. Notification Service API
The Notification Service API, or Notification Client, is a way by which a workflow can communicate with the Notification Service
The Notification Client hides the complexity of building and sending HTTP requests manually by providing ready-to-use code callable from various tasks.
Below is an example of how to create a Notification in the Notification Portal using the Notification Client:
// Import necessary classes from the Notification Client
import org.ow2.proactive.notification.client.ApiClient
import org.ow2.proactive.notification.client.api.EventRestApi
import org.ow2.proactive.notification.client.model.EventRequest
import org.ow2.proactive.notification.client.model.Event
import org.ow2.proactive.notification.client.ApiException
// Get the notification-service URL
def notifUrl = variables.get('PA_NOTIFICATION_SERVICE_REST_URL')
def apiClient = new ApiClient()
apiClient.setBasePath(notifUrl)
// Instantiate the EventRestApi class, the class that effectively sends HTTP requests
def eventRestApi = new EventRestApi(apiClient)
// Get the current job id
def jobId = new Long(variables.get("PA_JOB_ID"))
// Set the Notification's message
def eventMessage = "This is a message"
// Set the Notification's severity
def eventSeverity = EventRequest.EventSeverityEnum.INFO
// Get session id
schedulerapi.connect()
def sessionId = schedulerapi.getSession()
// Create the eventRequest object
def eventRequest = new EventRequest()
.bucketName(genericInformation.get("bucketName"))
.workflowName(variables.get("PA_JOB_NAME"))
.eventType(EventRequest.EventTypeEnum.CUSTOM)
.eventSeverity(eventSeverity)
.jobId(jobId)
.message(eventMessage);
try {
// Send the POST request to create the Notification
result = eventRestApi.createEvent(sessionId, eventRequest).toString()
println(result)
} catch (ApiException e) {
System.err.println("Exception when calling EventRestApi#createEvent")
e.printStackTrace();
}By using this groovy script, workflow designers can create custom Notifications anywhere in their workflows.
The complete Notification Client API is available in the javadoc Notification Client Javadoc.
14. Scheduling policies
See Admin Guide to configure scheduling policies.
14.1. Earliest deadline first (EDF) policy
Scheduler has Earliest deadline first policy (EDF policy) that prioritizes jobs with deadlines.
Overall, the general principal is the following: a job that needs to be started as soon as possible to meet its deadline
taking into account its execution time has higher priority.
The EDF policy considers two Generic Information items: JOB_DDL and JOB_EXEC_TIME.
JOB_DDL represents job deadline. Job deadline can be set in one of the following format:
-
absolute format:
YYYY-MM-dd`T`HH:mm:ss+ZZ, e.g.2018-08-14T08:40:30+02:00 -
relative (to the submission time) format:
+HH:mm:ss, e.g.+5:30:00, or+mm:ss, e.g.+4:30, or+ss, e.g.+45(45 seconds)
If job deadline is absolute then its value equals to JOB_DDL.
If job deadline is relative then its value equals to submission time + JOB_DDL.
JOB_EXEC_TIME represents job expected execution time in the following format: HH:mm:ss , e.g. 12:30:00, 5:30:00,
or mm:ss, e.g. 4:30, or ss, e.g. 45 (45 seconds).
EDF policy orders jobs by applying the rules below. The rule considers jobs at submission time when they are still pending, and orders them by priority.
Thus EDF policy applies these rules (in the given order) until one rule actually applies. Here is the ordered list of rules for the EDF policy:
-
compare job’s intrinsic priority (HIGHEST, HIGH, NORMAL, LOW, LOWEST)
-
job with deadline has priority over job without deadline
-
job that is already started has priority over job that has not yet started
-
job that started earlier has priority over job that was started later
-
job with the earliest
JOB_DDLminusJOB_EXEC_TIMEhas a priority -
job with earliest submission time.
14.1.1. Email notifications
EDF policy sends 3 types of email notifications:
-
(Arriving soon) When job deadline is at risk (if the job is not started in the next X minutes, its deadline will be missed)
-
When job will likely miss its deadline (i.e if the provided
JOB_EXEC_TIMEexceeds the left time until the deadline) -
(Arriving soon) When job has already missed its deadline.
Policy sends emails to the address specified in EMAIL Generic Information of the job.
To enable email notifications see Admin Guide.
15. Data Connectors
The data-connectors bucket contains diverse generic data connectors for the most frequently used data storage systems (File, SQL, NoSQL, Cloud, ERP). The aim of a data connector is to facilitate and simplify data access from your workflows to external data sources.
15.1. File
The File connectors allow to import and export data from HTTP, FTP and SFTP servers. We begin by presenting FTP, FTPS and SFTP connectors then, URL connector.
15.1.1. FTP, FTPS and SFTP connectors
The FTP, FTPS and SFTP file connector workflows consists of two tasks:
-
Import_from_FTP/FTPS/SFTP_Server: Downloads files or folders recursively from an FTP/FTPS/SFTP server to the data space (global or user space).
-
Export_to_FTP/FTPS/SFTP_Server: Uploads files or folders recursively from the data space (global or user space) to an FTP/FTPS/SFTP server.
Variables:
The FTP, FTPS and SFTP connectors share the same list of variables with the exception of the FTPS connector which has in addition two other variables related to the SSL Certificate configuration. Consequently, we describe these variables in the following table using a unique notation.
Variable name |
Description |
Scope |
Required? |
Type |
Default/Examples |
|
Server host. |
Workflow, both Tasks |
Yes |
String |
|
|
Listening port. |
Workflow, both Tasks |
No |
Integer |
e.g. |
|
Username to use for the authentication. |
Workflow, both Tasks |
Yes |
String |
e.g. |
|
Either a file name or a wildcard string pattern. |
Task |
Yes |
String |
e.g. |
|
Either an |
Task |
No |
String |
e.g. |
|
Remote |
Task |
No |
String |
e.g. |
The following table describe the specific workflow variables of the FTP Connector to Import/Export file(s) from/to an FTP server.
Variable name |
Description |
Scope |
Required? |
Type |
Default/Examples |
|
Third-party credential storing the password associated with the given user name. |
Workflow, both Tasks |
Yes |
String |
The following table describe the specific workflow variables of the SFTP Connector to Import/Export file(s) from/to an SFTP server.
Variable name |
Description |
Scope |
Required? |
Type |
Default/Examples |
|
Authentication method to use either password or private key. |
Workflow, both Tasks |
Yes |
String |
Values: |
|
If AUTHENTICATION_METHOD = SSH_PASSWORD, it specifies the SSH password to be provided in the third-party credentials. |
Workflow, both Tasks |
Yes |
String |
|
|
If AUTHENTICATION_METHOD = SSH_PRIVATE_KEY, it specifies the SSH private key to be provided in the third-party credentials. |
Workflow, both Tasks |
Yes |
String |
|
|
If AUTHENTICATION_METHOD = SSH_PRIVATE_KEY, it specifies the SSH private key passphrase. |
Workflow, both Tasks |
Yes |
String |
e.g. |
The following table describe the specific workflow variables of the FTPS Connector to Import/Export file(s) from/to an FTP server over an SSL/TLS certificate.
Variable name |
Description |
Scope |
Required? |
Type |
Default/Examples |
|
If true, enable client certificate authentication. |
Workflow |
Yes |
Boolean |
Default: |
|
Client SSL certificate credential. |
Workflow |
No |
String |
e.g. |
|
The private key credential. |
Workflow |
No |
String |
e.g. |
|
The password to protect the key. |
Workflow |
No |
String |
e.g. |
|
The alias of the key to use, may be null in which case the first key entry alias is used. |
Workflow |
No |
String |
e.g. |
|
If true, enable to verify server certificate. |
Workflow |
Yes |
Boolean |
Default: |
|
If true, enable to provide server certificate. |
Workflow |
No |
Boolean |
Default: |
|
Public Server SSL certificate. |
Workflow |
No |
String |
e.g. |
How to use this connector:
The connector requires the following third-party credentials: {key: <PROTOCOL>://<username>@<hostname>, value: PASSWORD} where <PROTOCOL> can take one of the following values: {ftp, ftps, sftp}. Please refer to the User documentation to learn how to add third-party credentials.
15.1.2. URL connector
The URL connector allows, in addition, to import data using HTTP and HTTPS protocols.
Variables:
Variable name |
Description |
Scope |
Required? |
Type |
Default/Examples |
|
Link to a file accessible using HTTP or HTTP protocols. |
Task |
Yes |
String |
|
|
Local relative path to which we download file(s).
LOCAL_RELATIVE_PATH can contain either a path to a file, a directory terminated by |
Task |
No |
String |
e.g. |
|
If set to |
Task |
Yes |
Boolean |
false |
15.2. SQL
In this part, we first present the data connector tasks that allow users to access and manipulate data of the most frequently used databases, then we show how to use pooled connection to SQL databases across multiple task executions.
15.2.1. Data Connectors
The data connectors allow to import and export data from and to Relational DataBase Management Systems (RDBMS). Currently, we have connectors for MySQL, Oracle, PostgreSQL, Greenplum and SQL Server.
All SQL connector workflows are composed of two tasks:
-
Import_from_<Database>: Import data from an SQL database server to be processed in the same workflow or just to be stored as a csv file in the data space.
-
Export_to_<Database>: Export data from the data space (global or user space) to an SQL database server.
where Database ∈ {MySQL, Oracle, PostgreSQL, Greenplum and SQL Server}
Variables:
All SQL connectors share the same list of variables. Consequently, we describe them in the following table using a unique notation.
Variable name |
Description |
Scope |
Required? |
Type |
Default/Examples |
|
Label or the IP address of the server hosting the database. |
Workflow, both Tasks |
Yes |
String |
|
|
Listening port. |
Workflow, both Tasks |
No |
Integer |
e.g. |
|
Username to use for connecting to the database. |
Workflow, both Tasks |
Yes |
String |
|
|
Database name. |
Workflow, both Tasks |
Yes |
String |
e.g. |
|
Requires an SQL query or a table name to fetch data from. |
Import Task |
Yes |
String |
e.g. |
|
Relative path in the data space used to save the results in a CSV file. |
Import Task |
No |
String |
e.g. |
|
Task result output type ( |
Import Task |
No |
String |
Values: Default: |
|
The table to insert data into. |
Export Task |
Yes |
String |
e.g. |
|
Indicates the behavior to follow when the table exists in the database amongst: - fail: If table exists, do nothing. - replace: If table exists, drop it, recreate it, and insert data. - append: (default) If table exists, insert data. Create if does not exist. |
Export Task |
Yes |
String |
Default: |
|
- It can be a relative path in the dataspace of a csv file containing the data to import. - or a valid URL amongst |
Export Task |
Yes |
String |
e.g. |
How to use this task:
When you drag & drop an SQL connector, two tasks will be appended to your workflow: an import task and an export task. Each task can be used as a separate component in an ETL pipeline; thus, you can keep one of them depending on your needs and remove the other or you can use them both.
The task requires the following third-party credential:
{key: <mysql|postgresql|sqlserver|oracle|greenplum>://<<USER>@<<HOST>:<<PORT>, value: PASSWORD}.
e.g.
| key | value |
|---|---|
|
your |
|
your |
This is a one-time action and will ensure that your credentials are securely encrypted. Please refer to the User documentation to learn how to add third-party credentials.
In the import mode, the output containing the imported data takes one or many of the following forms:
-
in a CSV format to saved to:
-
the
OUTPUT_FILEin the data space if specified by the user -
and to the
resultvariable to make is previewable in the scheduler portal and to make it accessible for the next tasks.
-
-
in a JSON format using the variable
DATAFRAME_JSON.
15.2.2. Database Connections Pooling
To allow the persistence of a single connection across multiple SQL tasks (basically when running several tasks concurrently on the same machine), we have implemented the connection pooling feature to any external SQL database based on the HikariCP Framework. This feature is illustrated using four workflow templates: SQL_Pooled_Connection_Query, SQL_Pooled_Connection_Update, SQL_Pooled_Connection_Procedure_Update and SQL_Pooled_Connection_Procedure_Query, each designed as a single-task workflow.
Variables:
The variables outlined in the table below are applicable to all four workflow templates.
Variable name |
Description |
Scope |
Required? |
Type |
Default/Examples |
|
Name of the relational database management system. |
Workflow, Task |
Yes |
String |
Values: |
|
Name of the jdbc driver which provides access to data in the chosen relational DBMS. |
Workflow |
Yes |
String |
e.g. |
|
Server host. |
Workflow, Task |
Yes |
String |
|
|
Listening port. |
Workflow, Task |
No |
Integer |
e.g. |
|
Username to use for connecting to the database. |
Workflow, Task |
Yes |
String |
e.g |
|
Database name. |
Workflow, Task |
Yes |
String |
e.g. |
|
If secure communication is enabled for the Metadata Manager repository database, you must configure additional JDBC parameters. |
Workflow |
NO |
String |
e.g. |
|
HikariCP framework provides many data source properties that can be used to configure the DB pooled connection such as autoCommit, maximumPoolSize, maxLifetime, idleTimeout …. You can add as many properties as you want. For each one, please add a new task variable where the variable name is the property name having "POOL_" as a prefix and the variable value is the property value. For more info, please refer to https://github.com/brettwooldridge/HikariCP. |
Workflow, Task |
No |
String |
e.g. |
The following table describe the specific task variables of the SQL_Pooled_Connection_Procedure_Query and SQL_Pooled_Connection_Procedure_Update.
Variable name |
Description |
Scope |
Required? |
Type |
Default/Examples |
|
To change or update data, you have to use CREATE, INSERT , UPDATE , or DELETE statements. To query data, you have to perform SELECT statements. |
Task |
Yes |
String |
e.g. |
The following table describe the specific task variables of the SQL_Pooled_Connection_Procedure_Query and SQL_Pooled_Connection_Procedure_Update.
Variable name |
Description |
Scope |
Required? |
Type |
Default/Examples |
|
A string representing the stored procedure name, optionally followed by its parameters. For example: myprocedure, myprocedure(), or myprocedure(1, 'test', true, 2023-01-01). Note that string parameters should be enclosed in single quotes (''). |
Task |
Yes |
String |
e.g. |
In addition to the aforementioned variables, SQL_Pooled_Connection_Query and SQL_Pooled_Connection_Procedure_Query workflow has three more variables.
Variable name |
Description |
Scope |
Required? |
Type |
Default/Examples |
|
If set to |
Task |
Yes |
String |
Values: |
|
Name of the file to be transferred inside the Data Space where the results of the executed procedure will be saved in CSV format. |
Task |
No |
String |
e.g. |
|
if not empty, the value will be the name of a variable that contains the resultSet of the query (converted into a List of Maps). This variable can be used in other tasks. |
Task |
No |
String |
e.g. |
How to use these workflows:
The scheduler should be configured in non-fork mode to execute tasks in a single JVM rather than starting a dedicated JVM to run the task (In $PROACTIVE_HOME/config/scheduler/settings.ini, set pa.scheduler.task.fork=false).
For proper execution, a data connector task requires adding third-party dependencies to its classpath, specifically JDBC jar libraries. Please refer to the Admin guide documentation to learn how to add third party libraries.
In case the password is required, you have to add the following third-party credential: {key: <mysql|postgresql|sqlserver|oracle|hsqldb:hsql>://<USERNAME>@<HOST>, value: PASSWORD}. This is a one-time action and will ensure that your credentials are securely encrypted. Please refer to the User guide documentation to learn how to add third-party credentials.
15.3. NoSQL
The NoSQL connectors allow to import data from NoSQL Databases. Currently, we have connectors for MongoDB, Cassandra and Elasticsearch. All NoSQL connector workflows are composed of two tasks:
-
Import_from_<Database>: Import data from a NoSQL database server to be processed in the same workflow or just to be stored as a csv file in the data space.
-
Export_to_<Database>: Export data from the data space (global or user space) to a NoSQL database server.
15.3.1. MongoDB
Variables:
Variable name |
Description |
Scope |
Required? |
Type |
Default/Examples |
|
Label or the IP address of the server hosting the database. |
Workflow, Import Task, Export Task |
Yes |
String |
Default value: |
|
Listening port. |
Workflow, Import Task, Export Task |
No |
Integer |
Default value: |
|
Username to use for connecting to MongoDB server if authentication is required. |
Workflow |
No |
String |
e.g. |
|
Database to use. In export mode, it is created if it does not exist. |
Workflow, Import Task, Export Task |
Yes |
String |
e.g. |
|
Collection to use. In export mode, it is created if it does not exist. |
Workflow, Import Task, Export Task |
Yes |
String |
e.g. |
|
Requires a NoSQL query to fetch data. If empty ( |
Import Task |
No |
String |
e.g. |
|
Relative path in the data space used to save the results in a JSON file. |
Import Task |
No |
String |
e.g. |
|
If the imported data is labeled for machine learning, a label attribute can be specified using this variable. |
Import Task |
No |
String |
e.g. |
|
A JSON Object/Array to be inserted in MongoDB. This variable can: - A String describing the JSON Object/Array - A relative path in the data space of a JSON file. |
Export Task |
Yes |
String |
e.g.
or |
How to use this task:
The task might require (if the MongoDB server requires authentication) a MONGODB_USER in addition to the following third-party credential: {key: mongodb://<MONGODB_USER>@<MONGODB_HOST>:<MONGODB_PORT>, value: MONGODB_PASSWORD}. Please refer to the User documentation to learn how to add third-party credentials.
In the import mode, the output containing the imported data takes one or many of the following forms:
-
in a JSON format to saved to:
-
the
MONGODB_OUTPUTfile in the data space if specified by the user -
and to the
resultvariable to make is previewable in the scheduler portal and to make it accessible for the next tasks.
-
15.3.2. Cassandra
Variables:
Variable name |
Description |
Scope |
Required? |
Type |
Default/Examples |
|
Label or the IP address of the server hosting the database. |
Workflow, Import Task, Export Task |
Yes |
String |
|
|
Listening port. |
Workflow, Import Task, Export Task |
No |
Integer |
|
|
Keyspace to use. |
Workflow, Import Task, Export Task |
Yes |
String |
e.g. |
|
Query to fetch data. |
Import Task |
Yes |
String |
|
|
Relative path in the data space used to save the results in a CSV file. |
Import Task |
No |
String |
e.g. |
|
If the imported data is labeled for machine learning, a label attribute can be specified using this variable. |
Import Task |
No |
String |
e.g. |
|
Data is stored in tables containing rows of columns, similar to SQL definitions.. It is created if it does not exist. |
Export Task |
Yes |
String |
e.g. |
|
A primary key identifies the location and order of stored data. The primary key is defined when the table is created and cannot be altered. |
Export Task |
Yes |
String |
e.g. |
|
Path of the CSV file that contains data to be imported. This variable can: - A URL. Valid URL schemes include http, ftp, s3, and file. - A relative path in the data space of a CSV file. |
Export Task |
Yes |
String |
e.g. |
How to use this task:
The task might require (if applicable) the following third-party credentials: CASSANDRA_USERNAME and CASSANDRA_PASSWORD. Please refer to the User documentation to learn how to add third-party credentials.
In the import mode, the output containing the imported data takes one or many of the following forms:
-
a CSV format to saved to:
-
the
CASSANDRA_OUTPUTfile in the data space if specified by the user -
and to the
resultvariable to make is previewable in the scheduler portal and to make it accessible for the next tasks.
-
15.3.3. ElasticSearch
Variables:
Variable name |
Description |
Scope |
Required? |
Type |
Default/Examples |
|
Label or the IP address of the ElasticSearch server. |
Workflow |
Yes |
String |
|
|
Listening port. |
Workflow |
No |
Integer |
|
|
Username to use for connecting to Elasticsearch server if authentication is required. |
Workflow |
No |
String |
|
|
Index to use. In export mode, it is created if it does not exist. |
Import Task, Export Task |
Yes |
String |
e.g. my_index |
|
A query to fetch data. If empty, it will fetch all documents from the index by default. |
Import Task |
No |
String |
|
|
Maximum number of results to return. |
Import Task |
No |
Integer |
|
|
The documents type. |
Import Task |
Yes |
String |
e.g. my_doc_type |
|
A JSON Object/Array to be indexed in ElasticSearch. This variable can: - A String describing the JSON Object/Array - A relative path in the data space of a JSON file. |
Export Task |
Yes |
String |
e.g.
or |
How to use this task:
The task might require (if the Elasticsearch server requires authentication) an ELASTICSEARCH_USER in addition to the following third-party credential: {key: elasticsearch://<ELASTICSEARCH_USER>@<ELASTICSEARCH_HOST>:<ELASTICSEARCH_PORT>, value: ELASTICSEARCH_PASSWORD>. Please refer to the User documentation to learn how to add third-party credentials.
In the import mode, the output containing the imported data takes the form of a JSON format to saved to the result variable to make is previewable in the scheduler portal and to make it accessible for the next tasks.
15.4. Cloud
Cloud data connectors allow to interact with cloud storage services. Currently we provide support for Amazon S3, Azure Blob Storage, Azure Data Lake and Snowflake.
15.4.1. Amazon S3
The Amazon S3 connector allows to upload and download data from S3. The connector workflow consists of two tasks:
-
Import_from_S3: Downloads files or folders recursively from S3 to the global space.
-
Export_to_S3: Uploads files or folders recursively from the global space to S3.
Variables:
Variable name |
Description |
Scope |
Required? |
Type |
Default/Examples |
|
S3 access key. |
Workflow, Export and Import Tasks |
Yes |
String |
e.g. 12DSS21EFGFR |
|
Specifies an S3 resource URL where the bucket name identifies the storage container and the key specifies a specific folder or file to download. In case the key is not specified, the entire bucket will be downloaded. |
Import Task |
Yes |
String |
|
|
S3 Bucket name. If it does not exist, a new bucket is created (if possible) and assigned the specified region |
Export Task |
Yes |
String |
e.g. activeeon-public |
|
A valid AWS region code that corresponds to the region of the indicated bucket. |
Export Task |
Yes |
String |
e.g. |
|
Relative path to a folder in the data space to which the downloaded file(s) will be saved in import mode. In export mode, it should point to an existing file/folder that needs to be uploaded. |
Import Task, Export Task |
Yes |
String |
e.g. or or |
|
Prefix (relative path) used to store the uploaded data in the given bucket under the given path. If empty, the data will be uploaded to the bucket root folder. |
Export Task |
No |
String |
e.g. or |
How to use these tasks:
Amazon S3 connector tasks require your AWS credential keys to be set as a third-party credential (key:value pairs) where {key: ACCESS_KEY, value: SECRET_KEY}; this is a one-time action and will ensure that your credentials are securely encrypted. Please refer to the User documentation to learn how to add third-party credentials.
15.4.2. Azure Data Lake
The Azure Data Lake connector allows to upload U-SQL scripts and then execute them as Data Lake Analytics (DLA) jobs. It requires an existing Data Lake Analytics account with its corresponding Data Lake Store account. The connector workflow consists of three tasks:
-
Submit_job: Connects to Azure Data Lake and submits the provided script.
-
Wait_for_job: Periodically monitors the DLA job status until its finalization.
-
Display_result: Downloads the result file and displays it.
Variables:
Variable name |
Description |
Scope |
Required? |
Type |
Default/Examples |
|
Data Lake Analytics account to be used. It should already exist. |
Workflow |
Yes |
String |
e.g. my_dla_account |
|
Name to identify the job to be submitted. |
Workflow |
Yes |
String |
e.g. my_dla_job |
|
File name of the U-SQL script to submit. The file must be located in the Global Space directory. An example file |
Workflow |
Yes |
String |
Sample file: script.usql e.g. my_usql_script.usql |
|
Name of the output file to store the result of the script. |
Workflow |
Yes |
String |
e.g. my_output_file.csv |
|
Cron expression to determine how frequently to monitor the completion of the job. |
Workflow |
Yes |
String |
Default: "* * * * *" (every minute) e.g. "*/2 * * * *" (every 2 minutes) |
|
Optional variable to set an Azure subscription when not using the default one. Value can be a subscription’s name or id. |
Workflow |
No |
String |
e.g. Pay-As-You-Go |
How to use these tasks:
Azure Data Lake tasks require your Azure login credentials to be set as third-party credentials (key:value pairs); this is a one-time action and will ensure that your credentials are securely encrypted. Please refer to the User documentation to learn how to add third-party credentials.
You have two options for providing your login credentials:
-
Standard Azure login:
AZ_U:your_user(usually an email).AZ_P:your_password. -
Using an Azure service principal:
AZ_U:appId.AZ_P:password.AZ_T:tenant. By default, ifAZ_Tis set, the tasks will attempt to connect through a service principal.
|
The Output File
|
15.4.3. Azure Blob Storage
The Azure Blob Storage connector allows to upload and download unstructured data (documents, videos, photos, audio files, presentations, web pages …) from Azure Blob Storage. The connector workflow consists of two tasks:
-
Import_from_Azure_Blob: Downloads blob(s) from Azure Blob Storage to the data space. Note that a virtual folder structure is possible in Azure Blob Storage. In that case, blobs are locally downloaded respecting this structure.
-
Export_to_Azure_Blob: Uploads file(s) or directories recursively from the data space to Azure Blob Storage.
Variables:
Variable name |
Description |
Scope |
Required? |
Type |
Default/Examples |
|
storage account name. |
Workflow, Export and Import Tasks |
Yes |
String |
e.g. storageaccountexample |
|
Relative path to a directory in the data space to which the downloaded blob(s) will be saved. INPUT_PATH can contain either a path to a file, a directory terminated by / or an empty value for the root. |
Import Task |
No |
String |
e.g. or |
|
In import mode, it should refer to an existing blob. If it’s empty, the entire container is downloaded. In export mode, this value corresponds either to the name of the blob to be uploaded or to the folder structure in which blob(s) will be uploaded. |
Import Task, Export Task |
No |
String |
e.g. or or |
|
Azure storage container name. For the export mode, if it does not exist, a new container will be created (if possible). |
Import Task, Export Task |
Yes |
String |
e.g. |
How to use these tasks:
Azure Blob Storage connector tasks require your azure storage account and account key to be set as a third-party credential (key:value pairs) where {key: STORAGE_ACCOUNT, value: ACCOUNT_KEY}; this is a one-time action and will ensure that your credentials are securely encrypted. Please refer to the User documentation to learn how to add third-party credentials.
15.4.4. Snowflake
The Snowflake data connector allows to import and export structured as well as semi-structured data (JSON, Avro, XML) from and to a Snowflake cloud Data Warehouse. The Snowflake connector workflow is composed of two tasks:
Import_from_Snowflake: Import data from a Snowflake cloud Data Warehouse to be processed in the same workflow or just to be stored as a csv file in the data space.
Export_to_Snowflake: Export data from the data space (global or user space) to a Snowflake cloud Data Warehouse.
Variables:
Variable name |
Description |
Scope |
Required? |
Type |
Default/Examples |
|
Username to use for connecting to the data warehouse. |
Workflow, both Tasks |
Yes |
String |
e.g. MY_USERNAME |
|
Name of your account (provided by Snowflake). |
Workflow, both Tasks |
Yes |
String |
e.g. xy12345.east-us-2.azure |
|
Warehouse name. |
Workflow, both Tasks |
Yes |
Strings |
e.g. |
|
Database name. |
Workflow, both Tasks |
Yes |
String |
e.g. |
|
Name of the default schema to use for the database. After login, you can use USE SCHEMA to change the schema. |
Workflow, both Tasks |
Yes |
String |
e.g. |
|
Name of the default role to use. After login, you can use USE ROLE to change the role. |
Workflow, both Tasks |
Yes |
String |
e.g. SYSYADMIN |
|
Protocol used for the connection. |
Workflow, both Tasks |
Yes |
String |
Default: |
|
Requires an SQL query or a table name to fetch data from. |
Import Task |
Yes |
String |
e.g. |
|
Relative path in the data space used to save the results in a CSV file. |
Import Task |
No |
String |
e.g. |
|
Task result output type ( |
Import Task |
No |
String |
Values: Default: |
|
The table to insert data into. |
Export Task |
Yes |
String |
e.g. MY_TABLE |
|
It can be a relative path in the dataspace of a csv file containing the data to import. |
Export Task |
Yes |
String |
e.g. |
How to use these tasks:
When you drag & drop a Snowflake connector, two tasks will be appended to your workflow: an import task and an export task. Each task can be used as a separate component in an ETL pipeline; thus, you can keep one of them depending on your needs and remove the other or you can use them both.
Each task requires the following third-party credential:
{key: <snowflake>://<<USER>@<<ACCOUNT>:<<WAREHOUSE>, value: SNOWFLAKE_PASSWORD}.
15.5. ERP
ProActive’s ERP connectors enable communication and data exchange with popular ERP software providers.
15.5.1. SAP ECC
This connector allows you to interact with an SAP ECC system (not S/4HANA) by means of Remote Function Calls (RFC).
Variables:
Variable name |
Description |
Scope |
Required? |
Type |
Default/Examples |
|
The name of a remote-enabled function module on your SAP System. You can verify the available functions in your ECC transaction SE37. |
Workflow |
Yes |
String |
e.g. RFC_SYSTEM_INFO |
How to use this connector:
In order to securely connect to your SAP ECC system, you first need to store your SAP logon information as ProActive’s third-party credentials. The required credentials are:
Credential |
Description |
Example |
|
Application server host IP. |
10.10.10.1 |
|
System number. |
00 |
|
Client number. |
100 |
|
SAP logon user name. |
myuser |
|
SAP logon password (it will be hidden). |
mypassword |
|
Preferred language. |
EN |
|
(Optional) An SAP Router string, in case you are connecting from an external network. It is important that you keep the /H/ tags. |
/H/192.168.0.1/H/ |
Once the credentials are set, the workflow can be executed. If the connection is successful, the connection attributes will be listed as output. NB. ProActive’s SAP connector provides libraries to connect to an SAP server from a 64-bit OS (Windows, Linux, MacOS); libraries for other OS can be obtained through SAP Marketplace.
The SAP connector will search for the function module provided as the JCO_FUNCTION variable. If the function module exists and is remote-enabled, the script will display the function’s parameters (import, export, tables) right after the Connection attributes.
The SAP connector includes an example of how to execute and handle the result of a function using the default RFC_SYSTEM_INFO, which returns a structure containing the System’s information. After the function is executed, the result can be accessed through the method getExportParameterList().
// execute RFC_SYSTEM_INFO function
sapFunction.execute(destination)
// obtain structure RFCSI_EXPORT
JCoStructure structure = sapFunction.getExportParameterList().getStructure("RFCSI_EXPORT")
if (structure != null) {
println("System info:")
// loop on structure to get the info
for(JCoField field : structure) {
println(field.getName() + " : " + field.getString())
}
}For a more detailed guide of ProActive’s SAP ECC connector, please refer to this document.
Further information and examples using the SAP JCO library are available in the SAP Cloud Platform SDK Documentation and the SAP Java Connector documentation, accessible through SAP Support Website.
15.6. Business Intelligence
Proactive’s BI connectors enable the exportation of data to robust analytics and business intelligence servers.
15.6.1. Export_Data_to_Tableau_Server
This connector allows you to publish data to a Tableau Server.
Variables:
Variable name |
Description |
Scope |
Required? |
Type |
Default/Examples |
|
True if you want to enable docker fork environment. |
Workflow |
Yes |
Boolean |
e.g. True |
|
The name of the docker image that you want to use. |
Task |
Yes if DOCKER_ENABLED is set as True |
String |
e.g. activeeon/dlm3 |
|
True if you want to enable the execution of the task. |
Task |
Yes |
Boolean |
e.g. True |
|
The endpoint of the Tableau server. |
Task |
Yes |
String |
|
|
The site id defined in the Tableau server. |
Task |
Yes |
String |
e.g test_connector |
|
The name of the project where you will save your data in the Tableau server. |
Task |
Yes |
String |
e.g. test |
|
The name of the file that will be created and saved in the Tableau server. |
Task |
Yes |
String |
e.g. test.hyper |
How to use this connector:
In order to securely connect to your Tableau Server, you first need to store your Tableau login information as ProActive’s third-party credentials. The required credentials are:
TABLEAU_SERVER_USERNAME and TABLEAU_SERVER_PASSWORD.
15.7. LDAP Query
The LDAP Query connector enables connection to an existing Microsoft Active Directory server to perform search operations and to check users' credentials and their groups access.
Variables:
| Variable Name | Description | Example |
|---|---|---|
ldapURL |
URL the LDAP server |
|
ldapDnBase |
The base distinguished name of the catalog |
|
ldapUsername |
The username |
|
ldapSearchBase |
base domain name for ldap queries |
|
ldapSearchFilter |
LDAP search filter |
|
ldapSelectedAttributes |
list of attributes to retrieve |
|
If any of these variables must stay private you’ll need to set them as third-party credentials (details are given below).
15.7.1. Authenticate with Third-party credentials
In order to be able to authenticate to the LDAP server you need to define for the right Scheduler user the ldapPassword in the Third-party credentials.
15.7.2. Result of task
The task provides a specific variable for the result, which is called result.
The task result is a String in JSON format.
Output example
Successful task:
{"status":"Ok","attributes":[{"loginShell":"/bin/csh","uid":"yaro","userPassword":"[B@2d6a9952","homeDirectory":"/home/users/yaro","uidNumber":"1000","givenName":"yaro","objectClass":"inetOrgPerson","sn":"yaya","gidNumber":"500","cn":"yaro"}]}Failed task:
{"status":"Error","errorMessage":"javax.naming.NameNotFoundException: [LDAP: error code 32 - No Such Object]; remaining name 'cn=yaro,dc=activeeon,dc=com1'"}15.7.3. Secure connection to LDAP server
In order to use secure connection for the LDAP server, specify a correct LDAP over SSL URL (for example ldaps://localhost:636).
In order to be able to connect to a LDAP server, a valid certificate is needed.
When a self-signed certificate is used, the certificate needs to be added to the trusted certificates of the JRE provided with the Scheduler.
Below is an example for adding a certificate to a Java cacerts file:
keytool -import -alias ldap-self-signed -keystore </pathToScheduler/jre/lib/security/cacerts> -file ldaps.crt -storepass changeit
16. Application Connectors
The application-connectors bucket contains diverse generic application connectors for the most frequently used cloud data management systems (ERP, ETL, LDAP, Reporting and Monitoring, and ServiceNow).The aim of an application connector is to facilitate and simplify the integration of a cloud application in your workflows.
16.1. ETL
The ETL connectors allow connecting to data servers and benefit from their features. The following presents the various ETL connectors that PWS handle.
16.1.1. Informatica
The Informatica workflow consists of one task.
Variables:
The Informatica workflow consists of a list of variables described in the following table.
Variable name |
Description |
Scope |
Required? |
Type |
Default/Examples |
|
Server host. |
Workflow |
Yes |
String |
e.g. |
|
Username to use for the authentication. |
Workflow |
No |
String |
e.g. toto |
|
Password to use for the authentication. |
Workflow |
No |
String |
e.g. toto |
|
Format of the server response . |
Task |
Yes |
string, json, xml, html, contentView |
json |
|
… |
Task |
Yes |
String |
. |
|
Name of the api parameter (in case of multiple parameters, add several parameters fields). |
Task |
No |
String |
e.g. PARAM_input |
|
Name of the api request header (in case of multiple parameters, add several headers fields). |
Task |
No |
String |
e.g. HEADER_sessionId |
|
JWT Token to use for the authentication. |
Workflow |
No |
String |
e.g. eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9 |
|
Allows printing more logs in the workflow results. |
Task |
Yes |
Boolean |
False |
How to use this task:
This WorkFlow performs a GET request to an Informatica API associated to an application already created by the Informatica user. This workflow template supports the following authentication methods: a basic authentication using a username and a password, an advanced authentication using a JWT access token and finally an anonymous authentication where no authorization is required. The authentication method is determined based on the definition of the parameters when launching the WF.
16.2. ServiceNow
Product Name: ServiceNow
Product Version: Quebec
Compatibility: Tokyo
The ServiceNow connectors allow ProActive to communicate with ServiceNow instances to perform CRUD operations on their data as well as to send emails.
The installation of the ProActive application in ServiceNow, which enables a ServiceNow instance to communication with a ProActive server, is described in the ServiceNow admin documentation.
16.2.1. ProActive to ServiceNow
A set of ProActive workflow templates are available in the catalog to communicate with ServiceNow. They are usually integrated as a task or a subworkflow in an end-to-end workflow and perform HTTP queries to ServiceNow’s TABLE or EMAIL API depending on their action.
Go to ServiceNow’s REST API reference for the complete API’s documentation.
Send Emails
This workflow enables to send emails through ServiceNow using the EMAIL API.
It is made of a single task with its variables.
Task Variables:
Variable name |
Description |
Required? |
Type |
Default/Examples |
|
ServiceNow server endpoint. |
Yes |
URL |
|
|
ServiceNow user. |
Yes |
String |
e.g. administrator |
|
ServiceNow password. |
Yes |
Sring (HIDDEN) |
e.g. PWD |
|
Recipients of the email. |
Yes |
String as a comma separated list |
e.g. |
|
Email addresses that will be in copy. |
No |
String as a comma separated list |
e.g. |
|
The subject of the email. |
No |
String |
e.g. |
|
Content of the email, can contain HTML tags |
Yes |
String with HTML |
e.g. |
|
Name of the table to save the email. Use this parameter to associate an email message to a particular related record elsewhere in the system. |
No |
String with HTML |
e.g. incident |
|
Target-related record to which the email applies. Use this parameter to associate an email message to a particular related record elsewhere in the system. |
No |
String |
e.g. 9d385017c611228701d22104cc95c371 |
|
If true, disables SSL certificate verification |
No |
Boolean |
e.g. true |
|
Content-type of the request, should be 'application/json' with eventual encoding. |
Yes |
String |
e.g. |
|
The body of the HTTP request which is automatically built. |
Yes |
String |
e.g. |
|
If true, activates the debug mode which prints messages to the terminal. |
No |
Boolean |
e.g. |
Table API
The TABLE API allows to query data from a ServiceNow instance.
There are six workflows in ProActive’s Catalog that queries ServiceNow’s TABLE API. Two enables to create a ServiceNow task and mark it as resolved and four other to perform basic CRUD operations on ServiceNow’s tables.
The two Task related workflows have both one task with the following variables:
Variable name |
Description |
Required? |
Type |
Default/Examples |
|
ServiceNow server endpoint. |
Yes |
URL |
|
|
ServiceNow user. |
Yes |
String |
e.g. administrator |
|
ServiceNow password. |
Yes |
Sring (HIDDEN) |
e.g. PWD |
|
The subtype of the ServiceNow Task |
Yes |
PA:LIST(incident,ticket,problem,change_request) |
e.g. |
|
The path of the query |
Yes |
String |
e.g. |
|
ServiceNow data to be returned in the HTTP response |
No |
String as a comma separated list |
e.g. |
|
If true, disables SSL certificate verification |
No |
Boolean |
e.g. true |
|
Content-type of the request, should be 'application/json' with eventual encoding. |
Yes |
String |
e.g. |
|
The body of the HTTP request which is automatically built. |
Yes |
String |
e.g. |
|
If true, activates the debug mode which prints messages to the terminal. |
No |
Boolean |
e.g. |
|
The path of the data to extract in the response if json, xml or html format is selected |
Yes |
String |
e.g. |
Mark a ServiceNow Task as resolved requires in addition to the variables described in the Create Task workflow:
Variable name |
Description |
Required? |
Type |
Default/Examples |
|
A note binded to the task resolution |
Yes |
String |
|
|
The state of the ServiceNow Task after resolution. Can be 6 = Resolved, or 7 = Closed |
Yes |
Integer |
e.g. |
|
The user who resolved the Task |
Yes |
Sring |
e.g. |
|
The system id of the Task to be resolved |
Yes |
String |
e.g. |
The other four generic workflows to perform CRUD have the following structure.
Workflow variables:
Variable name |
Description |
Required? |
Type |
Default/Examples |
|
Base URL of the ServiceNow instance |
Yes |
String |
|
|
ServiceNow user |
Yes |
String |
e.g. |
Task variables:
Variable name |
Description |
Required? |
Type |
Default/Examples |
|
Queried endpoint of the TABLE API |
Yes |
String |
|
|
Name of queried ServiceNow table |
Yes |
String |
e.g. |
|
JSON structure describing columns and their values to be inserted |
Yes |
String |
|
|
Name of the queried ServiceNow table |
Yes |
String |
e.g. |
|
Format of the HTTP response |
Yes |
String |
e.g. |
|
Path of the data to extract in the response if json, xml or html format is selected |
Yes |
String |
e.g. |
|
Format of the HTTP request |
Yes |
String |
e.g. |
|
Id of the row to query (needed for read, update, delete) |
Yes |
String |
e.g. |
|
HTTP Method of the query. Used for the update or modify record workflow |
Yes |
String |
e.g. |
|
Returns field display values (true), actual values (false), or both (all). |
Yes |
Boolean |
e.g. |
|
True to exclude Table API links for reference fields. |
Yes |
Boolean |
e.g. |
|
Fields of the table to be included in the response |
Yes |
String as a comma separated list |
e.g. |
|
Set field values using their display value (true) or actual value (false) |
Yes |
Boolean |
e.g. |
|
True to suppress auto generation of system fields |
Yes |
Boolean |
e.g. |
|
True to access data across domains if authorized |
Yes |
Boolean |
e.g. |
|
If true, disables SSL certificate verification |
No |
Boolean |
e.g. true |
|
If true, activates the debug mode which prints messages to the terminal. |
No |
Boolean |
e.g. |
16.2.2. ServiceNow to ProActive
Once the application is installed, you are ready to integrate ProActive in your ServiceNow pipelines.
We will go over the core application files in the application to explain how to use them.
Script Includes
Overview
As defined by ServiceNow, Script Includes are reusable server-side scripts logic that define a function or a class. Script Includes execute their script logic only when explicitly called by other scripts anywhere in the application where scripting is permitted.
It can be in another Script Include, In Workflow Activities, Flow Actions, UI elements …
Usage
Calling a Script Include where scripting is enabled is very easy. You just need to create an instance of the Script Include and execute its functions.
Here is an example where the Script Include named SchedulerClient is called in a Flow’s Action to submit a job:
(function execute(inputs, outputs) {
var schedulerClient = new SchedulerClient();
var response = schedulerClient.submitJobFromCatalog(inputs.proactive_url, inputs.session_id, inputs.bucket_name, inputs.workflow_name, inputs.variables, inputs.generic_info);
outputs.job_id = response.id;
outputs.readable_name = response.readableName;
})(inputs, outputs);ProActive’s application Script Includes
There are 3 script includes in the ProActive application:
SchedulerClient: A client that makes REST calls to a ProActive’s Scheduler. Call this Script Include to make HTTP requests to the Scheduler of a ProActive’s server.
Here is the list of its current functions.
| The REST API documentation for our try platform is available at https://try.activeeon.com/doc/rest/ |
| Function name | Action | Inputs | Output |
|---|---|---|---|
getSessionId |
Executes a POST request to login and retrieve the sessionId of a ProActive user |
|
The session id associated to the user |
restartInErrorTasks |
Executes a PUT request to restart all tasks in error in the job represented by a job id |
|
True if success, false if not |
submitJobFromCatalog |
Submits a job to the scheduler from the catalog, creating a new job resource |
|
The jobid of the newly created job as JSON |
submitJobFromFile |
Submits a workflow stored in the ServiceNow instance to ProActive’s scheduler, creating a new job resource. Provided a workflow name, the script will search for the corresponding workflow stored in ProActive’s application table named "x_661207_proacti_0_workflow" and labeled "Workflow". The workflow’s must be stored as a file that complies with ProActive’s XML schema. |
|
The jobid of the newly created job as JSON |
disconnectUser |
Executes a PUT request to disconnect a user represented by a sessionId from a ProActive server |
|
True if successful else false |
getJobInfo |
Executes a GET request to retrieve a job’s job info |
|
True if successful, else false |
isFaultyJob |
Executes the getJobInfo function and checks the current job status to determine if the job is Faulty. A job is considered faulty when it is finished, canceled or failed and has at least one task that is failed, faulty or in error |
|
True if the job is faulty, else false |
waitForTerminalStatus |
Polling function that blocks the current thread and checks the current job status every 2.5 seconds until it reaches a terminal status. |
|
The polled job info |
_getAllJobStatuses |
Utility function that returns a mapping of all the possible job statuses and if it is a terminal status |
|
| Functions starting with an _ is a ServiceNow naming convention for private functions. This is purely informative as in reality they are callable from anywhere like other functions. |
OutboundRestService: A service class that contains a utility function to execute a ServiceNow’s Outbound Rest Messages. Used by the SchedulerClient, it encapsulates the procedure to build and execute an HTTP query to ProActive’s Scheduler.
Like the SchedulerClient class, its function can be called from anywhere scripting is permitted.
| Function name | Action | Inputs | Output |
|---|---|---|---|
executeOutboundRestMsg |
Prepares and executes a ServiceNow HTTP Method from the ProActive Scheduler REST Message |
|
A RESTResponseV2 object. Go to ServiceNow’s RESTResponseV2 API documentation to get a list of its functions. |
JobRepository: It is the service class which holds functions to perform CRUD operations on the application’s table labeled "Submitted job". A table is a collection of records in the database. Each record corresponds to a row in a table, and each field on a record corresponds to a column on that table. The Submitted Job table can be used to store Job Info data received from ProActive and access it in your pipelines. Like other Script Include, it can be instantiated and called anywhere scripting is permitted.
You will find in the next section the structure of the table, which corresponds to JobInfo data fields returned by the Scheduler.
Here is the list of the current available functions
| Function name | Action | Inputs | Output |
|---|---|---|---|
createSubmittedJob |
Adds a row to the Submitted Job table |
|
The sys id of the created row |
updateSubmittedJob |
updates a row to the Submitted Job table |
|
True if the update has succeeded, else false |
deleteSubmittedJobBySysId |
Deletes a row which has the specified sys id |
|
True if the deletion has succeeded, else false |
deleteSubmittedJobByJobId |
Deletes a row which has the specified job id |
|
True if the deletion has succeeded, else false |
_isJobExists |
Checks if a row exists with the specified job id |
|
True if the row exists, else false |
_executeUpdateQuery |
Utility function to encapsulate the update of a row process |
|
True if the update has succeeded, else false |
Tables
The application has two tables that can be used to store and read data:
-
Submitted Job: Each row contains data of a job submitted to the Scheduler. This is the table used by the JobRepository Script Include to perform CRUD operations.
-
Workflow: Each row contains a ProActive workflow xml definition file. The function submitJobFromFile of the SchedulerService Script Include will search for the specified workflow’s XML definition in this table.
Below you will find the structure of both tables
| Column name | Type | Max length |
|---|---|---|
finished_time |
Long |
40 |
in_error_time |
Long |
40 |
job_id |
Long |
40 |
name |
String |
256 |
output |
String |
4000 |
owner |
String |
40 |
result |
String |
40 |
session_id |
String |
64 |
start_time |
Long |
40 |
status |
String |
16 |
submitted_time |
Long |
40 |
| Column name | Type | Max length |
|---|---|---|
name |
String |
256 |
file |
File Attachment |
40 |
| All tables contain additional fields starting with sys_ . Those fields are automatically generated by ServiceNow when the table is created and can’t be changed. |
Two Table Columns have been added to the Incident table:
-
ProActive Job Id
-
ProActive Session Id
This allows to specify the sessionId of the user, and a job id at an Incident creation, binding it to a ProActive job. Other columns can be added in the Incident table to store logs, outputs or any needed information regarding a job.
Flow Designer
Flow Designer is a feature for automating processes in a single design environment.
Actions and Core Actions are what composes a Flow and Subflow. The application comes with Actions ready to be used. These Actions use the Script Includes that we described earlier.
An Action consists of:
-
Inputs: Variables accessible from all steps of the action
-
Action step(s): Process(es) using the provided inputs
-
Outputs: Variables that represent the results of the action. These results are available to other actions in a flow.
ProActive’s application Actions have been designed so that their inputs correspond to the related function called from the Scheduler Client Script Include to make it as linear as possible.
| Action name |
|---|
Login to ProActive |
Disconnect from ProActive |
Submit job from catalog |
Submit job from file |
Wait for terminal status |
Disconnect from ProActive |
Here is an example with the "Submit From Catalog" action. It applies to other actions as well.
The Action inputs are accessible by all steps of the Action
Inputs of this step are bound to the Action inputs. This is represented by a pill in the "Value" column.
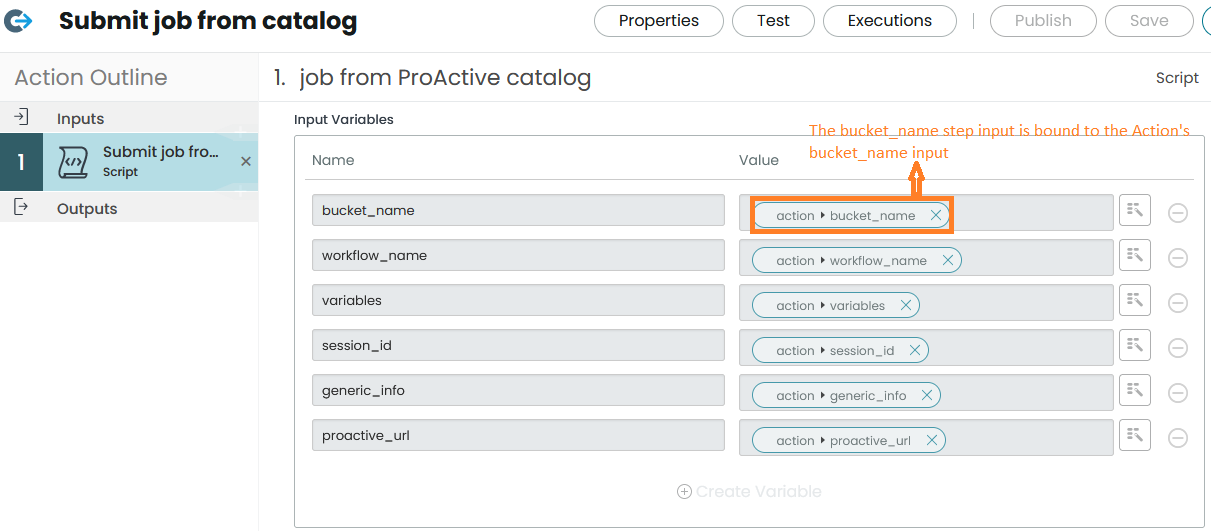
The action is composed of a single script step. A script step is JavaScript code to execute within a reusable action. While most core actions and steps fit common use cases, a Script step enables to execute a behavior that is not satisfied by the core steps.
The code of this script step is displayed here.
As you can see it is very simple and the execution flow consists of:
-
Instantiating the SchedulerClient Script Include
-
Calling the submitFromCatalog function with the inputs as parameters
-
Writing the result in the outputs variable
Finally, we define the outputs of the action with the same pills system, binding them to the step outputs.

The concept is the same for all the application’s Actions.
Flows
To put it simply, a flow is an automated process consisting of a sequence of actions and a trigger. Flow building takes place in the Flow Designer application which requires a paid subscription to the Integration Hub application.
A Flow consists of the content types:
-
Subflows: A Subflow is an automated process consisting of a sequence of reusable actions and specific data inputs that allow the process to be started from a flow, subflow, or script.
-
Actions: An Action is a reusable operation that enables process analysts to automate Now Platform features without having to write code
-
Core Actions: A ServiceNow Core Action is a ServiceNow-provided action available to any flow that cannot be viewed or edited from the Action Designer design environment. For example, the Ask for Approval action
A trigger identifies what causes the flow to execute.
Flows are triggered by:
-
Record creation and/or update
-
Date
-
Service Catalog request
-
Inbound email
-
Service Level Agreements
-
MetricBase (requires the MetricBase plugin)
| To access Flows, a user must have the flow_designer or admin roles. |
The ProActive application come with Flows that can:
-
Submit a job from the catalog asynchronously
-
Restart in error tasks
Below is the "Submit job from catalog async" Flow
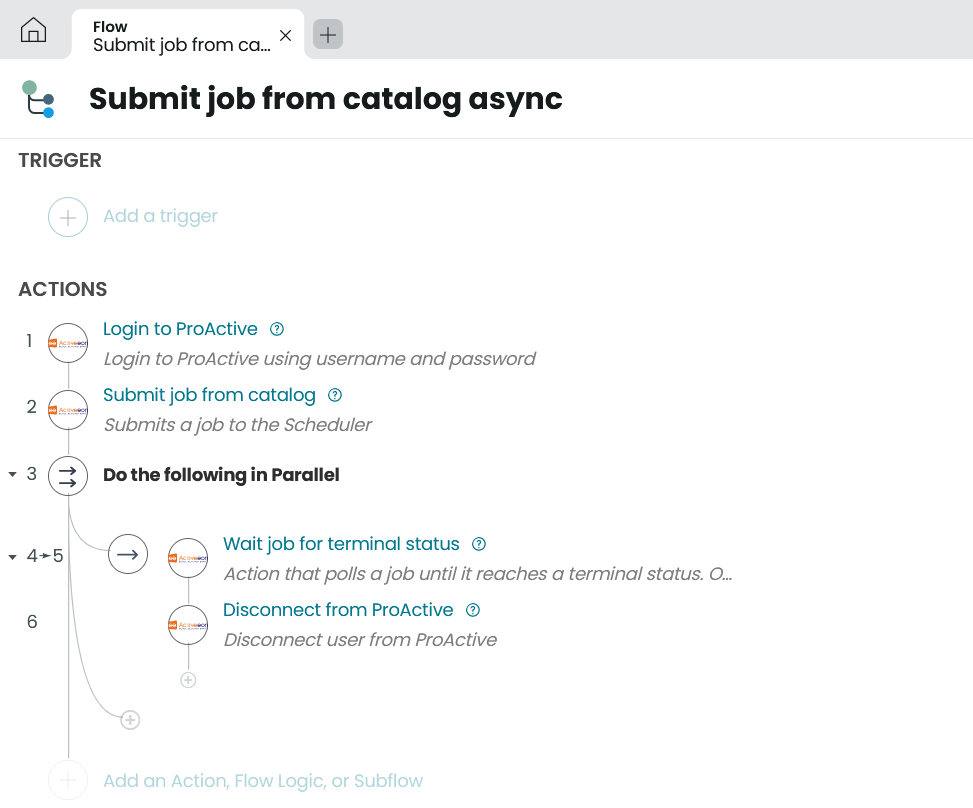
This Flow submits a job to ProActive’s Scheduler in parallel, thus not blocking the main Flow thread.
In the Right panel named Data, you will find the data flow of the Flow. It offers a quick view of the Flow variables, accessible by all actions and the inputs for each Action. Fo convenience, it has been cut in half in this screenshot.
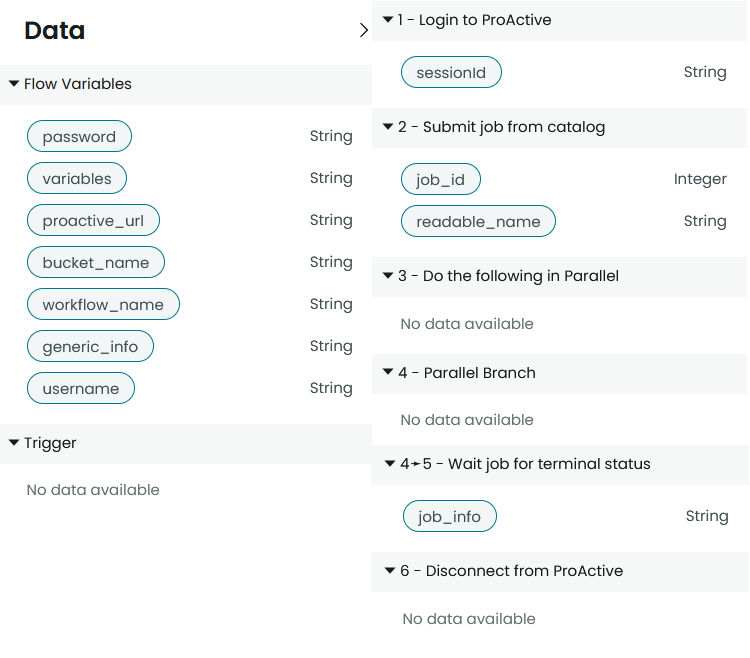
The flow needs a trigger definition, and it will ready to run.
Workflows
The second way to automate complex processes is using Workflows that are built in the Workflow Editor. A Workflow is the native way to do automation in ServiceNow. Workflow editor is intended for a more technical audience.
The goal and concepts of Workflows are the same as Flows only with a different interface and terminology.
Like Actions for Flows, a Workflow is a suite of Activities used for automating the processes. Activities are the workflow blocks that carry out various tasks like sending emails, obtaining approvals, running scripts, and configuring field values on the records.
Every workflow starts with a Begin activity and ends with an End activity. When the activity ends, the activity is available through the suitable node and the transition is comprehended to the latter activity.
Following are the ways to launch Workflows:
-
UI Action
-
Server-side script
-
Triggered by field values on a record
The ProActive application comes with a set of activities ready to be used in your workflows. Like the Actions in the Flows, they call the application’s Script Include to perform their actions.
Each activity likely have inputs that needs to be defined.
Here the Login activity will read variables defined in the workflow’s scratchpad.
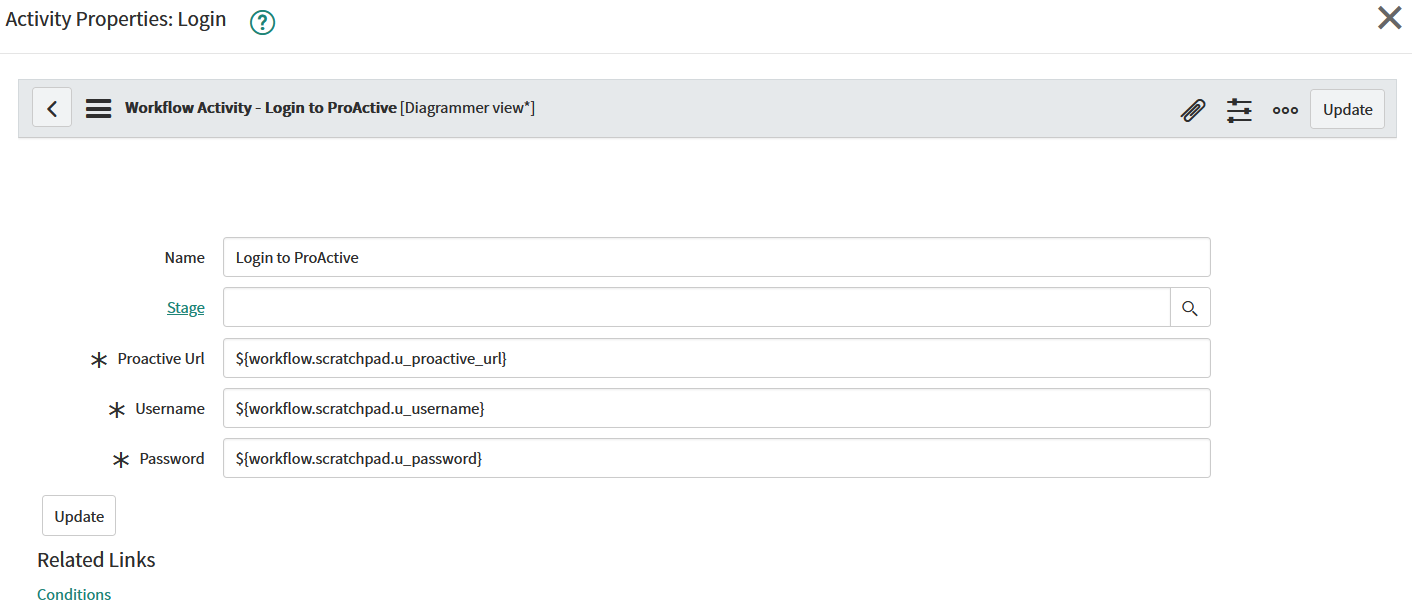
This window automatically opens when the activity is dragged and dropped on the canvas.
Use ProActive’s custom activities from the Custom tab to integrate ProActive in your pipelines.
Here an example of a simple Workflow, that can be stored and used as a Sub Workflow, that Submits a job to ProActive from the Catalog

17. Integration of ProActive Services in Third-party User Portals
In this section, we will discuss how ProActive Services can be integrated into third-party user portals. We will cover the following topics:
-
Submission of a Workflow in a Dedicated Window: How to use an external window for workflow submission outside our software, in your own portal.
-
Monitoring the Execution of a Specific Job in a Dedicated Window: How to view monitoring data and workflow information after submission and in your own portal.
17.1. Submission of a workflow in a dedicated window
We offer an external window that can be triggered outside our software, from inside your own portal, using the following URL format:
http(s)://your-server:port/automation-dashboard/#/submit?sessionid={sessionid}&name={workflowName}&bucket={bucketName}
-
sessionid: The ID of the connection. It allows the user to bypass the login page and directly display the content. It can be provided in the URL. If not provided, in case the user is already logged in our portal, it will not need to log again, if not, the user will need to log in by entering his credentials.
-
name: The name of the workflow.
-
bucket: The name of the bucket.
|
All parameters ( |
There are four scenarios:
-
Submit any workflow: Let the user choose the bucket and workflow they want to submit.
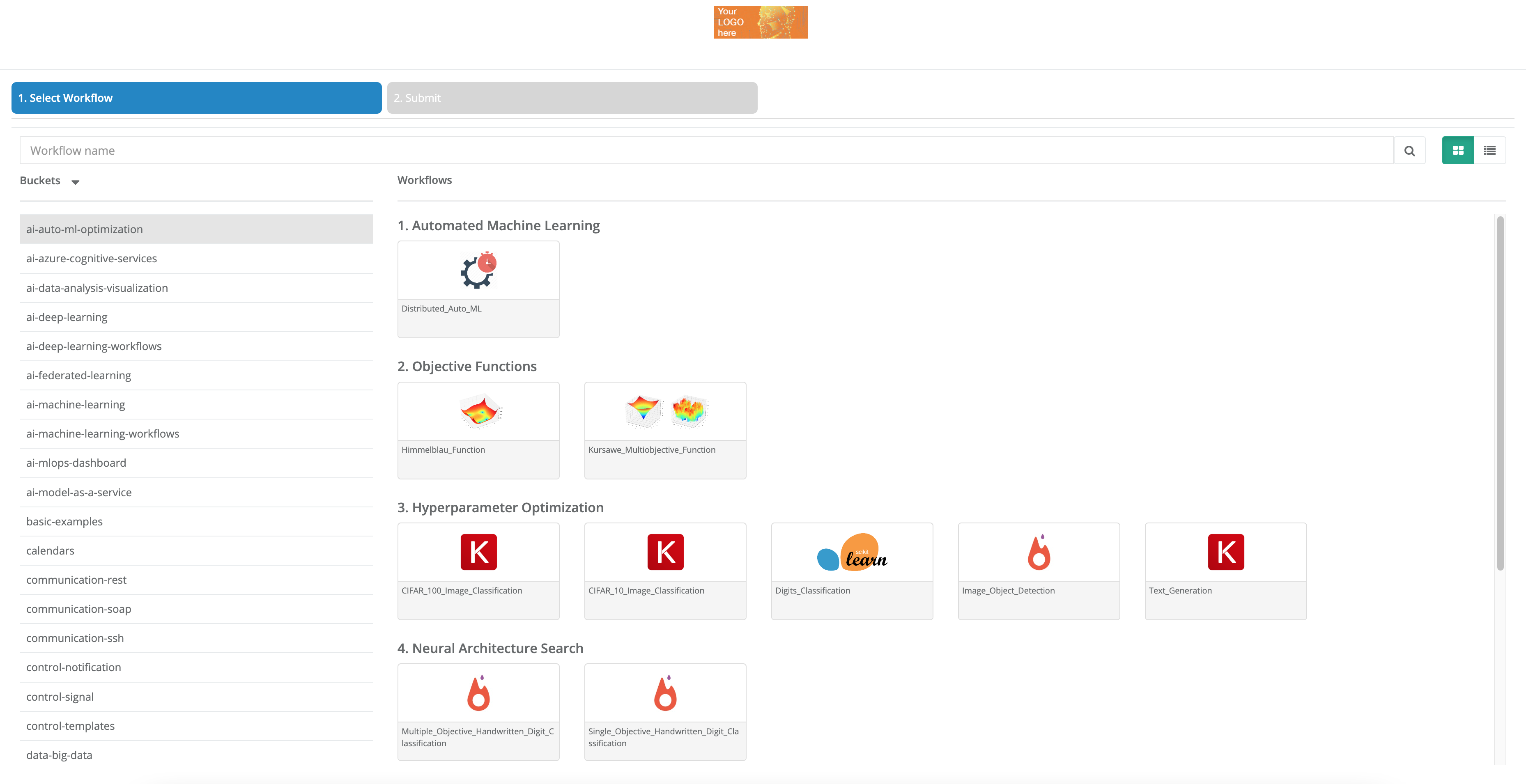
-
Submit any workflow from a specific bucket: Provide the bucket name or a substring of it as a query parameter. You can use filtering with jokers by using the percentage symbol
(%), as explained in the example below.
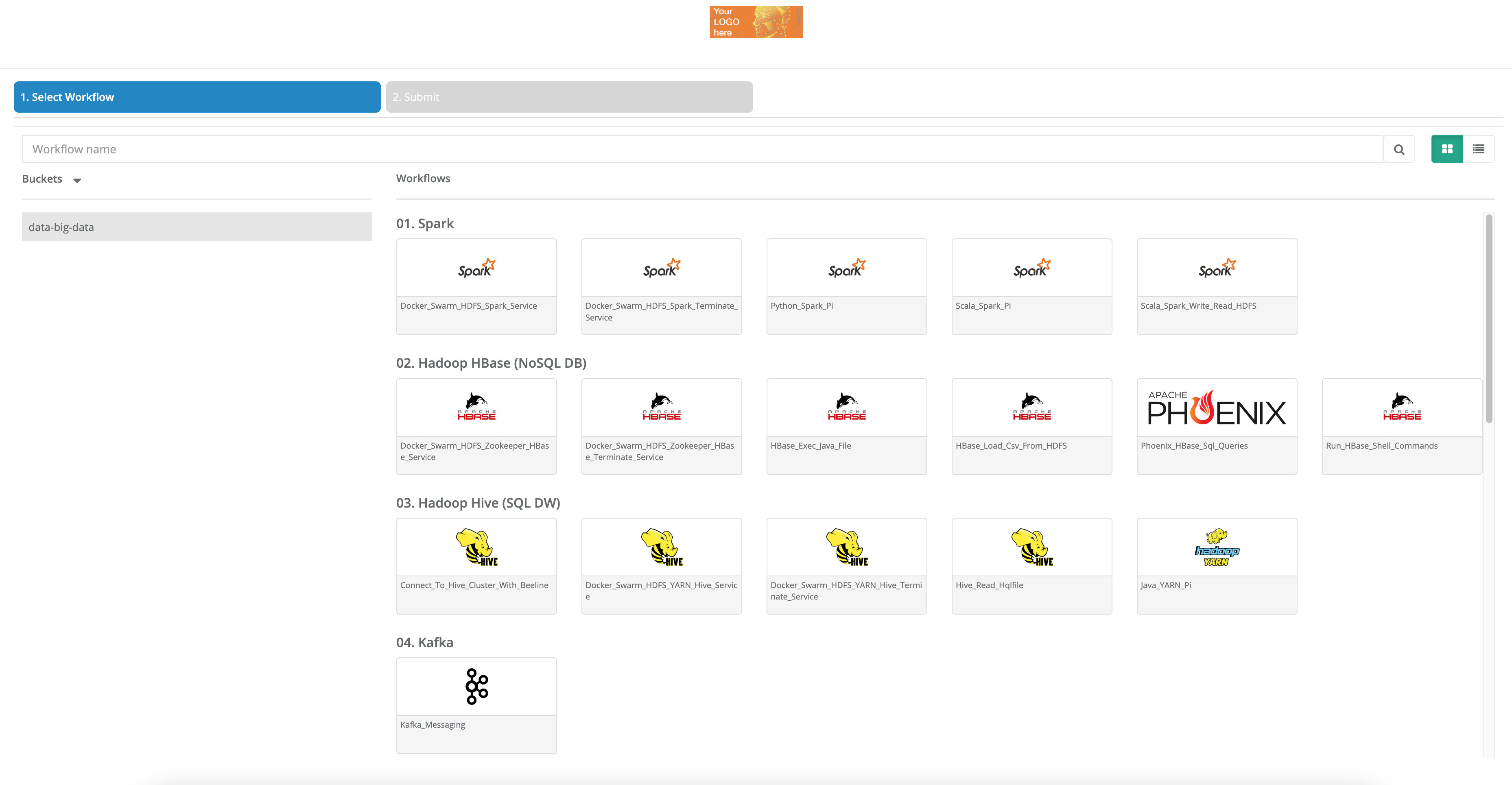
-
Submit specific workflows from a specific buckets: Provide both the bucket name and the workflow name as query parameters, using the percentage symbol (
%), as shown in the example below.
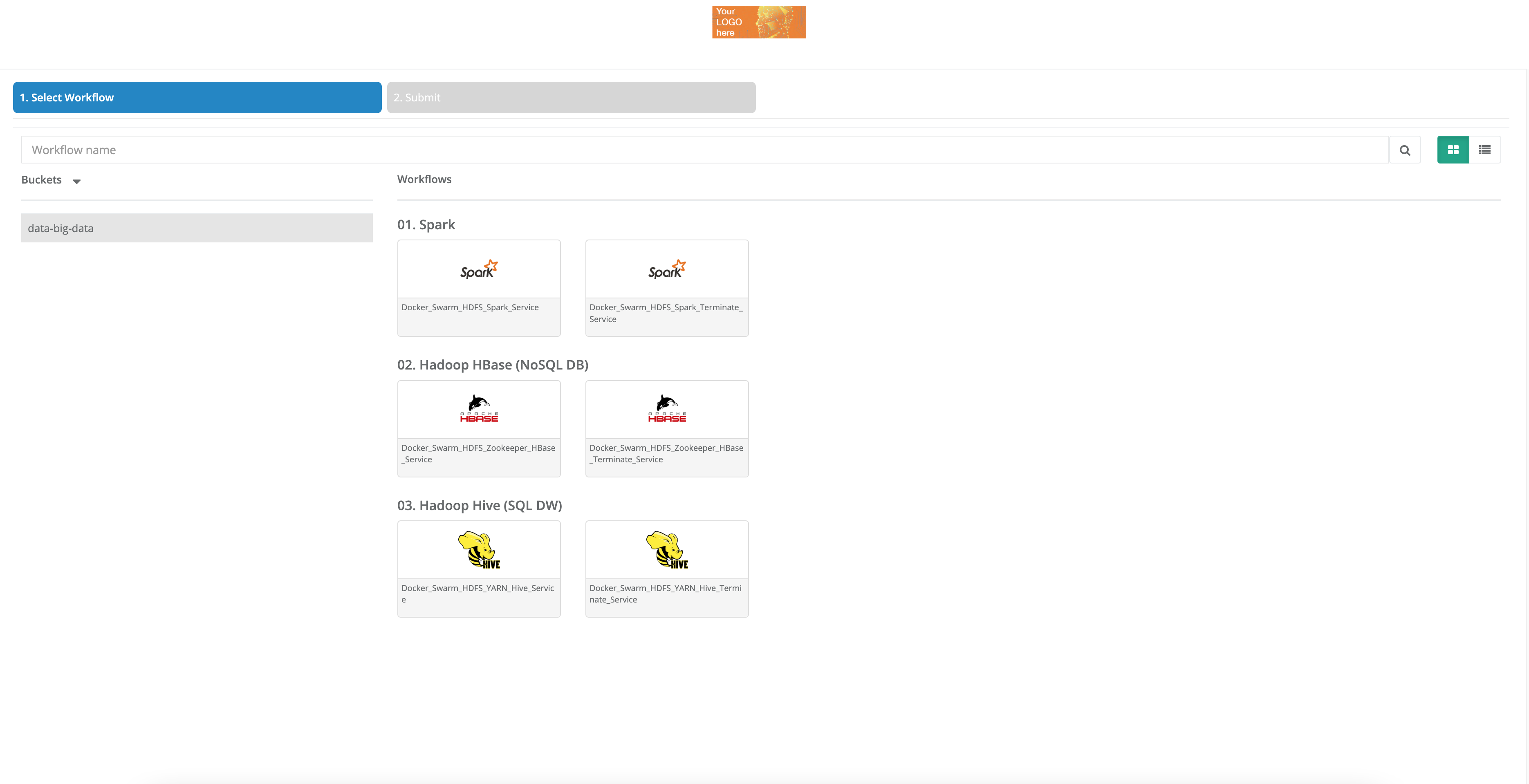
-
Submit a specific workflow: When both the bucket and workflow are determined exactly, do not use the percentage symbol (
%).
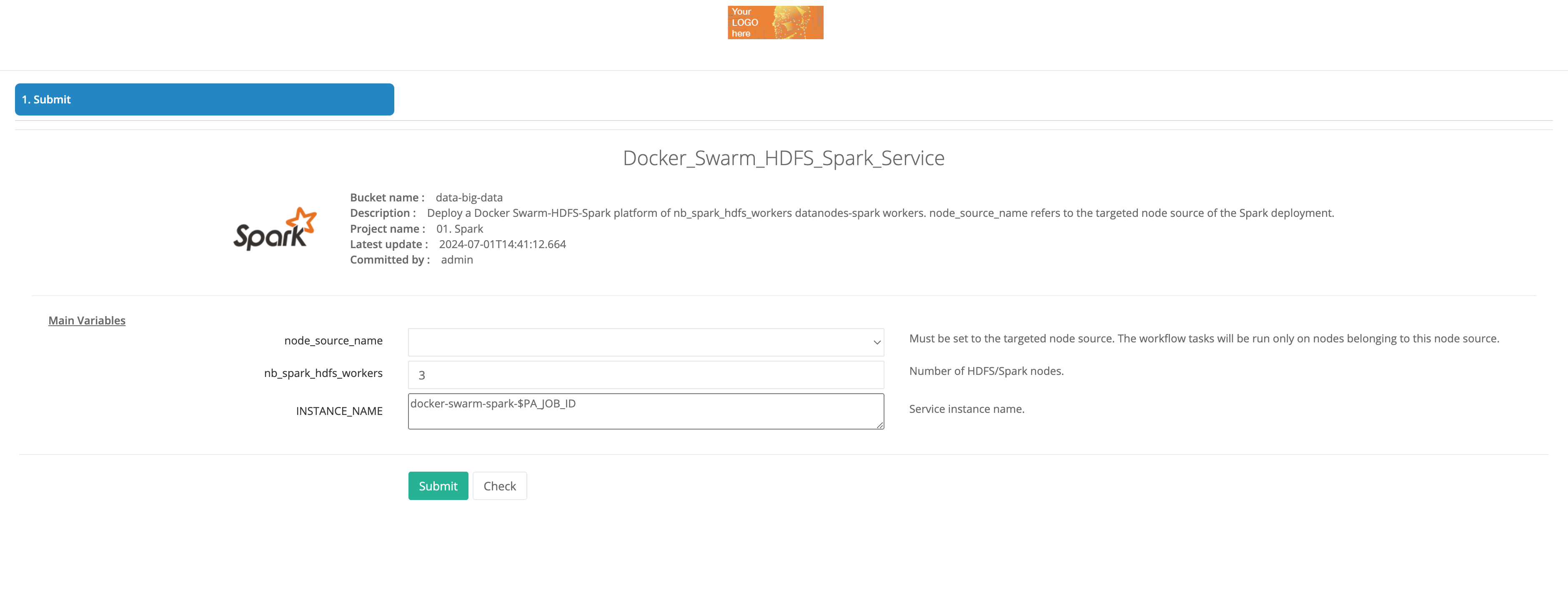
17.1.1. Examples:
Example 1:
http(s)://your-server:port/automation-dashboard/#/submit?
This url display all buckets, let the user choose the bucket and workflow he/she wants to submit.
Example 2:
http(s)://your-server:port/automation-dashboard/#/submit?bucket=%25data%25
This url display only the buckets with names that include the substring "data" within the name, like my-data-bucket, data-analysis and bucket-data-test.
Example 3:
http(s)://your-server:port/automation-dashboard/#/submit?bucket=data%25
This one display only the buckets with names that start with "data", like data-analysis.
Example 4:
http(s)://your-server:port/automation-dashboard/#/submit?bucket=ai-deep-learning
This url display all buckets with names that include the substring ai-deep-learning anywhere in the name, the position here doesn’t matter.
Example 5:
http(s)://your-server:port/automation-dashboard/#/submit?bucket=ai-deep-learning-workflows&name=%25train%25
This url display all buckets with names that include the substring ai-deep-learning, and workflows with names include the substring train.
Example 6:
http(s)://your-server:port/automation-dashboard/#/submit?bucket=ai-deep-learning-workflows&name=train%25
This url display all buckets with names that include the substring ai-deep-learning, and contain workflows with names start by train.
Example 8:
http(s)://your-server:port/automation-dashboard/#/submit?bucket=ai-deep-learning-workflows&name=%25detection
This url display all buckets with names that include the substring ai-deep-learning, and contain workflows with names ending by detection.
17.2. Monitoring the execution of a specific job in a dedicated window
After submitting a workflow (with the method in the section above, or any other means like standard portals, API, etc.), you can view the monitoring data and the resulting Job info (progress, interactive graph, results, log, tasks, etc.) by opening a dedicated window.
When using the method presented in the section above, this can be done by clicking on the 'See Job Details' button.
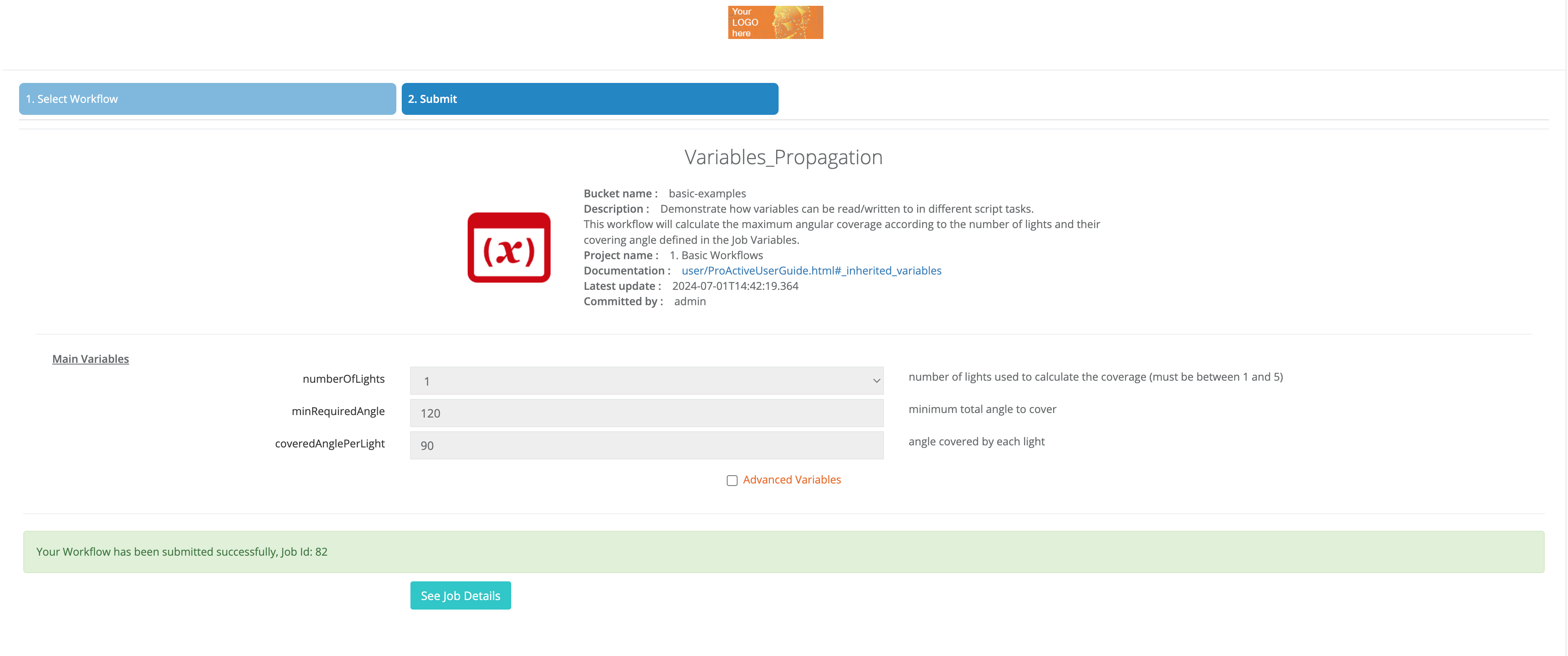
For any Job in the system, you can view the above content by using the following URL in your own portals, replacing {jobid} with the JobID you want to monitor:
http(s)://your-server:port/automation-dashboard/#/job-info?jobid={jobid}
|
Note that you can customize the logo “Your LOGO here“ with your own portal logo, such that the windows smoothly integrate in your own portal. See how to achieve that at section “3.9. Custom logo configuration” of the Admin Guide. Link: here |
Your user will get access to these kinds of window in fully interactive mode:
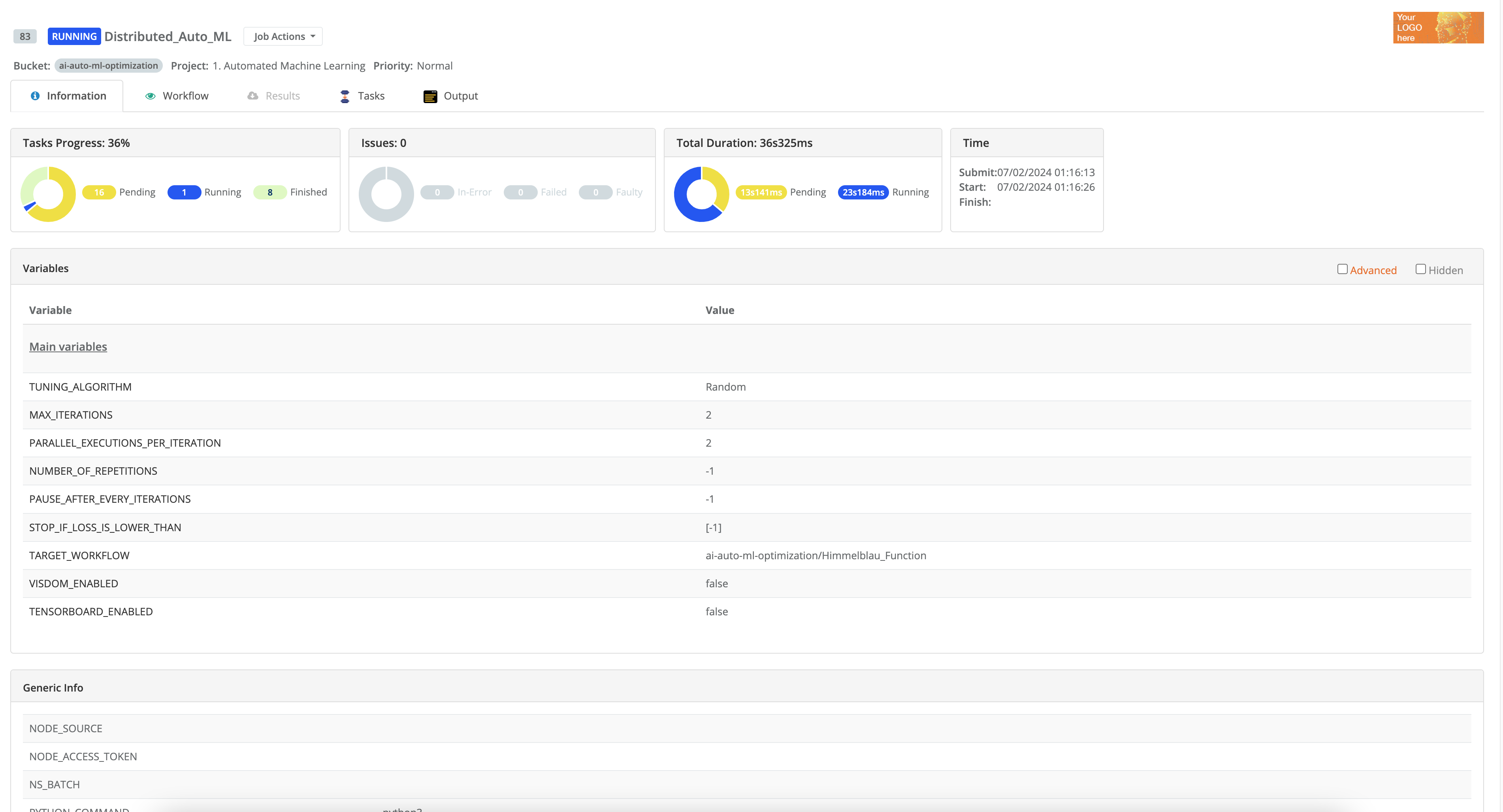
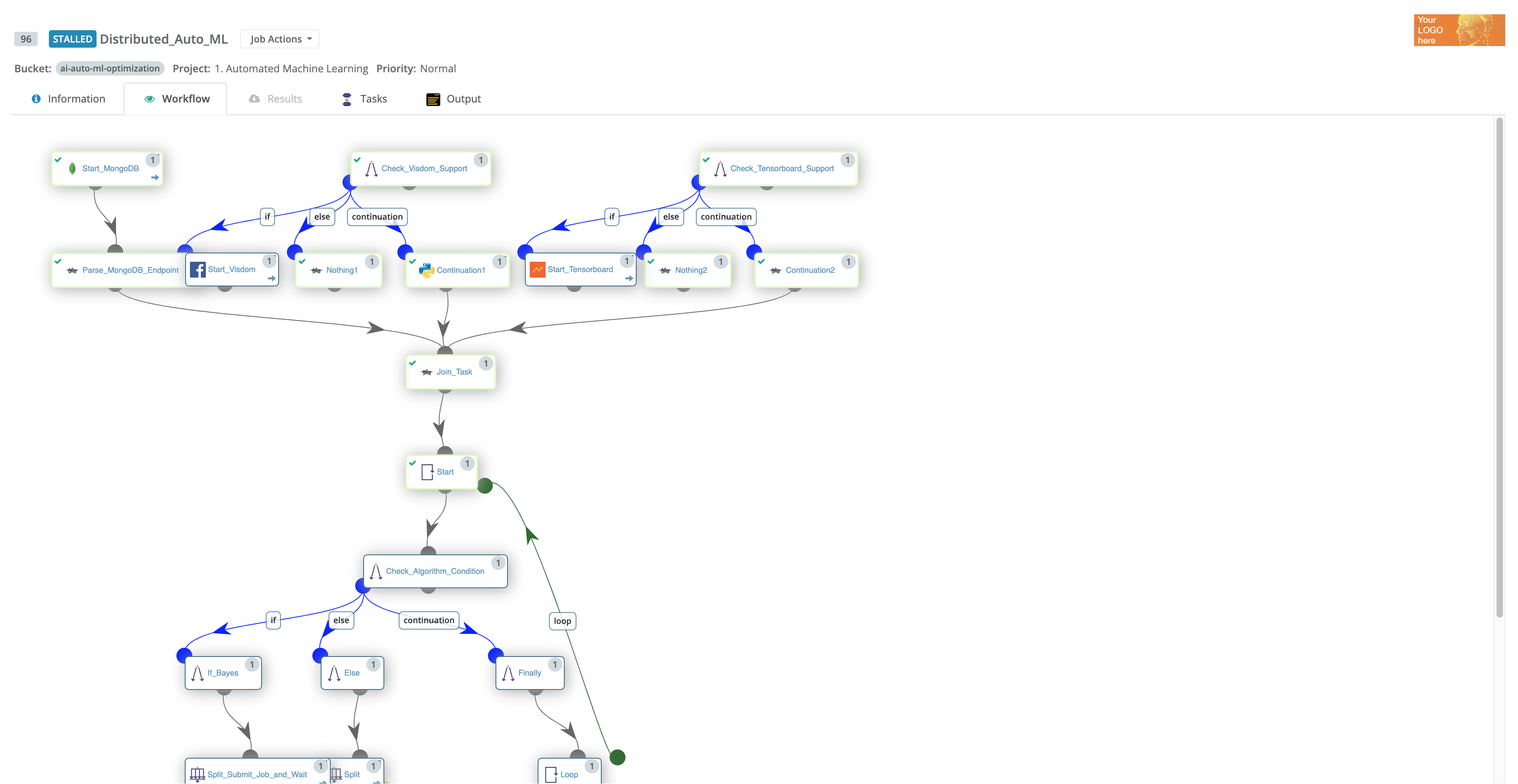
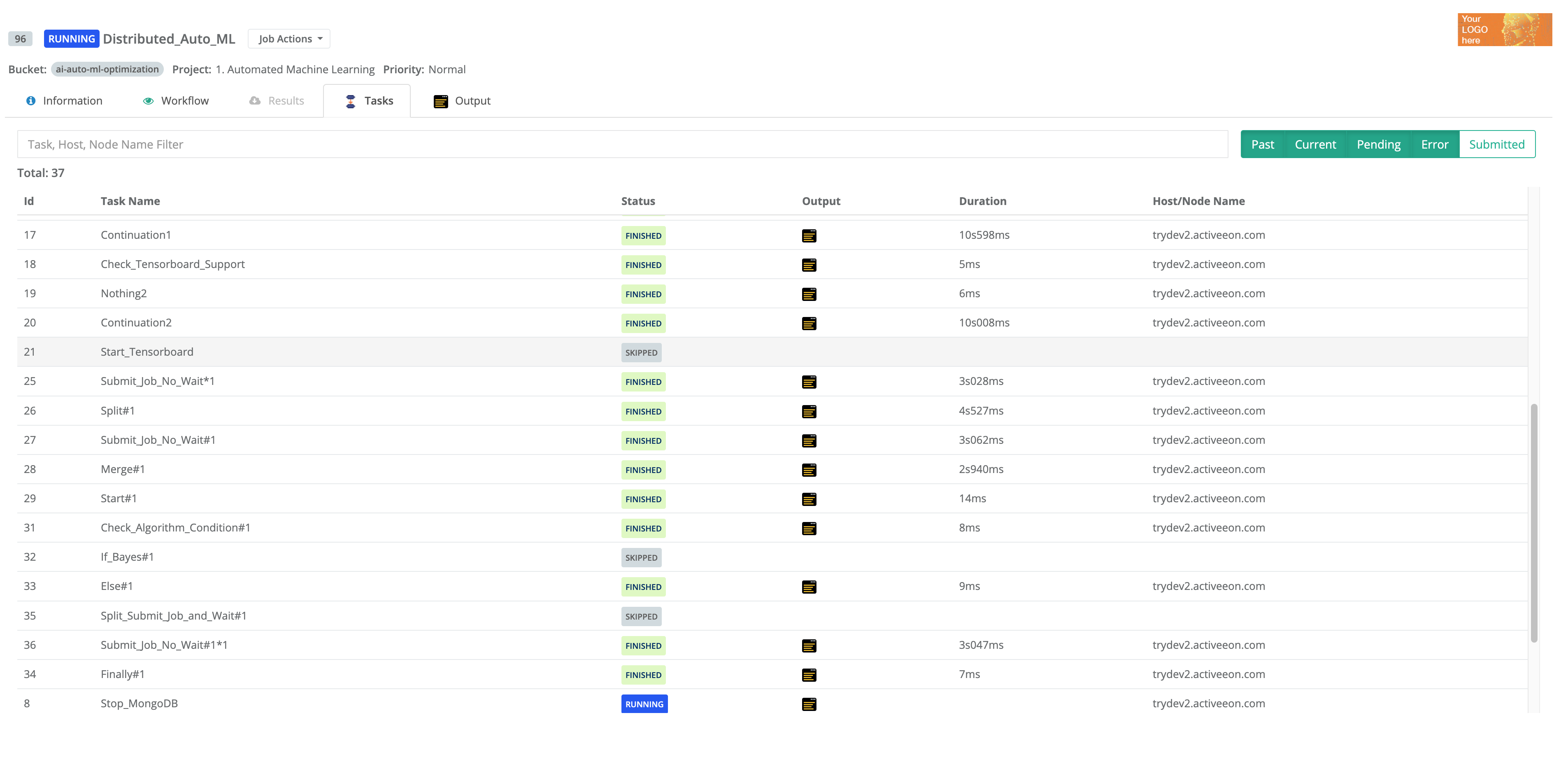
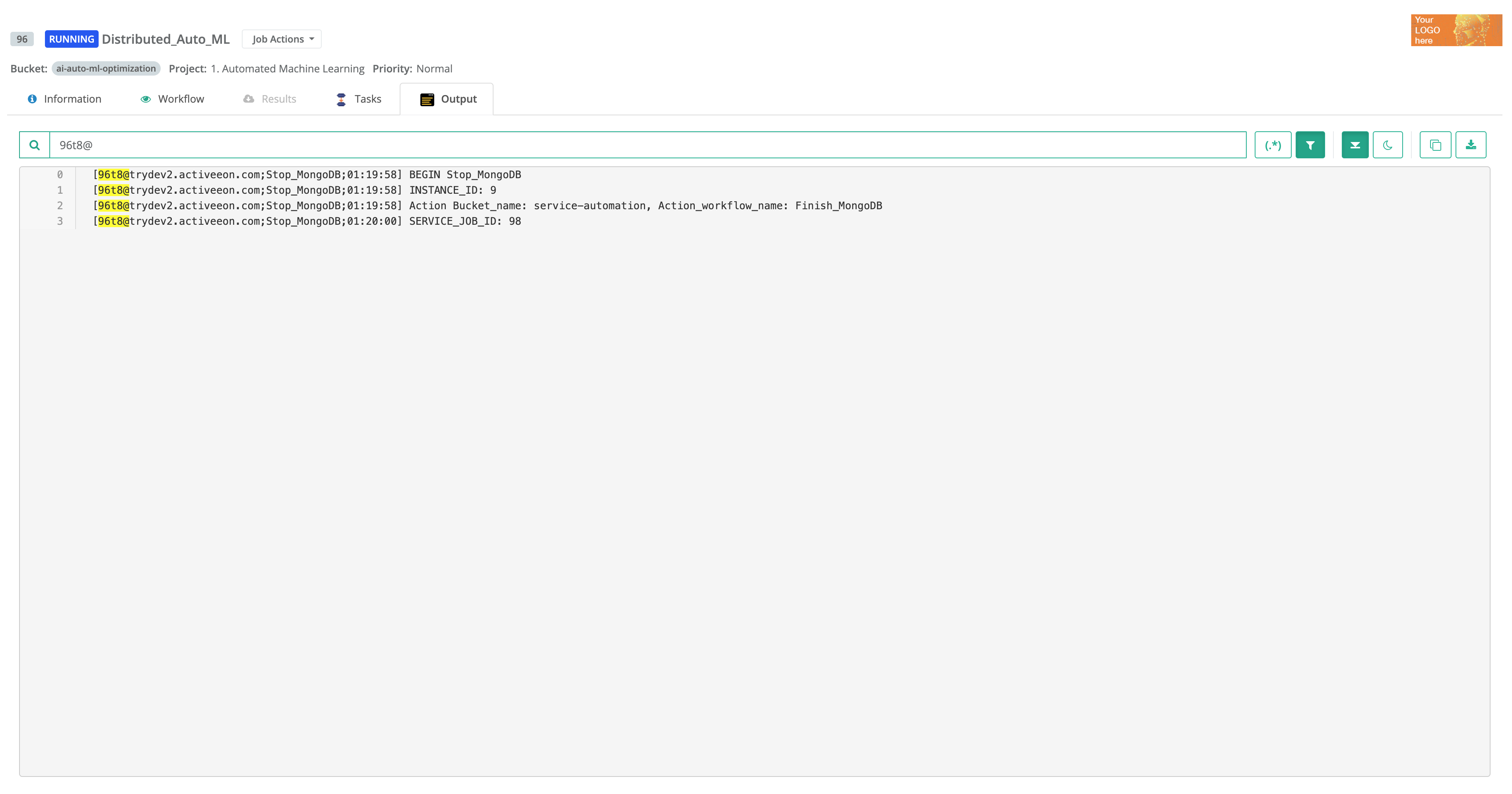
18. Addons
18.1. Statistics on ProActive Jobs and Resource Usage
This addon generates a gantt chart to visualize executions of jobs and tasks, per node and over the time.
An example of a generated gantt chart
This chart can be generated on-demand, running Gantt_chart workflow from the Analytics bucket in the Catalog.
| Please note that to run properly, this workflow requires a third party credential named "SCHEDULER_PASSWORD" with your scheduler password (so the tool can connect to the scheduler and retrieve information to build the chart) See Managing third-party credentials |
19. Reference
19.1. Job and task specification
Workflows are written in XML and we provide a XSD grammar to help you write and validate them. The Workflows XSD is available here and you can also find the documentation here.
| Setup your IDE to use the Workflow XSD, you will benefit from live validation and completion! |
19.2. Studio Tasks
This section describes the available predefined tasks in the Tasks menu of ProActive Studio and the operating systems where they run. These tasks are grouped in three sections:
-
OS Shells: Shell, Bash, Windows Cmd, PowerShell
-
Languages: Java, Scalaw, Javascript, Groovy, Ruby, Jython, Python, Perl, PHP, R
-
Containers: Dockerfile, Docker_Compose, Kubernetes
Please find in the table below a further description of these tasks.
| Predefined Task Name | Description | Operating System | Additional Requirements |
|---|---|---|---|
Shell |
Sample Script Task using the generic posix |
Linux,Mac |
|
Bash |
Sample Script Task using the posix |
Linux,Mac |
|
Windows Cmd |
Sample Script Task using the windows |
Windows |
|
PowerShell |
Sample Script Task using the |
Windows |
.NET Framework 3.5 and Poweshell 2.0 Engine must be installed |
Java |
Sample Java Task. |
Linux,Windows,Mac |
|
Scalaw |
Sample Script Task using the |
Linux,Windows,Mac |
|
Javascript |
Sample Script Task using the |
Linux,Windows,Mac |
|
Groovy |
Sample Script Task using the |
Linux,Windows,Mac |
|
Ruby |
Sample Script Task using the |
Linux,Windows,Mac |
|
Jython |
Sample Script Task using the |
Linux,Windows,Mac |
|
Python |
Sample Script Task using the |
Linux,Windows,Mac |
CPython and py4j module must be installed |
Perl |
Sample Script Task using the |
Linux,Windows,Mac |
Perl must be installed |
PHP |
Sample Script Task using the |
Linux,Mac,Windows |
PHP interpreter must be installed |
R |
Sample Script Task using the |
Linux,Windows,Mac |
R must be installed and the rJava library |
Dockerfile |
Sample Script Task using the |
Linux,Windows,Mac |
Docker must be installed |
Docker_Compose |
Sample Script Task using the |
Linux,Windows,Mac |
Docker Compose and Docker must be installed |
Kubernetes |
Sample Script Task using the |
Linux |
Kubernetes CLI must be installed |
19.3. Script Bindings Reference
This section describes useful bindings and variables, their scope, and their usage.
The different scripts a user can set are the followings:
-
selection: a script executed to select nodes suitable to execute a task. This script is executed on many nodes from the scheduling loop, before the task is deployed.
-
environment: the default mode to execute a task is to fork a dedicated JVM from the selected ProActive Node. The environment script, if defined in the workflow, is executed on the node to let the user define which environment parameters will be given to the forked JVM.
-
pre: a script which is executed before the task execution, in the same context (for example in the forked JVM).
-
task: the main script of a task when the task is a script task.
-
post: a script which is executed after the task execution, in the same context. The post script is executed only if there was no error inside the task.
-
flow: a script which is executed after the task execution, in the same context, and when the task is part of a control flow.
-
clean: a script which is executed after the task execution and any other script, directly on the node selected to execute the task (so not inside the forked JVM), whether there was a task error or not. The clean script is mainly used to clean the task host. If there was a node failure (the node is lost during the task execution), then the clean script is not executed and the task will be executed on another node.
The order in this list corresponds to the task life-cycle order. all scripts refers to all above scripts
| Variable name and description | Use from a script | Use from a native task | Use from the workflow | Available in | Not Available in |
|---|---|---|---|---|---|
Task result. Variable set by the user to return the result of a task. See Result variables. |
result = "value"; |
The result will be the exit code. |
- |
- |
|
Task result metadata. Result metadata are additional information associated with the result. The map is write-only and always empty when the task is started. See Assigning metadata to task result. |
resultMetadata.put("key", "value"); |
Not available |
- |
bash, cmd, perl, php, vbscript |
|
Job result map. Key/Value global job result. Each task can contribute to the job map. The map is write-only and always empty when the task is started (a task cannot see the operations on the map done by other tasks). See Result Map. |
resultMap.put("key", "value"); |
Not available |
- |
bash, cmd, perl, php, vbscript |
|
Task arguments. Arguments of a script defined in the workflow. Available via all kind of scripts, when referencing an external file or directly as XML elements. |
… = args[0]; |
Passed to native executable. Can also be used with $args_0 |
- |
all scripts, as external file, or XML element |
- |
Results of previous tasks. An array containing the results of parent tasks. See Result variables. |
… = results[0]; |
$results_0 |
- |
- |
|
Branch. Either "if" or "else". See branch. |
branch = "if"; |
- |
- |
flow (if) |
bash, cmd, perl, php, vbscript |
Parallel runs. Number of replications. See replication. |
runs = 3; |
- |
- |
flow (replicate) |
bash, cmd, perl, php, vbscript |
Loop variable. A boolean variable used in a flow script to decide if the loop continues or not. See loop. |
loop = false; |
- |
- |
flow (replicate) (loop) |
bash, cmd, perl, php, vbscript |
Task progress. Represents the progress of the task. Can be set to a value between 0 and 100. |
import org.ow2.proactive.scripting.helper.progress.ProgressFile; ProgressFile.setProgress(variables.get("PA_TASK_PROGRESS_FILE"), 50); |
echo "50" > $variables_PA_TASK_PROGRESS_FILE |
- |
- |
|
Workflow variables. Job variables defined in the workflow. See Workflow variables. |
variables.get("key") |
$variables_key |
${key} |
all scripts |
- |
Generic information. Generic information defined in the workflow. See Generic Information. |
genericInformation.get("key") |
$genericInformation_key |
- |
all scripts |
- |
Job ID. ID of the current job. |
variables.get( "PA_JOB_ID" ) |
$variables_PA_JOB_ID |
${PA_JOB_ID} |
all scripts |
- |
Job name. Name of the current job. |
variables.get( "PA_JOB_NAME" ) |
$variables_PA_JOB_NAME |
${PA_JOB_NAME} |
all scripts |
- |
Task ID. Id of the task. |
variables.get( "PA_TASK_ID" ) |
$variables_PA_TASK_ID |
${PA_TASK_ID} |
all scripts |
- |
Task name. Name of the task. |
variables.get( "PA_TASK_NAME" ) |
$variables_PA_TASK_NAME |
${PA_TASK_NAME} |
all scripts |
- |
User. The name of user who submitted the job. |
variables.get( "PA_USER" ) |
$variables_PA_USER |
${PA_USER} |
all scripts |
- |
Scheduler Home. Installation directory of the scheduler on the ProActive node. |
variables.get( "PA_SCHEDULER_HOME" ) |
$variables_PA_SCHEDULER_HOME |
- |
- |
|
Task iteration index. Index of iteration for this task inside a loop control. See Task executable. |
variables.get( "PA_TASK_ITERATION" ) |
$variables_PA_TASK_ITERATION |
${PA_TASK_ITERATION} |
all scripts |
- |
Task replication index. Index of replication for this task inside a replicate control. See Task executable. |
variables.get( "PA_TASK_REPLICATION" ) |
$variables_PA_TASK_REPLICATION |
${PA_TASK_REPLICATION} |
all scripts |
- |
Task Success. A variable accessible from a clean script, a flow script or a direct child task. It is a boolean value which is true if the task succeeded and false if the task failed. |
variables.get( "PA_TASK_SUCCESS" ) |
$variables_PA_TASK_SUCCESS |
- |
- |
|
Exit Value. A variable accessible from a clean script, a flow script or a direct child task. It is an integer value which contains the exit value of the task, if and only if the task contains a bash, shell, cmd, or vb script. If the task contains several of these scripts, the one executed last will prevail. |
variables.get( "EXIT_VALUE" ) |
$variables_EXIT_VALUE |
- |
- |
|
Node URL. The URL of the node which executes the current task. |
variables.get( "PA_NODE_URL" ) |
$variables_PA_NODE_URL |
${PA_NODE_URL} |
- |
|
Node URL (Selection Script). The URL of the node which executes the selection script. See Selection of ProActive Nodes. |
selected = (nodeurl == "pnp://mymachine:14200/Node1") |
- |
- |
- |
|
Node Name. The name of the node which executes the current task. |
variables.get( "PA_NODE_NAME" ) |
$variables_PA_NODE_NAME |
${PA_NODE_NAME} |
- |
|
Node Name (Selection Script). The name of the node which executes the selection script. See Selection of ProActive Nodes. |
selected = (nodename == "Node1") |
- |
- |
- |
|
Node Host. The hostname of the node which executes the current task. |
variables.get( "PA_NODE_HOST" ) |
$variables_PA_NODE_HOST |
${PA_NODE_HOST} |
- |
|
Node Source. The nodesourcename of the node which executes the current task. |
variables.get( "PA_NODE_SOURCE" ) |
$variables_PA_NODE_SOURCE |
${PA_NODE_SOURCE} |
- |
|
Node Host (Selection Script). The hostname of the node which executes the selection script. See Selection of ProActive Nodes. |
selected = (nodehost == "mymachine") |
- |
- |
- |
|
Node Tokens (Selection Script). The list of tokens attached to the node which executes the selection script. As the selection script will only be executed on Nodes which contains the token defined using the generic information NODE_ACCESS_TOKEN, nodeTokens can only be used to perform additional filtering of nodes (for example, restrict to nodes which only contains the required token and none others). See Selection of ProActive Nodes. |
selected = (!nodeTokens.contains("excludedToken")) |
- |
- |
- |
|
Scheduler REST URL. The REST url of the scheduler server. The public REST url is also available (if the setting pa.scheduler.rest.public.url is defined in |
variables.get( "PA_SCHEDULER_REST_URL" ) or variables.get( "PA_SCHEDULER_REST_PUBLIC_URL" ) |
$variables_PA_SCHEDULER_REST_URL or $variables_PA_SCHEDULER_REST_PUBLIC_URL |
${PA_SCHEDULER_REST_URL} or ${PA_SCHEDULER_REST_PUBLIC_URL} |
all scripts |
- |
Catalog REST URL. The REST url of the catalog service. The public REST url is also available (if the setting pa.catalog.rest.public.url is defined in |
variables.get( "PA_CATALOG_REST_URL" ) or variables.get( "PA_CATALOG_REST_PUBLIC_URL" ) |
$variables_PA_CATALOG_REST_URL or $variables_PA_CATALOG_REST_PUBLIC_URL |
${PA_CATALOG_REST_URL} or ${PA_CATALOG_REST_PUBLIC_URL} |
all scripts |
- |
Service Automation REST URL. The REST url of Service Automation. The public REST url is also available (if the setting pa.cloud-automation.rest.public.url is defined in |
variables.get( "PA_CLOUD_AUTOMATION_REST_URL" ) or variables.get( "PA_CLOUD_AUTOMATION_REST_PUBLIC_URL" ) |
$variables_PA_CLOUD_AUTOMATION_REST_URL or $variables_PA_CLOUD_AUTOMATION_REST_PUBLIC_URL |
${PA_CLOUD_AUTOMATION_REST_URL} or ${PA_CLOUD_AUTOMATION_REST_PUBLIC_URL} |
all scripts |
- |
Job Planner REST URL. The REST url of the job-planner service. The public REST url is also available (if the setting pa.job-planner.rest.public.url is defined in |
variables.get( "PA_JOB_PLANNER_REST_URL" ) or variables.get( "PA_JOB_PLANNER_REST_PUBLIC_URL" ) |
$variables_PA_JOB_PLANNER_REST_URL or $variables_PA_JOB_PLANNER_REST_PUBLIC_URL |
${PA_JOB_PLANNER_REST_URL} or ${PA_JOB_PLANNER_REST_PUBLIC_URL} |
all scripts |
- |
Notification Service REST URL. The REST url of the notification service. The public REST url is also available (if the setting pa.notification-service.rest.public.url is defined in |
variables.get( "PA_NOTIFICATION_SERVICE_REST_URL" ) or variables.get( "PA_NOTIFICATION_SERVICE_REST_PUBLIC_URL" ) |
$variables_PA_NOTIFICATION_SERVICE_REST_URL or $variables_PA_NOTIFICATION_SERVICE_REST_PUBLIC_URL |
${PA_NOTIFICATION_SERVICE_REST_URL} or ${PA_NOTIFICATION_SERVICE_REST_PUBLIC_URL} |
all scripts |
- |
Third party credentials. Credentials stored on the server for this user account. See Managing third-party credentials |
credentials.get( "pw" ) |
$credentials_pw |
$credentials_pw (only in the task arguments) |
- |
|
SSH private key. Private SSH Key used at login. See Run Computation with a user’s system account. |
credentials.get( "SSH_PRIVATE_KEY" ) |
$credentials_SSH_PRIVATE_KEY |
- |
- |
|
Number of nodes. Number of nodes used by this task. See Example: MPI application. |
nodesurl.size() |
$variables_PA_NODESNUMBER |
- |
environment, pre, task, post, flow |
- |
Url of nodes. List of URL of nodes. See Example: MPI application. |
nodesurl.get(0) |
$variables_PA_NODESFILE |
- |
environment, pre, task, post, flow |
- |
User space. Location of the user space. See Data Spaces. |
println userspace |
$userspace |
$userspace (only in tasks arguments) |
environment, pre, task, post, flow |
- |
Global space. Location of the global space. See Data Spaces. |
println globalspace |
$globalspace |
$globalspace (only in tasks arguments) |
environment, pre, task, post, flow |
- |
Input space. Location of the input space. See Data Spaces. |
println inputspace |
$inputspace |
- |
environment, pre, task, post, flow |
- |
Local space. Location of the local space. See Data Spaces. |
println localspace |
$localspace |
$localspace (only in tasks arguments) |
environment, pre, task, post, flow |
- |
Cache space. Location of the cache space. See Data Spaces. |
println cachespace |
$cachespace |
$cachespace (only in tasks arguments) |
environment, pre, task, post, flow |
- |
Output space. Location of the output space. See Data Spaces. |
println outputspace |
$outputspace |
- |
environment, pre, task, post, flow |
- |
Selection. Variable which must be set to select the node. See Selection of ProActive Nodes. |
selected = true |
- |
- |
bash, cmd, perl, php, vbscript |
|
Fork Environment. Fork Environment variable is a ForkEnvironment java object allowing a script to set various initialization parameters of the forked JVM. See Fork Environment |
forkEnvironment.setJavaHome( "/usr/java/default" ) |
- |
- |
bash, cmd, perl, php, R, powershell, vbscript |
|
Scheduler API. Scheduler API variable is a SchedulerNodeClient java object which can connect to the ProActive Scheduler frontend and interact directly with its API. |
schedulerapi.connect() |
- |
- |
bash, cmd, perl, php, R, powershell, vbscript |
|
Resource Manager API. Resource Manager API variable which can connect to the ProActive RM frontend and interact directly with its API. |
rmapi.connect() |
- |
- |
bash, cmd, perl, php, R, powershell, vbscript |
|
UserSpace API. UserSpace API variable is a DataSpaceNodeClient java object which can connect to the User Space and interact directly with its API. |
userspaceapi.connect() |
- |
- |
bash, cmd, perl, php, R, powershell, vbscript |
|
GlobalSpace API. GlobalSpace API variable is a DataSpaceNodeClient java object which can connect to the Global Space and interact directly with its API. |
globalspaceapi.connect() |
- |
- |
bash, cmd, perl, php, R, powershell, vbscript |
|
Synchronization API. Synchronization API variable is a ../javadoc/org/ow2/proactive/scheduler/synchronization/Synchronization.html[Synchronization java object] which can connect to the Synchronization Service and interact directly with its API. |
synchronizationapi.createChannel("channel1", false) |
- |
- |
all scripts |
bash, cmd, perl, php, R, powershell, vbscript |
Signal API. Signal API variable is a ../javadoc/org/ow2/proactive/scheduler/signal/SignalApi.html[SignalApi java object] that allows to manage job signals using its underlying API. |
signalapi.sendSignal("stop") |
- |
- |
all scripts |
bash, cmd, perl, php, R, powershell, vbscript |
19.3.1. Variables maps
The syntax for accessing maps (like variables, credentials or genericInformation) is language dependent.
For Groovy:
print variables.get("key")For Python/Jython:
print variables["key"]For Ruby:
puts variables["key"]For R:
print(variables[["key"]])For Bash (using environment variables):
echo $variables_keyFor Cmd (using environment variables):
echo %variables_key%For VBScript (using process environment variables):
Set wshShell = CreateObject( "WScript.Shell" )
Set wshProcessEnv = wshShell.Environment( "PROCESS" )
Wscript.Echo "Hello World from Job " & wshProcessEnv( "variables_key" )For PowerShell:
Write-Output $variables.Get_Item('key')For PHP:
<?php
echo "<p>Value of variable: ".getenv("variables_key")."</b></p>";
?>19.3.2. Script results
The last statement of a script corresponds to the script result. The result can also be explicitly set with a manual affectation to a result variable.
Different kind of scripts (selection, flow, etc) will need to affect different kind of variable as results (for example selected, branch, runs, etc).
Example for Groovy selection scripts:
selected = java.net.InetAddress.getLocalHost().getHostName() == "mymachine"It is important to note that the result of a script will be converted to Java, and that some internal language types are not automatically convertible. If the task displays an error due to the result conversion, several approaches can be used:
-
the script can manually convert the internal type to a more primitive type.
-
the result can instead be stored in a file and transferred as an output file.
Results of parent tasks are stored in the results variable. Like the variables map, accessing this results variable is language-dependant.
For ruby, python, jython or groovy script languages, the parent tasks results (results variable) contains a list of TaskResult java object. In order to access the result real value, the value() method of this object must be called:
Example for Python/Jython:
print results[0].value()Other languages such as R or PowerShell can access the results directly
Example for R:
print(results[[0]])More information about various script engines particularities and syntax is available in the Script Languages chapter.
19.4. Topology Types
ProActive Scheduler supports the following nodes topologies for multi-nodes tasks.
-
Arbitrary topology does not imply any restrictions on nodes location
<parallel numberOfNodes="4">
<topology>
<arbitrary/>
</topology>
</parallel>-
Best proximity - the set of closest nodes among those which are not executing other tasks.
<parallel numberOfNodes="4">
<topology>
<bestProximity/>
</topology>
</parallel>-
Threshold proximity - the set of nodes within a threshold proximity (in microseconds).
<parallel numberOfNodes="4">
<topology>
<thresholdProximity threshold="100"/>
</topology>
</parallel>-
Single Host - the set of nodes on a single host.
<parallel numberOfNodes="4">
<topology>
<singleHost/>
</topology>
</parallel>-
Single Host Exclusive - the set of nodes of a single host exclusively. The host with selected nodes will be reserved for the user.
<parallel numberOfNodes="4">
<topology>
<singleHostExclusive/>
</topology>
</parallel>For this task the scheduler will try to find a host with 4 nodes. If there is no such a host another one will be used with a bigger capacity (if exists). In this case extra nodes on this host will be also occupied by the task but will not be used for the execution.
-
Multiple Hosts Exclusive - the set of nodes filled in multiple hosts. Hosts with selected nodes will be reserved for the user.
<parallel numberOfNodes="4">
<topology>
<multipleHostsExclusive/>
</topology>
</parallel>For this task the scheduler will try to find 4 nodes on a set of hosts. If there is no such a set which gives you exactly 4 nodes another one will be used with a bigger capacity (if exists). In this case extra nodes on this host will be also occupied by the task but will not be used for the execution.
-
Different Hosts Exclusive - the set of nodes each from a different host. All hosts with selected nodes will be reserved for the user.
<parallel numberOfNodes="4">
<topology>
<differentHostsExclusive/>
</topology>
</parallel>For this task the scheduler will try to find 4 hosts with one node on each. If number of "single node" hosts are not enough hosts with bigger capacity will be selected. In this case extra nodes on this host will be also occupied by the task but will not be used for the execution.
19.5. Scheduler GraphQL API
19.5.1. Scheduler GraphQL API portal
ProActive Scheduler GraphQL API portal can be accessed in your environment using the following link:
In general, the GraphiQL interface can be opened at http://your-server:8080/scheduling-api/v1/graphiql or https://your-server:8443/scheduling-api/v1/graphiql when the scheduler server is configured in https mode.
In order to use it, you must be first connected to one of the ProActive portals. If you are not currently connected or if your session has expired, you will receive a MissingSessionIdException when trying to run queries.
This portal allows to run GraphQL queries against the scheduler database, to find jobs according to various filters. Queries are read-only, you cannot use this portal to perform stateful operations (e.g job submission, job removal, etc).
The GraphiQL interface is displayed as the following:
You can explore the Docs section to see detailed information about all GraphQL nodes, filters and attributes:
GraphQL Basic Usage
The left panel allows to write queries. You can start by entering the query { jobs }, this query will be automatically expanded to match the correct syntax:
{jobs {
edges {
node {
id
}
}
}}Executing this query will return a json result such as:
{
"data": {
"jobs": {
"edges": [
{
"node": {
"id": "1"
}
},
{
"node": {
"id": "2"
}
},
{
"node": {
"id": "3"
}
}
]
}
}
}In this basic example, only the job ids are displayed, it is of course possible to display more information:
{
jobs {
edges {
node {
id
name
owner
submittedTime
status
}
}
}
}Will return something similar to:
{
"data": {
"jobs": {
"edges": [
{
"node": {
"id": "1",
"name": "script_groovy",
"owner": "admin",
"submittedTime": 1589799002016,
"status": "FINISHED"
}
},
{
"node": {
"id": "2",
"name": "script_groovy",
"owner": "admin",
"submittedTime": 1589799356783,
"status": "FINISHED"
}
},
{
"node": {
"id": "3",
"name": "Script_Cmd",
"owner": "admin",
"submittedTime": 1589810586677,
"status": "FINISHED"
}
}
]
}
}
}GraphQL Pagination
GraphQL results are paginated, a request can use one of the following attributes to control pagination:
-
last(integer) : displays the specified last number of results. -
first(integer) : displays the specified first number of results. -
before(cursor) : displays results before the specified cursor -
after(cursor) : displays results after the specified cursor
The following requests uses last to display the 5 most recent jobs, and displays all pages information.
{
jobs(last: 5) {
edges {
node {
id
}
cursor
}
pageInfo {
hasNextPage
hasPreviousPage
startCursor
endCursor
}
}
}It returns something similar to:
{
"data": {
"jobs": {
"edges": [
{
"node": {
"id": "11"
},
"cursor": "Z3JhcGhxbC1jdXJzb3IxMQ=="
},
{
"node": {
"id": "12"
},
"cursor": "Z3JhcGhxbC1jdXJzb3IxMg=="
},
{
"node": {
"id": "13"
},
"cursor": "Z3JhcGhxbC1jdXJzb3IxMw=="
},
{
"node": {
"id": "14"
},
"cursor": "Z3JhcGhxbC1jdXJzb3IxNA=="
},
{
"node": {
"id": "15"
},
"cursor": "Z3JhcGhxbC1jdXJzb3IxNQ=="
}
],
"pageInfo": {
"hasNextPage": false,
"hasPreviousPage": true,
"startCursor": "Z3JhcGhxbC1jdXJzb3IxMQ==",
"endCursor": "Z3JhcGhxbC1jdXJzb3IxNQ=="
}
}
}
}To display the previous page, the following request is used:
{
jobs(last: 5, before: "Z3JhcGhxbC1jdXJzb3IxMQ==") {
edges {
node {
id
}
cursor
}
pageInfo {
hasNextPage
hasPreviousPage
startCursor
endCursor
}
}
}Which returns a result such as:
{
"data": {
"jobs": {
"edges": [
{
"node": {
"id": "6"
},
"cursor": "Z3JhcGhxbC1jdXJzb3I2"
},
{
"node": {
"id": "7"
},
"cursor": "Z3JhcGhxbC1jdXJzb3I3"
},
{
"node": {
"id": "8"
},
"cursor": "Z3JhcGhxbC1jdXJzb3I4"
},
{
"node": {
"id": "9"
},
"cursor": "Z3JhcGhxbC1jdXJzb3I5"
},
{
"node": {
"id": "10"
},
"cursor": "Z3JhcGhxbC1jdXJzb3IxMA=="
}
],
"pageInfo": {
"hasNextPage": true,
"hasPreviousPage": true,
"startCursor": "Z3JhcGhxbC1jdXJzb3I2",
"endCursor": "Z3JhcGhxbC1jdXJzb3IxMA=="
}
}
}
}GraphQL Filters
GraphQL API allows to select jobs according to various filters. The following example filters jobs according to a given name:
{
jobs(filter: {name: "*Python"}) {
edges {
node {
id name
}
}
}
}The wildcard "*Python" selects all jobs ending with "Python". The special character * can be used at the beginning or at the end of the expression (or both). It cannot be used in the middle.
Here are the results of this GraphQL query:
{
"data": {
"jobs": {
"edges": [
{
"node": {
"id": "8",
"name": "Script_Python"
}
},
{
"node": {
"id": "9",
"name": "Script_Python"
}
},
{
"node": {
"id": "10",
"name": "Script_Python"
}
},
{
"node": {
"id": "11",
"name": "Script_Python"
}
}
]
}
}
}The complete list of filters is available in the GraphQL Docs section.
19.5.2. Scheduler GraphQL REST API
After testing queries in the GraphQL Portal, you can use the scheduling-api REST interface to run these queries from any REST client.
Few aspects are to be considered when running graphql queries from a REST client:
-
The url of the GraphQL REST API is different:
http://your-server:8080/scheduling-api/v1/graphql(graphql instead of graphiql). -
The REST request method must be
POSTand itsContent-Typebeapplication/json. -
It requires in the header section, a
sessionidretrieved from a login to the ProActive scheduler REST API. -
The query itself is given as a string value of the
"query"attribute inside the json body content. This value must be escaped to be a valid json. You can use, for example, online tools such ashttps://codebeautify.org/json-escape-unescapeto escape the query as a json string.
Here is an example of executing a GraphQL REST query using curl.
-
First, we acquire a sessionid by login to the scheduler REST API:
sessionid=$(curl -d "username=mylogin&password=mypassword" http://try.activeeon.com:8080/rest/scheduler/login) -
Second, we use a json escape tool to produce the query parameter.
{ jobs { edges { node { id name } } } }Converts into:
{\r\n jobs {\r\n edges {\r\n node {\r\n id\r\n name\r\n }\r\n }\r\n }\r\n} -
Third, we write the json body.
{"query":"{\r\n jobs {\r\n edges {\r\n node {\r\n id\r\n name\r\n }\r\n }\r\n }\r\n}"} -
Finally, we execute the query using
curl:curl -H "sessionid:$sessionid" -H "Content-Type:application/json" --request POST --data '{"query":"{\r\n jobs {\r\n edges {\r\n node {\r\n id\r\n name\r\n }\r\n }\r\n }\r\n}"}' http://try.activeeon.com:8080/scheduling-api/v1/graphql -
We receive the following json answer to our request:
{"data":{"jobs":{"edges":[{"node":{"id":"14","name":"script_groovy"}},{"node":{"id":"66","name":"Script_Python"}},{"node":{"id":"67","name":"Script_Python"}},{"node":{"id":"68","name":"Script_Python"}},{"node":{"id":"69","name":"Script_Python"}},{"node":{"id":"70","name":"Script_Python"}},{"node":{"id":"71","name":"script_groovy"}},{"node":{"id":"72","name":"script_groovy"}},{"node":{"id":"73","name":"script_groovy"}},{"node":{"id":"74","name":"script_groovy"}},{"node":{"id":"75","name":"script_groovy"}}]}}}
19.6. Command Line
The ProActive client allows to interact with the Scheduler and Resource Manager. The client has an interactive mode started if you do not provide any command.
The client usage is also available using the -h parameter as shown below:
$ PROACTIVE_HOME/bin/proactive-client -h
19.6.1. Command Line Examples
Deploy ProActive Nodes
In non-interactive mode
$ PROACTIVE_HOME/bin/proactive-client -cn 'moreLocalNodes' -infrastructure 'org.ow2.proactive.resourcemanager.nodesource.infrastructure.LocalInfrastructure' './config/authentication/rm.cred' 4 60000 '' -policy org.ow2.proactive.resourcemanager.nodesource.policy.StaticPolicy 'ALL' 'ALL'In interactive mode
$ PROACTIVE_HOME/bin/proactive-client
> createns( 'moreLocalNodes', ['org.ow2.proactive.resourcemanager.nodesource.infrastructure.LocalInfrastructure', './config/authentication/rm.cred', 4, 60000, ''], ['org.ow2.proactive.resourcemanager.nodesource.policy.StaticPolicy', 'ALL', 'ALL'])Install ProActive packages
To install a ProActive package, you can use the ProActive CLI by providing a path to your package. It can be a local directory, a ZIP file or can be a URL to a web directory, a direct-download ZIP file, a GitHub repository or ZIP or a directory inside a GitHub repository. Please note that URL forwarding is supported.
In non-interactive mode
-
To install a package located in a local directory or ZIP
$ PROACTIVE_HOME/bin/proactive-client -pkg /Path/To/Local/Package/Directory/Or/Zip-
To install a package located in a web folder (Supports only Apache Tomcat directory listing)
$ PROACTIVE_HOME/bin/proactive-client -pkg http://example.com/installablePackageDirectory/-
To install a package with a direct download ZIP URL:
$ PROACTIVE_HOME/bin/proactive-client -pkg https://s3.eu-west-2.amazonaws.com/activeeon-public/proactive-packages/package-example.zip-
To install a package located in a GitHub repository (either in the repository root or in a sub-folder within a repository):
$ PROACTIVE_HOME/bin/proactive-client -pkg https://github.com/ow2-proactive/hub-packages/tree/master/package-exampleIn interactive mode
-
To install a package located in any of the aforementioned possible locations
$ PROACTIVE_HOME/bin/proactive-client
> installpackage(PackagePathOrURL)Legal notice
Activeeon SAS, © 2007-2019. All Rights Reserved.
For more information, please contact contact@activeeon.com.