All documentation links
ProActive Workflows & Scheduling (PWS)
-
PWS User Guide
(Workflows, Workload automation, Jobs, Tasks, Catalog, Resource Management, Big Data/ETL, …) PWS Modules
Job Planner
(Time-based Scheduling)Event Orchestration
(Event-based Scheduling)Service Automation
(PaaS On-Demand, Service deployment and management)
PWS Admin Guide
(Installation, Infrastructure & Nodes setup, Agents,…)
ProActive AI Orchestration (PAIO)
PAIO User Guide
(a complete Data Science and Machine Learning platform, with Studio & MLOps)
1. Main principles of PSA
ProActive Service Automation (PSA) allows automating service deployment, together with their life-cycle management. Services are instantiated by workflows (executed as a Job by the Scheduler), and related workflows allow to move instances from a state to another one.
At any point in time, each Service Instance has a specific State (RUNNING, ERROR, FINISHED, etc.).
Attached to each Service Instance, PSA service stores some information such as: Service Instance Id, Service Id, Service Instance State, the ordered list of Jobs executed for the Service, a set of variables with their values (a map that includes for instance the service endpoint), etc.
The tutorials Create your own basic service or Create your own advanced service help you to build your own services.
1.1. Definitions and Concepts
The following terms are used as ProActive Service Automation (PSA) definitions and main concepts:
- Service
-
A set of workflows representing Actions and having the same Service ID.
- Activated Service or Service Instance
-
An Activated Service is an Instance of a Service. It is characterized by a Service ID and an Instance ID.
- Action
-
An Action will launch a workflow on a Service Instance modifying its State. An action is characterized by <a Service ID + a workflow ID + a state>. The Service ID and the State are respectively named « pca.service.id » and « pca.states » in the list of the workflow Generic Information.
An Action goes from an initial State and conducts to a target State after the Transition is completed. As an Action must be deterministic, for an given initial State it can conduct to a unique target state.
There are three specific kinds of Actions:
-
Activation: to start a Service Instance (from the State VOID to a defined State)
-
Finishing: to stop a Service Instance (from a defined State to the State FINISHED)
-
Killing: PSA is trying to force a Service Instance to terminate (from a defined State to the State KILLED)
- States
-
The specific States that are pre-defined in ProActive Service Automation are VOID, FINISHED, ERROR, KILLED.
-
VOID Implicit State before a Service is activated
-
FINISHED Implicit State after a Service is terminated/no longer activated
-
ERROR Implicit State after something wrong happened
-
KILLED When PSA abnormally forces an Activated Service to terminate.
-
| Please note that users are free to define their own custom States (e.g. RUNNING, SUSPENDED, …) |
- Endpoints
-
Endpoints are a list of (Key,Value) defined in the Variables e.g. [(spark_master_gui, <spark_master_gui>), (spark_worker_0_gui, <spark_worker_0_gui>), (spark_worker_1_gui, <spark_worker_1_gui>)]. The endpoint URL should contain the protocol, e.g. www.activeeon.com will not work, but https://www.activeeon.com will.
| To run multiple PSA services that share an endpoint, the same ENDPOINT_ID value should be given to all of the PSA services that, when started, require this variable. |
- Service_Name, Infrastructure_Name
-
Service_Name, Infrastructure_Name are Service specific. If a Service wants/needs them, they can be stored in the data associated to the service to give a name to the service, to identify the infrastructure where the Service Instance will be deployed.
- Label
-
An optional string given at the launch of a Service, and that can be used to more easily identify a given service in the Service Automation Portal.
1.2. Service Transitions
This paragraph describes how an Activated Service goes from one State to another. For instance how the Activated Service S1 transitions from the State RUNNING to the State SUSPENDED.
- States and Transition Syntax
-
The States as well as the Transitions from one State to another are provided in workflows Generic Information named « pca.states » with the following syntax:
pca.states=(a,b) or pca.states=(a,b)(c,d)…(e,f)
meaning that the current workflow, for the current Service ID, when activated in State a, will transition the Service Instance in State b; or if activated in State c, the target state will be d.
An Activation Workflow (allowing to start a Service Instance) will have pca.states=(VOID,x).
A Finishing Workflow (allowing to terminate a Service Instance) can have for instance pca.states=(RUNNING,FINISHED)(SUSPENDED,FINISHED)
- Service Transitions
-
Actions that can be applied on Activated Services depend on their State. If they are in the State « CUR_STATE », all the workflow actions that have the Generic Information named « pca.states » equal to (CUR_STATE, xyz_state) or (ALL, xyz_state) can be executed. After executing the workflow actions, if everything goes right, the Activated Services will be in the state « xyz_state ».
- Transitioning
-
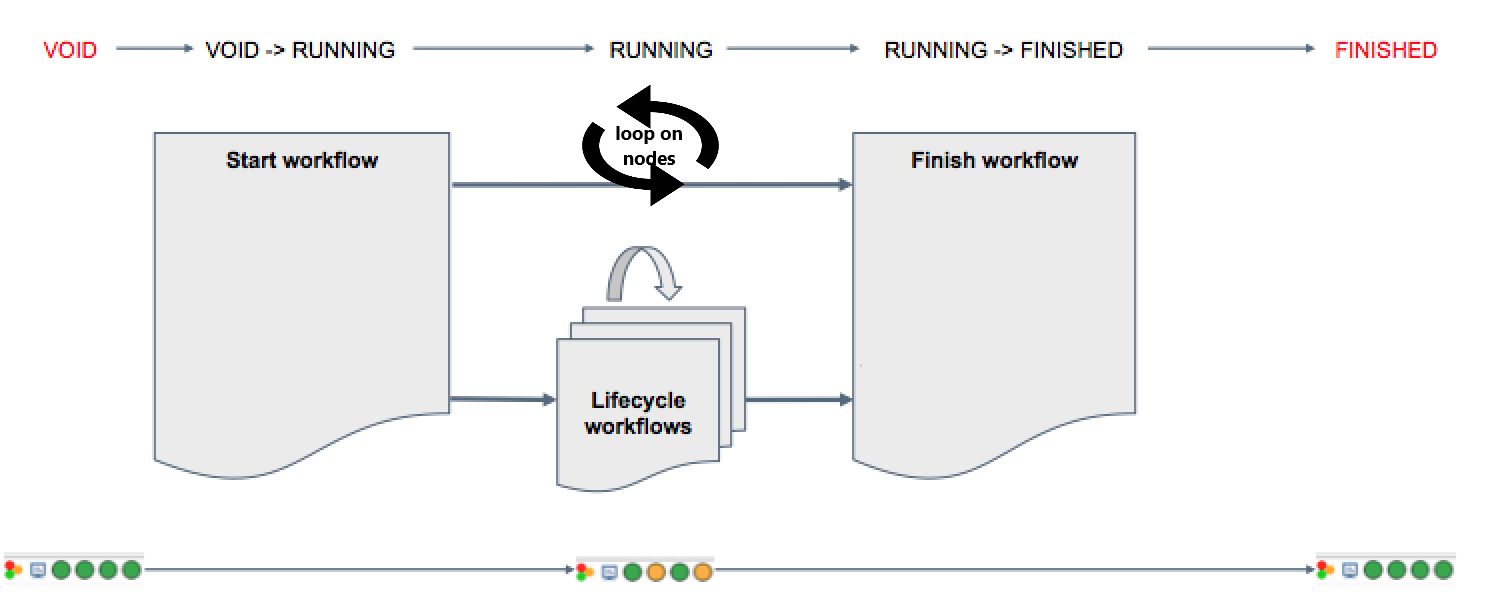
An Activated Service can be in a specific Transitioning State. In that case the State is labeled with the string "INITIAL_STATE -→ DESTINATION_STATE", for instance "RUNNING -→ FINISHED". No new Action can be started on a Transitioning Activated Service, except the Kill action.
-
When a PSA Workflow deploys a Service, it loops on the targeted nodes to control the service health (with a cron-loop). Moreover, the targeted nodes can be "reserved" by the service using dedicated tokens (token "tensorboard", token "spark",..). The Nodes being used can be taken from an existing Node Source (e.g. ServiceNodeSource), or launched specifically at the beginning of the deployment (e.g. starting a NodeSource on Azure Cloud).
-
| Please note that the Service must contain at least two workflows: a start workflow which will create the Service Instance and a finish workflow which will delete the Service Instance. The start workflow cron-loops on the targeted nodes until an action changes the Service Instance State. |
- End of Transitioning
-
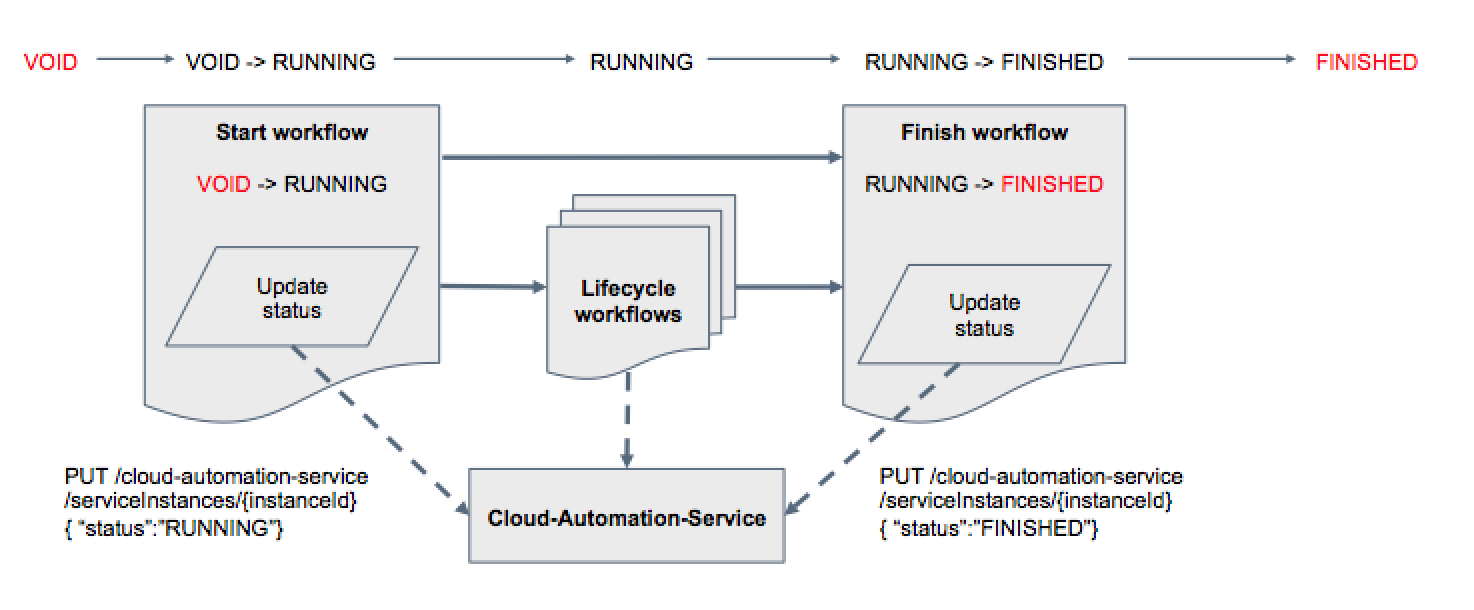
There is no implicit detection of the end of a Transitioning State. A workflow that carries on a transition has to inform Service Automation that the transition is actually successfully finished. Each service workflows will contain a task that will update the Service Instance State after finishing its Actions.
- Workflows for Service Deployment
-
A workflow that deploys a Service Instance will wait (Sleep Loop) for a State change and terminate in a correct manner. There are 2 possibilities:
-
Wait until the beginning of the Transition: e.g. no longer State RUNNING. (The state can be "from RUNNING to FINISHED".)
-
Wait until the end of the Transition: e.g. FINISHED (The state cannot be Transitioning, neither RUNNING, but has to have reached rather "FINISHED".) This is the preferred choice to avoid the service nodes being given to another Task/Service before a Delete Action actually remove the Service Instance artifacts
-
- Submission of a Workflow by PSA
-
To execute an Action, PSA will submit a Workflow to the scheduler, using as Variable Map all the Variables that have been collected and updated so far for that Service. A first Task in the Wf is expected to collect all the values, even those not explicitly being Wf Variables.
- Information of Service Instance
-
A Service Automation Workflow and third parties can get access to information about a Service Instance through Service Automation. It allows for instance a Delete Action to get the URLs of the Nodes where the Service Instance is deployed, or the Docker Containers that are being used and need to be killed to terminate the Service Instance. E.g. A Service Automation workflow that starts Docker containers on the nodes is expected to store the Docker Ids in Service Automation for that Instance.
- Variables stored in a Service Instance
-
From the beginning of its Activation, when an Action is executed, the Variables/Values of the action Workflows are stored and append within the PSA service for that service instance. When a Variable already existed in the list, its value is updated with the last workflow value (AddAll).
- Workflows executed by a Service Instance
-
From the beginning of its Activation, until it reaches the FINISH state, a Service Instance has in PSA service (and accessible through the API) the ordered list of Job Id that has been executed as Action on it. Besides the Job ids, Service Automation service does not duplicate and store any information about the Job. Service Automation portal will get those information from the Scheduler.
- Endpoints
-
Endpoints are a list of Key/Value defined in the Variables e.g. [(spark_master_gui, <spark_master_gui>), (spark_worker_0_gui, <spark_worker_0_gui>), (spark_worker_1_gui, <spark_worker_1_gui>)]
1.3. Service Execution
PSA services can be instantiated in two different ways:
1- Via the ProActive Service Automation (PSA) Portal.
2- Via Workflow Execution Portal. To launch PSA services, you have to open the Submit Window in the Workflow Execution Portal and then select 'Service Workflows Only' option to filter PSA services from the list of workflows. After selecting a PSA service to submit, you can provide variable values that help configure this service then press submit.
2. PSA Portal
2.1. Overall View
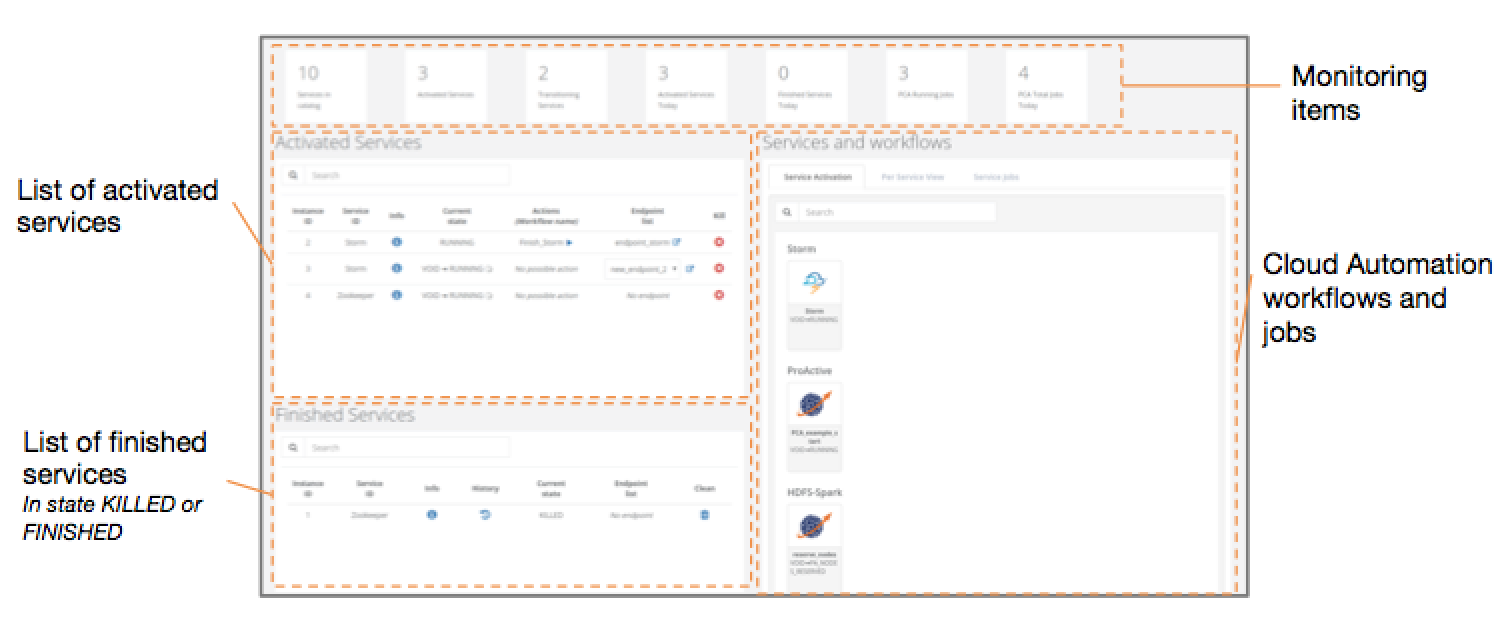
The ProActive Service Automation (PSA) Portal has a view with four main sections:
-
The Service Automation workflows
-
The list of activated Services Instances
-
The list of finished or killed Services Instances
-
The monitoring items
2.2. Detailed View
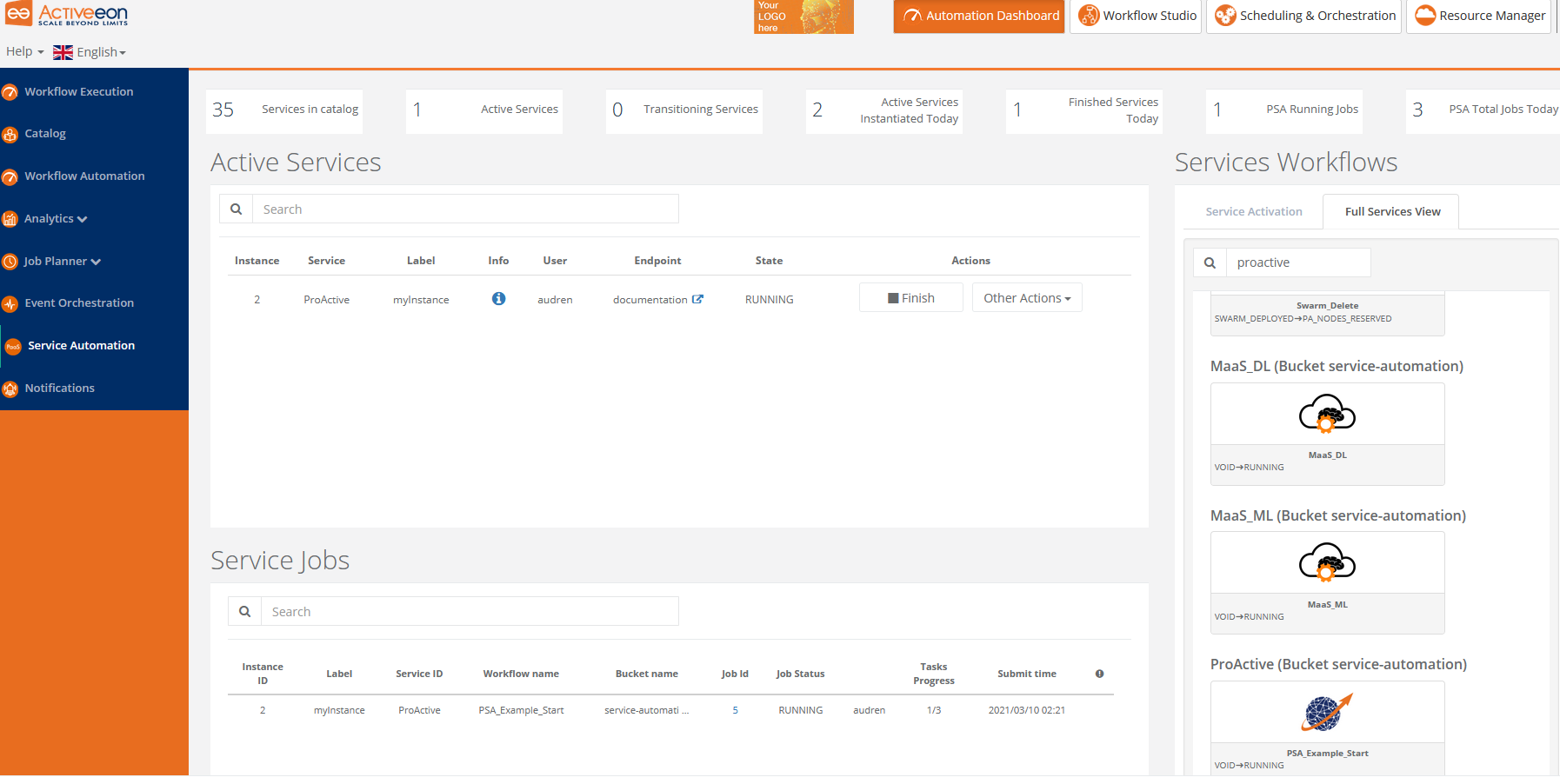
The ProActive Service Automation (PSA) Portal allows to have access on several tabs.
-
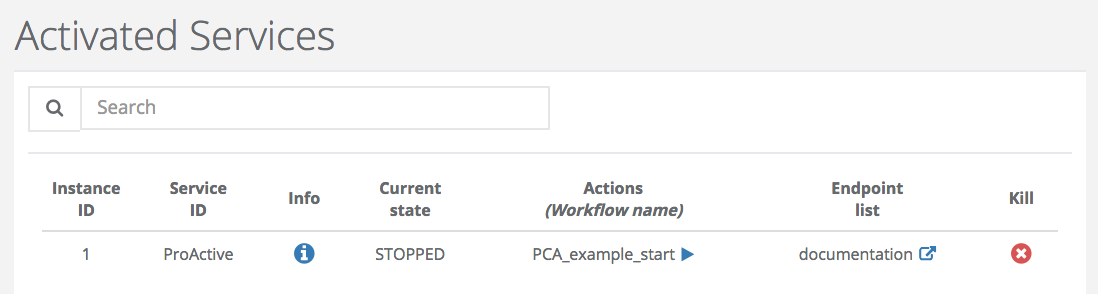
Service Activation shows the list of workflow that allows activating a Service Instance. Only creation workflows with VOID as origin State are displayed. It is possible to get the latest version of the services by using the refresh button.
-
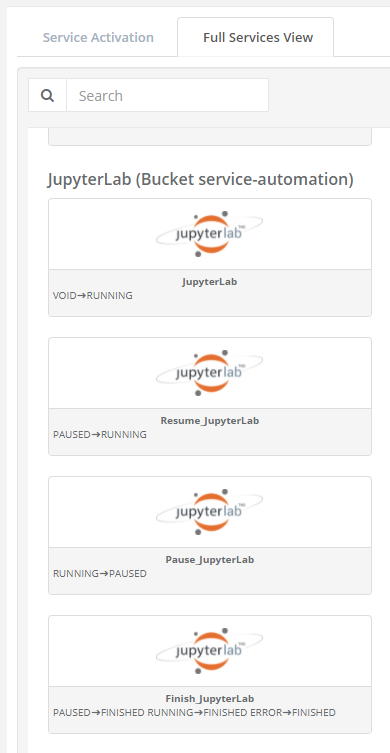
Full Services View gives all Service Automation workflows sorted by Service. Only creation workflows can be submitted from this tab to create Service Instances.
-
Service Jobs shows all jobs related to activated Service Instances grouped by Service Instances.
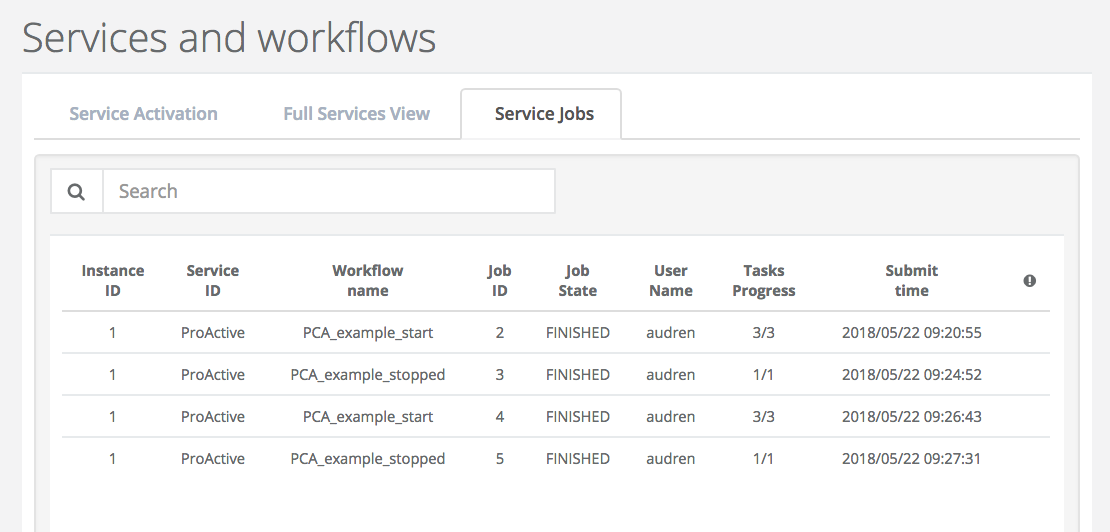
-
Activated Services gives the list of Services that are not in State ‘FINISHED’ or ‘KILLED’.
-
Finished Services shows the list of Services that are in State ‘FINISHED’ and ‘KILLED’. The CLEAN action removes the Service Instance from the database.
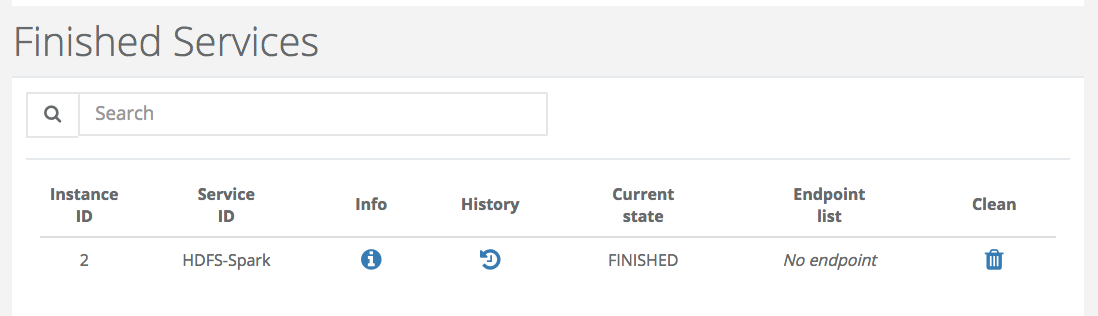
-
Monitoring Items

2.3. Usage examples
In this section, we show how to start a PSA service and how to use actions that manage its life cycle. To do that, we choose MongoDB and Spark/Hdfs PSA services as running examples.
2.3.1. MongoDB
-
Start MongoDB
To start the mongoDB service, you have to go to Service Automation section in the automation dashboard portal and choose MongoDB service from the service activation tab. At this point, you can provide values for variables that help configure this service then press execute.
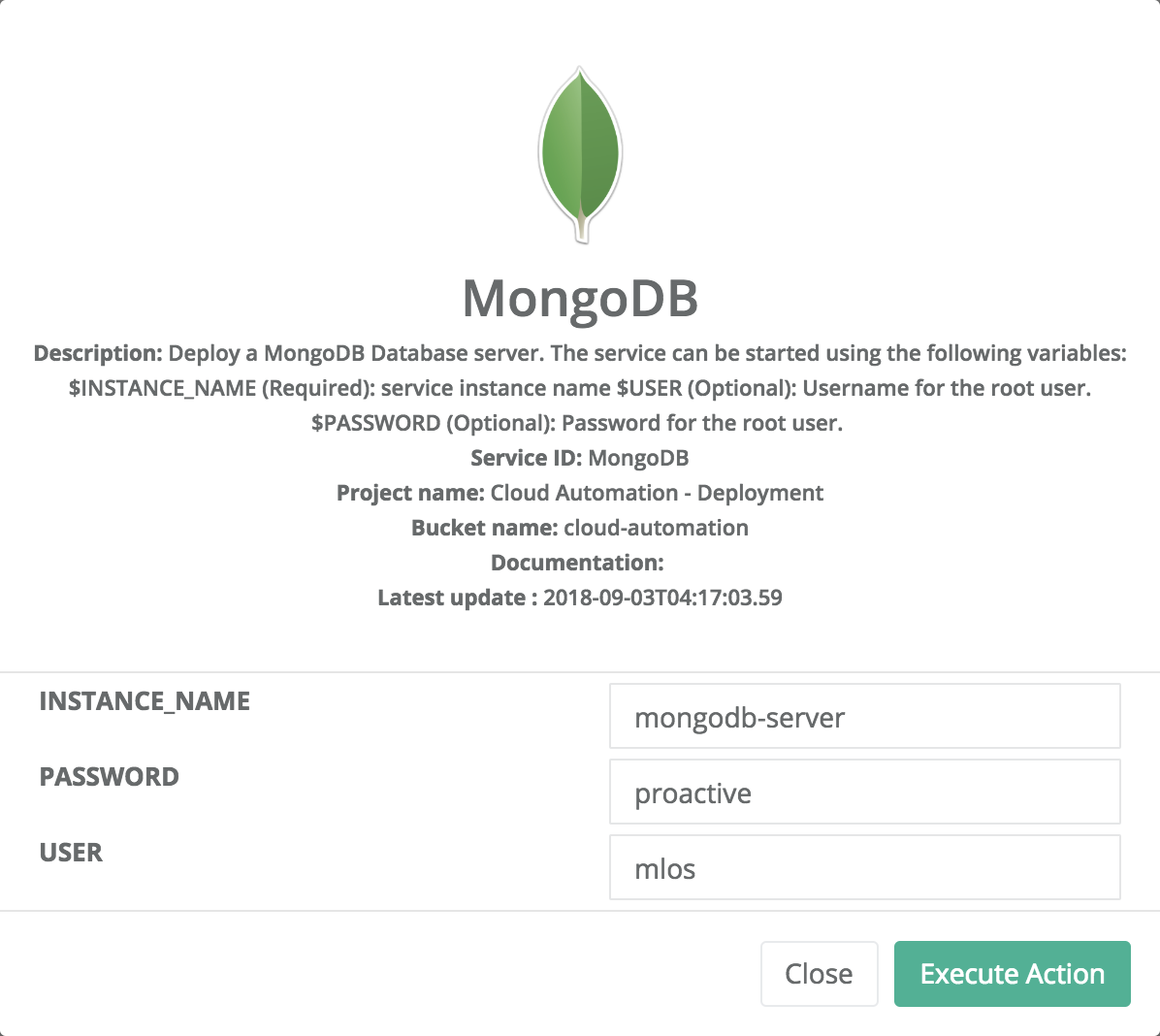
Once the MongoDB service is deployed, the state of the instance becomes RUNNING. At this stage, you can interact with the database provided by this PSA service. For this, you might need a host and a port number that can be retrieved from the endpoint displayed in the info window as shown bellow:
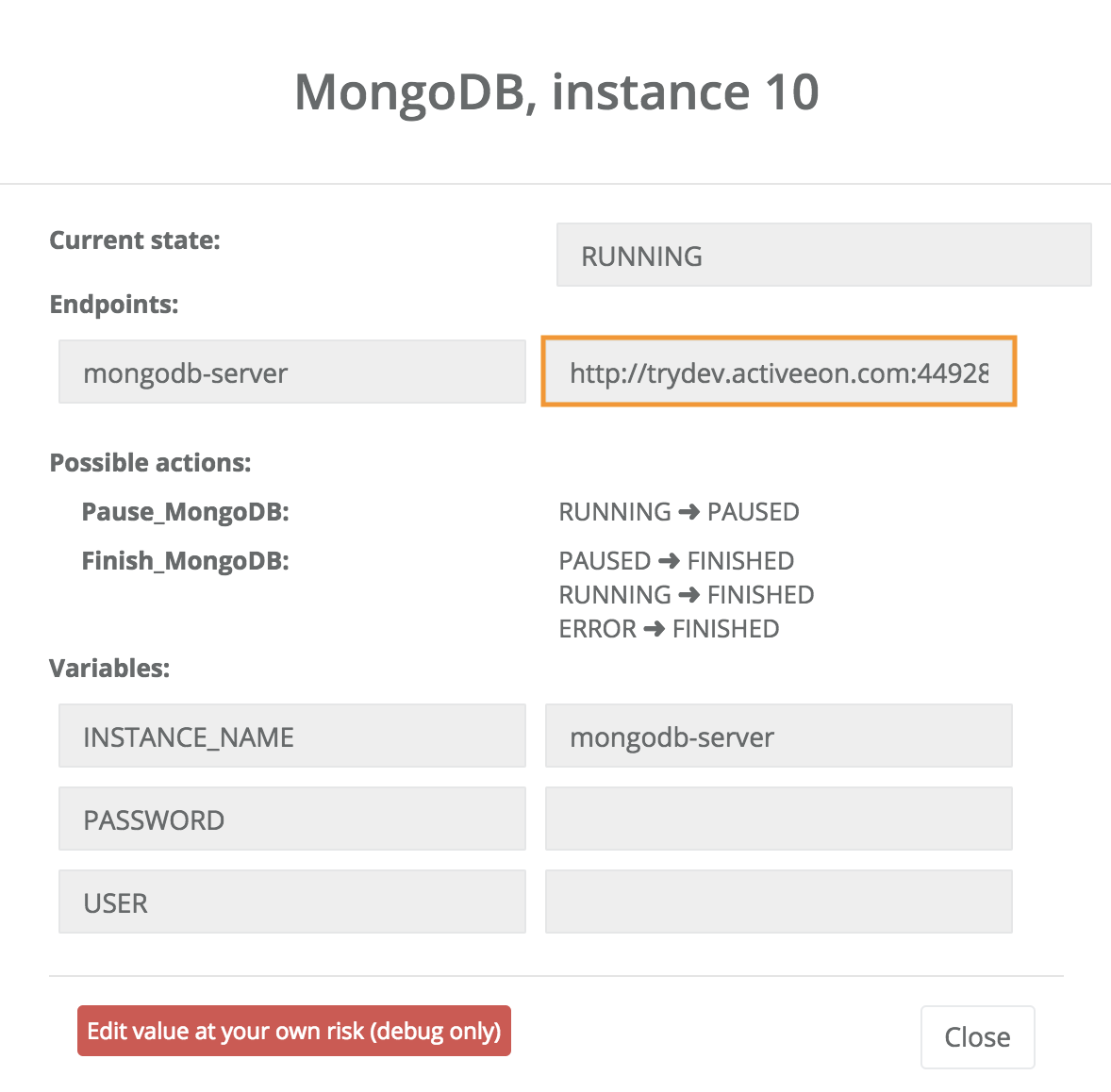
Two actions are possible at this step; pause or finish the instance.
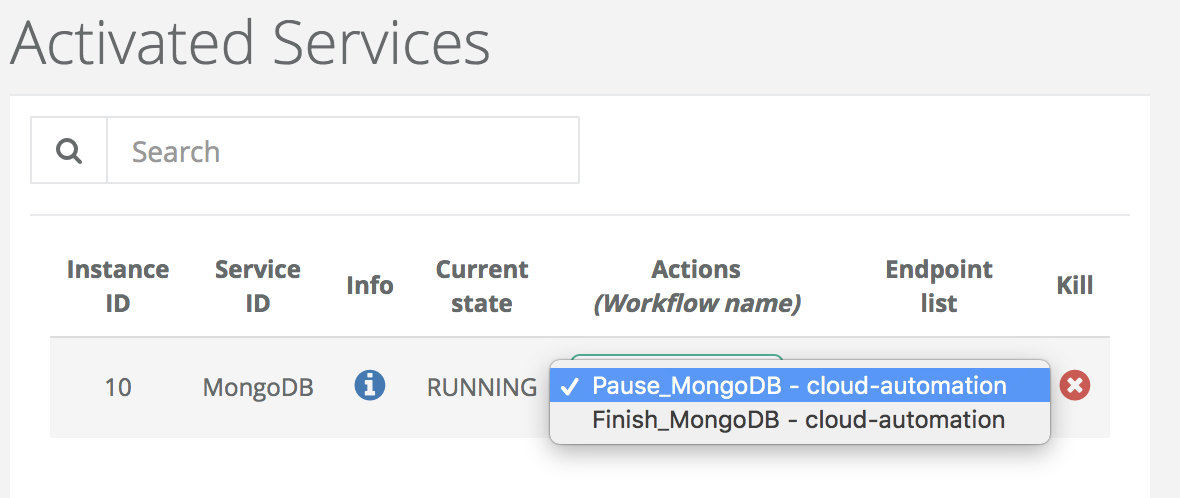
-
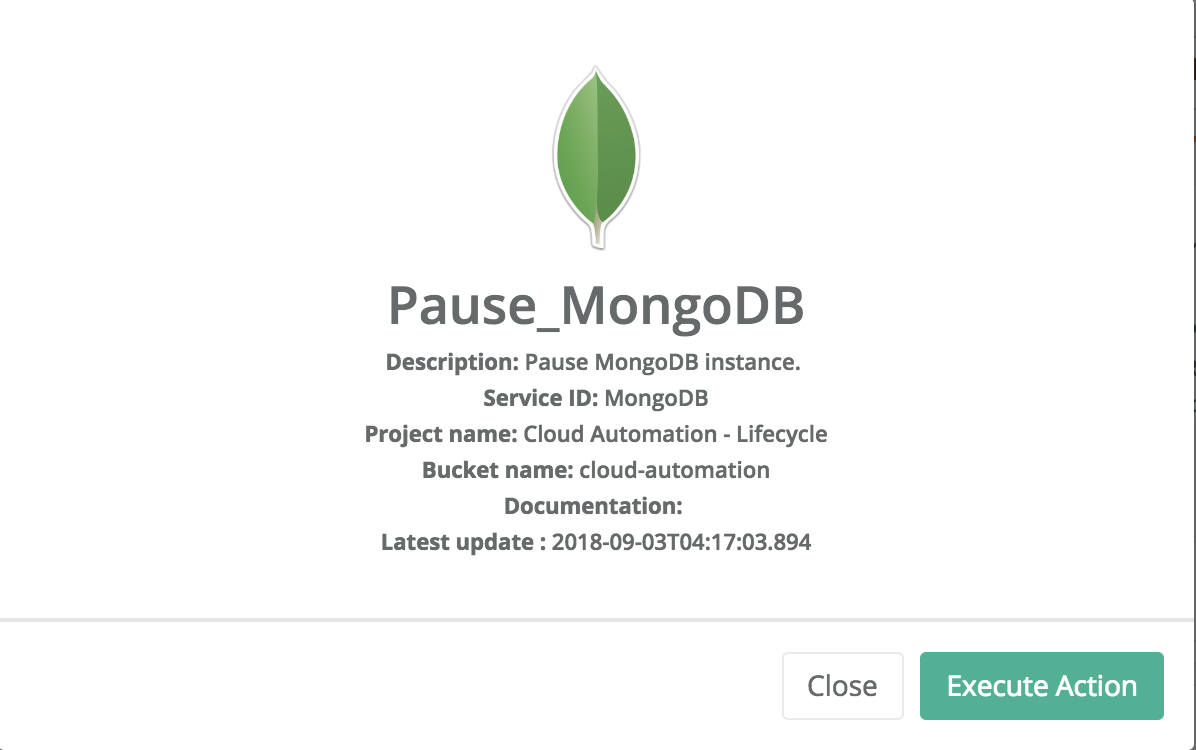
Pause MongoDB
The running instance can be paused by executing the pause action when the instance is in the RUNNING state. The pause action suspends only processes in the specified containers to release resources without losing data/container.
From the pause state, two actions are possible; resume or finish the instance.
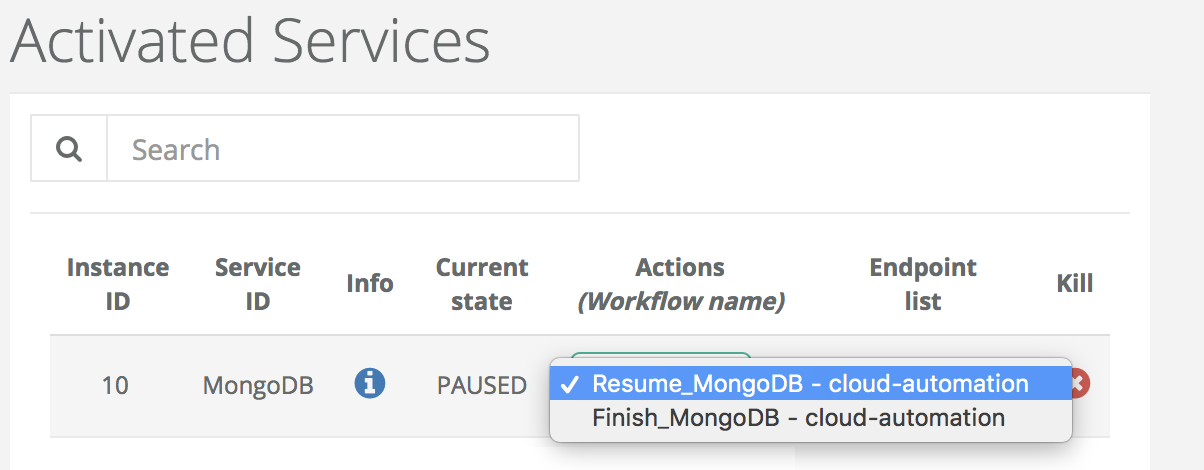
-
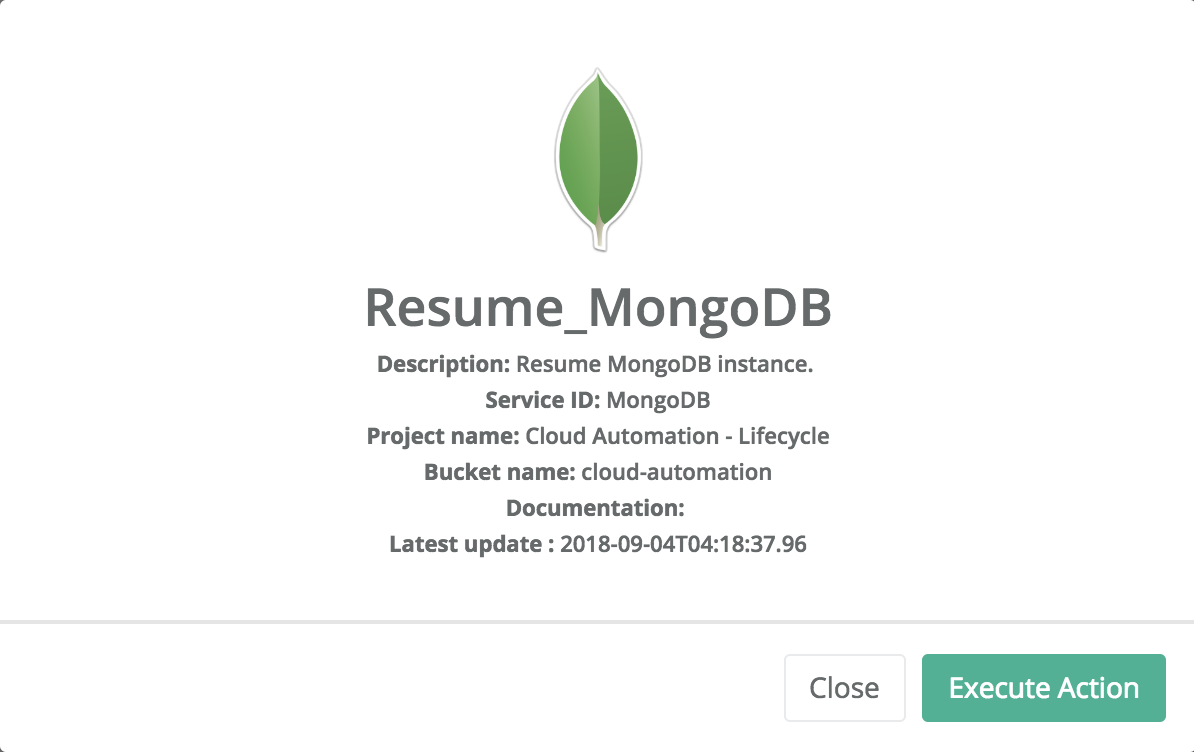
Resume MongoDB
The resume action allows to restart a paused instance while preserving previous state of the database. The instance is the RUNNING state.
-
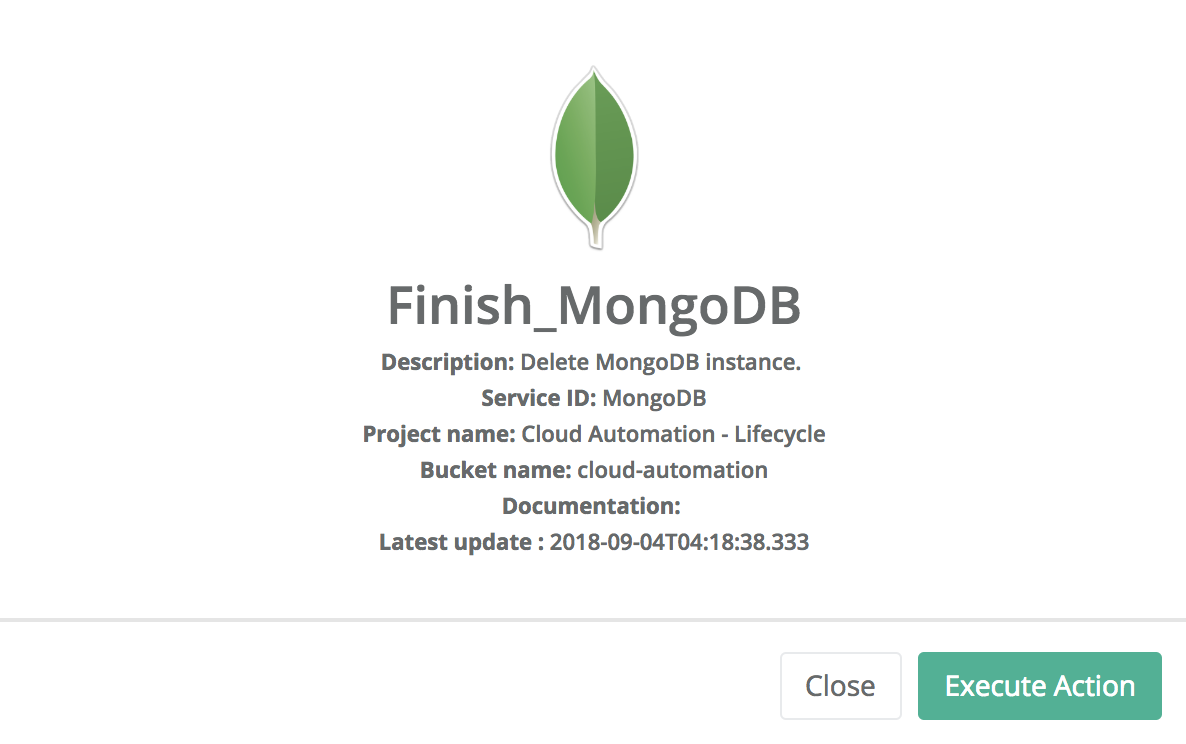
Finish MongoDB
When the user does not need this PSA service anymore, he can delete it to release resources using the finish action. This action can be applied when the instance is in the RUNNING or PAUSED state.
2.3.2. Spark/Hdfs
In this example, we show how to deploy through PSA Portal a HDFS and Spark platform that be used to run big data applications.
This deployment is done in several step
-
Reserve Node
This step allows to reserve the ressource to use to host the platform.

-
Deploy Swarm
After the node reservation, two actions are possible from the Actions tab. You an release the ressource or deploy swarm to have the network and cluster of docker containers.
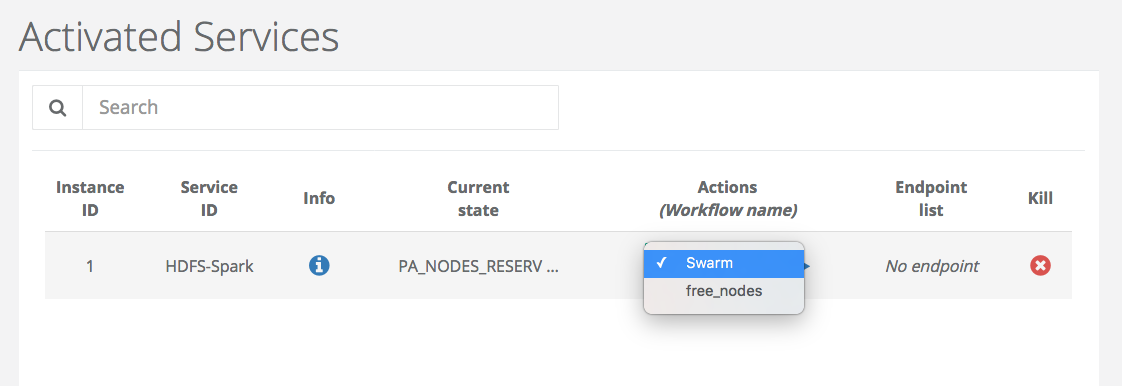
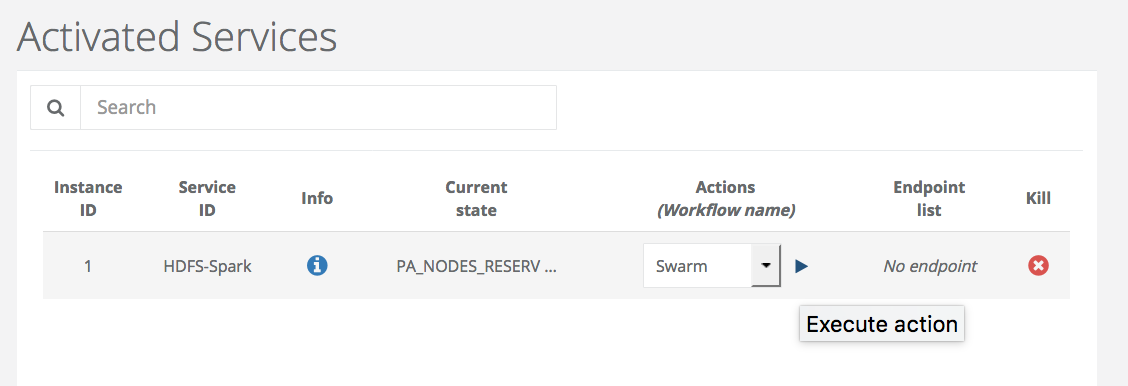
Choose swarm and click on execute Action to deploy it.
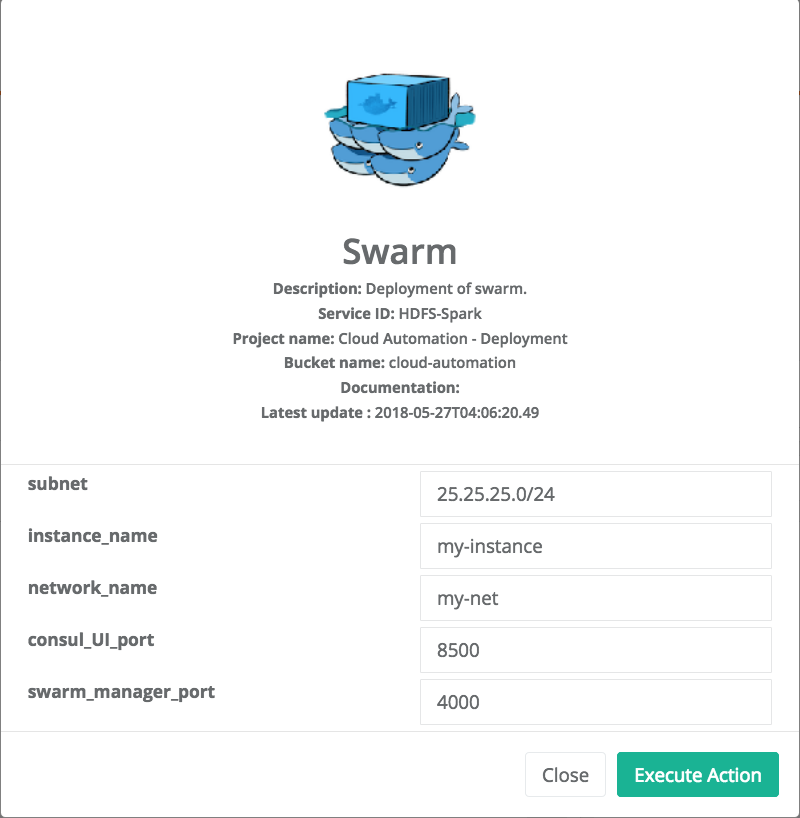
At the end, the State of the Service Instance is SWARM_DEPLOYED. Three Actions are available at this step and you can access to the cluster of docker containers through the endpoint (consul_UI).
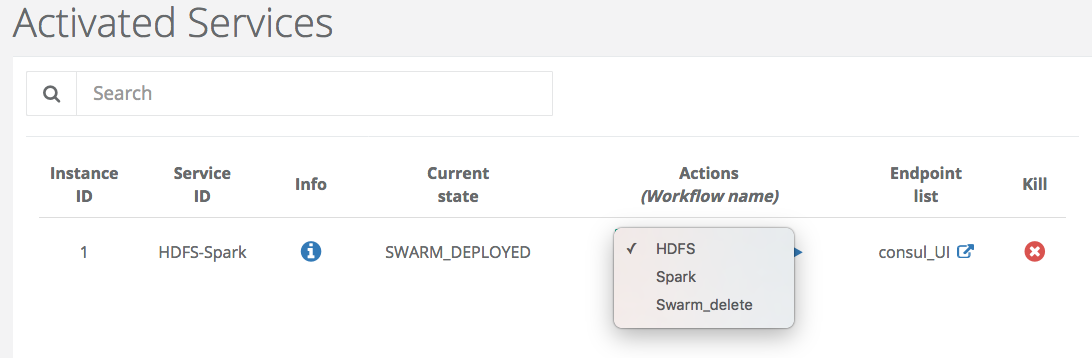
The next step is to deploy HDFS
-
Deploy HDFS
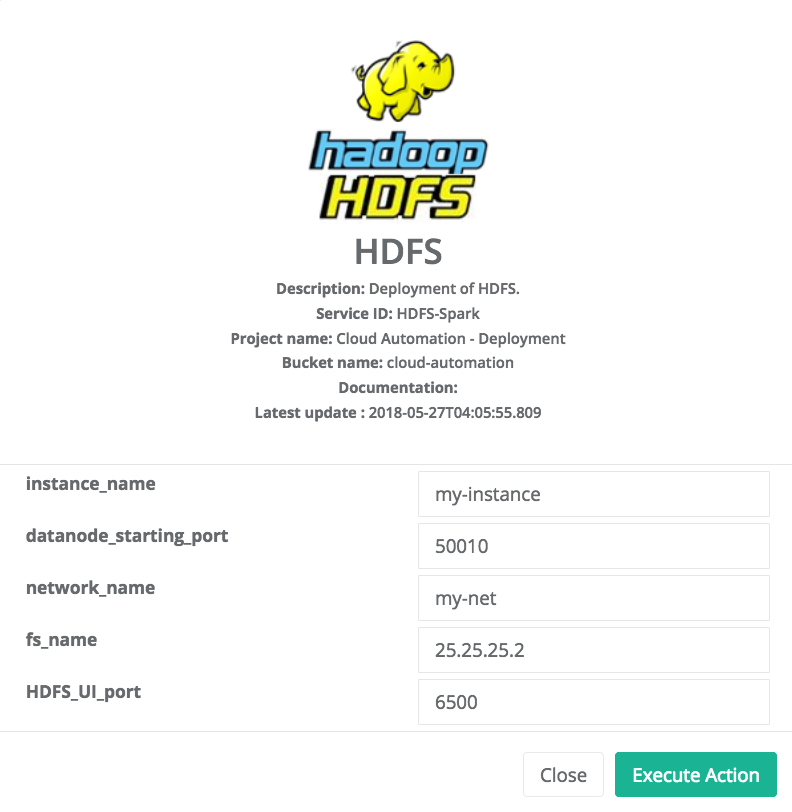
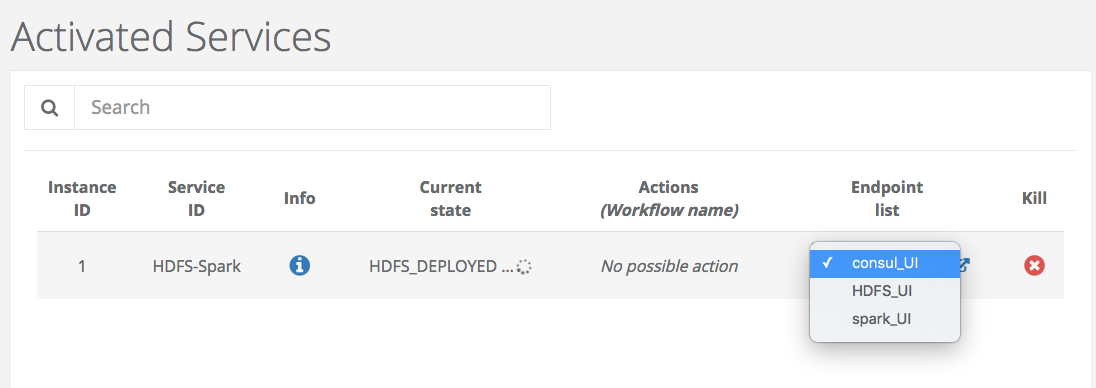
At the end, the State of the Service Instance is HDFS_DEPLOYED. Two Actions are available at this step.
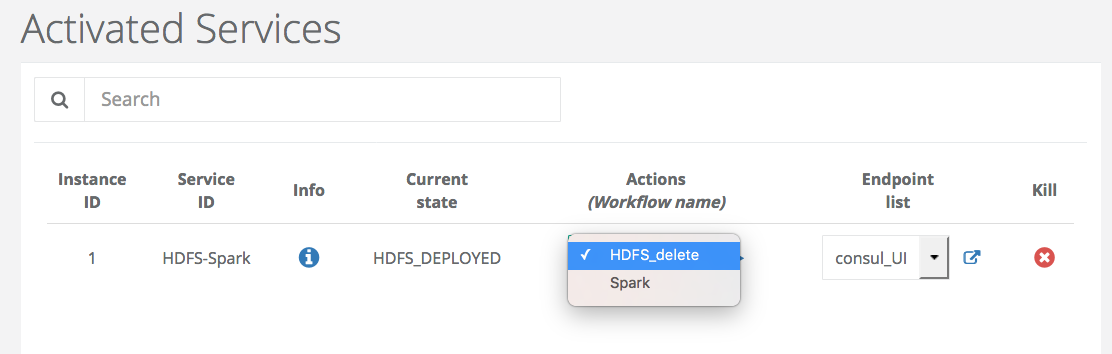
You can access to the HDFS interface or the cluster of docker containers through the endpoints (HDFS_UI, consul_UI).
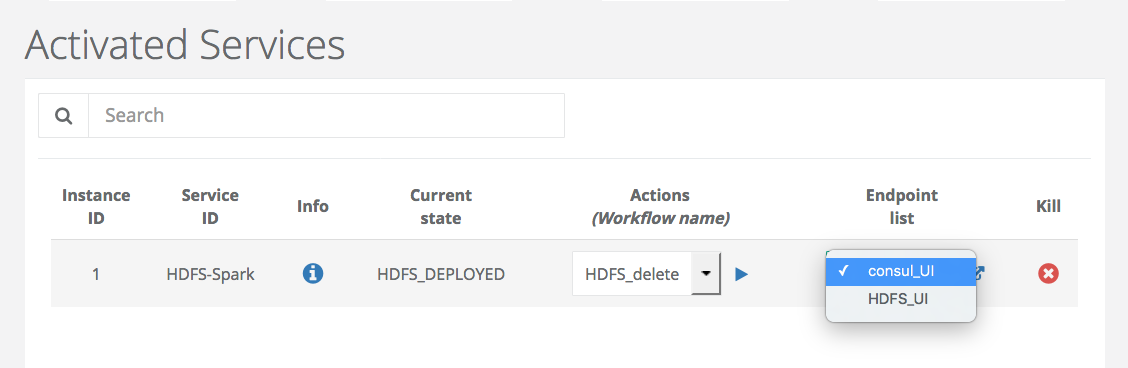
The next step is to deploy Spark.
-
Deploy Spark

You can access to HDFS or SPARK interfaces (HDFS_UI, SPARK_UI).
3. Reference
In this section, we provide a quick reference about how to configure and start some PSA services from our Catalog.
3.1. Cassandra
This service allows to deploy through ProActive Service Automation (PSA) Portal a Cassandra Database server. The service can be started using the following variables.
Variables:
Variable name |
Description |
Required? |
Type |
Default/Examples |
|
Service instance name |
Yes |
String |
|
|
Id of the service endpoint |
Yes |
String |
|
|
List of the environment variables. Each environment variable should be preceded by -e. |
No |
String |
e.g. |
| More details about the variable description can be found here. |
3.2. COCO Annotator
This service allows the deployment of an instance of COCO Annotator server through ProActive Service Automation (PSA) Portal. The service can be started using the following variables.
Variables:
Variable name |
Description |
Required? |
Type |
Default/Examples |
|
Id of the service endpoint. |
Yes |
String |
|
|
True if the protocol https is needed to start the COCO Annotator service. |
Yes |
Boolean |
|
|
The name of the service that will be deployed. |
Yes |
String |
|
|
True if a proxy is needed to protect the access to this model-service endpoint. |
Yes |
Boolean |
|
3.3. Docker
This service allows to deploy through ProActive Service Automation (PSA) Portal any docker image. It serves as a generic template that can be used to create and start any docker image ON DEMAND simply by providing the following variables.
Variables:
Variable name |
Description |
Required? |
Type |
Default/Examples |
|
Id of the service endpoint |
Yes |
String |
|
|
Docker image name. It can include a tag as well. |
Yes |
String |
e.g. |
|
The main image port. Please note that it will be forwarded to a random port that will be returned by this service. |
Yes |
Integer |
e.g. |
|
If you desire to stop this container and restart it later. |
Yes |
String |
e.g. |
|
options like environment variables, etc |
No |
String |
e.g. |
|
Password for the root user |
No |
String |
e.g. |
3.4. Elasticsearch
This service allows to deploy through ProActive Service Automation (PSA) Portal a Elasticsearch Database server. The service is started using the following variabless.
Variables:
Variable name |
Description |
Required? |
Type |
Default/Examples |
|
Service instance name |
Yes |
String |
|
|
Id of the service endpoint |
Yes |
String |
|
| More details about the variable description can be found here. |
3.5. Jupyterlab
This service allows to deploy through ProActive Service Automation (PSA) Portal an instance of JupyterLab server (https://jupyterlab.readthedocs.io/en/stable/). The service is started using the following variables.
Variables:
Variable name |
Description |
Required? |
Type |
Default/Examples |
|
Service instance name |
Yes |
String |
|
|
Protects the JupyterLab service with a password. |
No |
String |
|
|
Id of the service endpoint |
Yes |
String |
|
|
Allows access to the endpoint through Service Automation Http(s) Proxy |
Yes |
Boolean |
|
|
Start JupyterLab in https mode (generates a self-signed certificate or use |
Yes |
Boolean |
|
|
Controls the port used to start the JupyterLab server. |
Yes |
Integer |
|
|
Container engine |
Yes |
Choice(docker,singularity) |
|
|
Location of the singularity image on the node file system (this path will be used to either store the singularity image or the image will be directly used if the file is present) |
Yes |
String |
|
|
Pull and build the singularity image if the sif file is not present |
Yes |
Boolean |
|
|
Name of the Native Scheduler node source to use (if the service must be deployed inside a cluster such as SLURM, LSF, etc) |
No |
String |
|
|
Parameters given to the native scheduler (Slurm, LSF, etc) while requesting a ProActive node used to deploy the PSA service. |
No |
String |
|
3.6. Kafka
This service allows to deploy through ProActive Service Automation (PSA) Portal an instance of Apache Kafka publish/subscribe system (https://kafka.apache.org/). The deployed instance consists in a single publish/subscribe broker that is based on Apache Zookeeper coordination server. The service is started using the following variables.
Variables:
Variable name |
Description |
Required? |
Type |
Default/Examples |
|
Service instance name |
Yes |
String |
|
|
Id of the service endpoint |
Yes |
String |
|
|
Name of the Zookeeper instance that coordinates the storm deployment. |
Yes |
String |
|
|
Zookeeper service identifier needed to start this service if it does not already exist. |
Yes |
String |
|
| More details about the variable description can be found here. |
3.7. MongoDB
This service allows to deploy through ProActive Service Automation (PSA) Portal a MongoDB Database server. The service can be started using the following variables.
Variables:
Variable name |
Description |
Required? |
Type |
Default/Examples |
|
Service instance name |
Yes |
String |
|
|
Id of the service endpoint |
Yes |
String |
|
|
Username for the root user |
No |
String |
e.g. |
|
Password for the root user |
No |
String |
e.g. |
|
Controls the port used to start the JupyterLab server. |
Yes |
Integer |
|
|
Container engine |
Yes |
Choice(docker,singularity) |
|
|
Docker image used to start MongoDB |
Yes |
String |
|
|
Location of the singularity image on the node file system (this path will be used to either store the singularity image or the image will be directly used if the file is present) |
Yes |
String |
|
|
Pull and build the singularity image if the sif file is not present |
Yes |
Boolean |
|
|
When using singularity, this folder will be used to store the database data |
Yes |
String |
|
|
Name of the Native Scheduler node source to use (if the service must be deployed inside a cluster such as SLURM, LSF, etc) |
No |
String |
|
|
Parameters given to the native scheduler (Slurm, LSF, etc) while requesting a ProActive node used to deploy the PSA service. |
No |
String |
|
Note that the USER and PASSWORD variables are used in junction. They should be either both entered or both blank.
More details about the variable description can be found here.
|
3.8. MySQL
This service allows to deploy through ProActive Service Automation (PSA) Portal a MySQL Database server. The service can be started using the following variables.
Variables:
Variable name |
Description |
Required? |
Type |
Default/Examples |
|
Service instance name |
Yes |
String |
|
|
Id of the service endpoint |
Yes |
String |
|
|
Name of a database to be created on start |
No |
String |
e.g. |
|
Username for the root user |
No |
String |
e.g. |
|
Password for the root user |
No |
String |
e.g. |
Note that the USER and PASSWORD variables are used in junction. They should be either both entered or both blank.
In addition, if DATABASE is assigned a value, then the defined USER will be granted superuser access (corresponding to GRANT ALL) to this database.
More details about the variable description can be found here.
|
3.9. OpenRefine
This service allows the deployment of an OpenRefine server instance through ProActive Service Automation (PSA) Portal. The service can be started using the following variables.
Variables:
Variable name |
Description |
Required? |
Type |
Default/Examples |
|
Id of the service endpoint. |
Yes |
String |
|
|
True if the protocol https is needed to start OpenRefine. |
Yes |
Boolean |
|
|
The name of the service that will be deployed. |
Yes |
String |
|
|
True if a proxy is needed to protect the access to this model-service endpoint. |
Yes |
Boolean |
|
3.10. PostgreSQL
This service allows to deploy through ProActive Service Automation (PSA) Portal a PostgreSQL Database server. The service can be started using the following variables.
Variables:
Variable name |
Description |
Required? |
Type |
Default/Examples |
|
Service instance name |
Yes |
String |
|
|
Id of the service endpoint |
Yes |
String |
|
|
Name of a database to be created on start |
No |
String |
e.g. |
|
Username for the root user. change it if you want a different root username . Default "postgres" is used if left empty. |
No |
String |
e.g. |
|
Password for the root user |
Yes |
String |
e.g. |
| More details about the variable description can be found here. |
3.11. Greenplum
This service deploys through ProActive Service Automation (PSA) Portal a Greenplum Database server. The service takes as input the following variables.
Variables:
Variable name |
Description |
Required? |
Type |
Default/Examples |
|
Service instance name |
Yes |
String |
|
|
Id of the service endpoint |
Yes |
String |
|
|
Name of a database to be created on start. Change it if you want a different database . Default "testdb" is used if left empty. |
No |
String |
e.g. |
|
Username for the SUPERUSER. Change it if you want a different username . Default "tester" is used if left empty. |
No |
String |
e.g. |
|
Password for the SUPERUSER. change it if you want a different password . Default "pivotal" is used if left empty. |
No |
String |
e.g. |
| More details about the variable description can be found here. |
3.12. SSH
This service deploys the WeTTy software through ProActive Service Automation (PSA) portal. It allows the users to open an SSH terminal in their Web browsers. The service requires the following variables as input:
Variables:
Variable name |
Description |
Required? |
Type |
Default/Examples |
|
Service instance name |
Yes |
String |
|
|
SSH target host, among the list of hosts managed by ProActive Resource Manager |
Yes |
String |
|
|
Port used by SSH in the TARGET_HOST |
Yes |
Integer |
|
|
Whether the service is accessed via ProActive proxy (for restricted access control). |
Yes |
Boolean |
|
3.13. Storm
This service allows to deploy through ProActive Service Automation (PSA) Portal a cluster of Apache Storm stream processing system (https://storm.apache.org). The service is started using the following variables.
Variables:
Variable name |
Description |
Required? |
Type |
Default/Examples |
|
Service instance name |
Yes |
String |
|
|
Id of the service endpoint |
Yes |
String |
|
|
Number of worker nodes |
Yes |
Integer |
|
|
Name of the Zookeeper instance that coordinates the storm deployment. |
Yes |
String |
|
|
Zookeeper service identifier needed to start this service if it does not already exist. |
Yes |
String |
|
| More details about the variable description can be found here. |
3.14. Tensorboard
This service allows to deploy through ProActive Service Automation (PSA) Portal an instance of Tensorboard server (https://www.tensorflow.org/tensorboard). The service is started using the following variable.
Variables:
Variable name |
Description |
Required? |
Type |
Default/Examples |
|
Service instance name |
Yes |
String |
|
|
Id of the service endpoint |
Yes |
String |
|
|
Allows access to the endpoint through Service Automation Http(s) Proxy |
Yes |
Boolean |
|
|
Controls the port used to start the Tensorboard server. |
Yes |
Integer |
|
|
Path on the ProActive node file system used to store Tensorboard data |
Yes |
String |
|
|
Container engine |
Yes |
Choice(docker,singularity) |
|
|
Docker image used to start Tensorboard |
Yes |
String |
|
|
Location of the singularity image on the node file system (this path will be used to either store the singularity image or the image will be directly used if the file is present) |
Yes |
String |
|
|
Pull and build the singularity image if the sif file is not present |
Yes |
Boolean |
|
|
Name of the Native Scheduler node source to use (if the service must be deployed inside a cluster such as SLURM, LSF, etc) |
No |
String |
|
|
Parameters given to the native scheduler (Slurm, LSF, etc) while requesting a ProActive node used to deploy the PSA service. |
No |
String |
|
3.15. Visdom
This service allows to deploy through ProActive Service Automation (PSA) Portal an instance of Visdom server (https://github.com/facebookresearch/visdom). The service is started using the following variable.
Variables:
Variable name |
Description |
Required? |
Type |
Default/Examples |
|
Service instance name |
Yes |
String |
|
|
Id of the service endpoint |
Yes |
String |
|
|
Allows access to the endpoint through Service Automation Http(s) Proxy |
Yes |
Boolean |
|
|
Controls the port used to start the Visdom server. |
Yes |
Integer |
|
|
Enable Visdom authentication |
Yes |
Boolean |
|
|
Optional username used to authenticate with Visdom |
No |
String |
|
|
Optional password used to authenticate with Visdom |
No |
String |
|
|
Container engine |
Yes |
Choice(docker,singularity) |
|
|
Docker image used to start Visdom |
Yes |
String |
|
|
Location of the singularity image on the node file system (this path will be used to either store the singularity image or the image will be directly used if the file is present) |
Yes |
String |
|
|
Pull and build the singularity image if the sif file is not present |
Yes |
Boolean |
|
|
Name of the Native Scheduler node source to use (if the service must be deployed inside a cluster such as SLURM, LSF, etc) |
No |
String |
|
|
Parameters given to the native scheduler (Slurm, LSF, etc) while requesting a ProActive node used to deploy the PSA service. |
No |
String |
|
3.16. Zookeeper
This service allows to deploy through ProActive Service Automation (PSA) Portal an instance of Apache Zookeeper coordination server (https://zookeeper.apache.org/). The deployed instance consists in a single Zookeeper broker. The service is started using the following variable.
Variables:
Variable name |
Description |
Required? |
Type |
Default/Examples |
|
Service instance name |
Yes |
String |
|
|
Id of the service endpoint |
Yes |
String |
|
| More details about the variable description can be found here. |
Legal notice
Activeeon SAS, © 2007-2019. All Rights Reserved.
For more information, please contact contact@activeeon.com.